 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocVCE: Diffusion-based Visual Counterfactual Explanations for Document Image Classification
Aug 06, 2025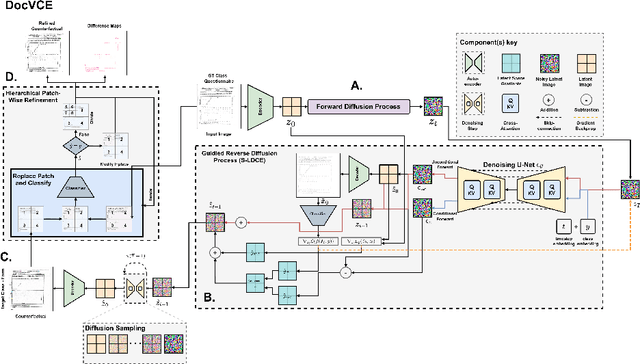
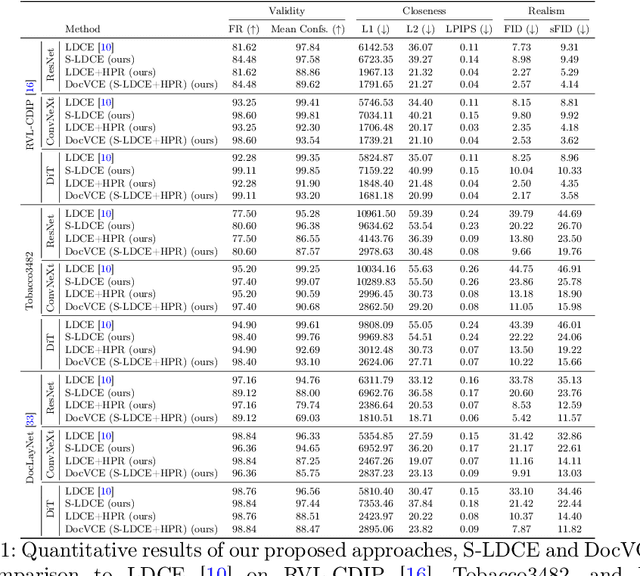


As black-box AI-driven decision-making systems become increasingly widespread in modern document processing workflows, improving their transparency and reliability has become critical, especially in high-stakes applications where biases or spurious correlations in decision-making could lead to serious consequences. One vital component often found in such document processing workflows is document image classification, which, despite its widespread use, remains difficult to explain. While some recent works have attempted to explain the decisions of document image classification models through feature-importance maps, these maps are often difficult to interpret and fail to provide insights into the global features learned by the model. In this paper, we aim to bridge this research gap by introducing generative document counterfactuals that provide meaningful insights into the model's decision-making through actionable explanations. In particular, we propose DocVCE, a novel approach that leverages latent diffusion models in combination with classifier guidance to first generate plausible in-distribution visual counterfactual explanations, and then performs hierarchical patch-wise refinement to search for a refined counterfactual that is closest to the target factual image. We demonstrate the effectiveness of our approach through a rigorous qualitative and quantitative assessment on 3 different document classification datasets -- RVL-CDIP, Tobacco3482, and DocLayNet -- and 3 different models -- ResNet, ConvNeXt, and DiT -- using well-established evaluation criteria such as validity, closeness, and realism. To the best of the authors' knowledge, this is the first work to explore generative counterfactual explanations in document image analysis.
WordVIS: A Color Worth A Thousand Words
Dec 13, 2024



Document classification is considered a critical element in automated document processing systems. In recent years multi-modal approaches have become increasingly popular for document classification. Despite their improvements, these approaches are underutilized in the industry due to their requirement for a tremendous volume of training data and extensive computational power. In this paper, we attempt to address these issues by embedding textual features directly into the visual space, allowing lightweight image-based classifiers to achieve state-of-the-art results using small-scale datasets in document classification. To evaluate the efficacy of the visual features generated from our approach on limited data, we tested on the standard dataset Tobacco-3482. Our experiments show a tremendous improvement in image-based classifiers, achieving an improvement of 4.64% using ResNet50 with no document pre-training. It also sets a new record for the best accuracy of the Tobacco-3482 dataset with a score of 91.14% using the image-based DocXClassifier with no document pre-training. The simplicity of the approach, its resource requirements, and subsequent results provide a good prospect for its use in industrial use cases.
Latent Diffusion for Guided Document Table Generation
Aug 19, 2024Obtaining annotated table structure data for complex tables is a challenging task due to the inherent diversity and complexity of real-world document layouts. The scarcity of publicly available datasets with comprehensive annotations for intricate table structures hinders the development and evaluation of models designed for such scenarios. This research paper introduces a novel approach for generating annotated images for table structure by leveraging conditioned mask images of rows and columns through the application of latent diffusion models. The proposed method aims to enhance the quality of synthetic data used for training object detection models. Specifically, the study employs a conditioning mechanism to guide the generation of complex document table images, ensuring a realistic representation of table layouts. To evaluate the effectiveness of the generated data, we employ the popular YOLOv5 object detection model for training. The generated table images serve as valuable training samples, enriching the dataset with diverse table structures. The model is subsequently tested on the challenging pubtables-1m testset, a benchmark for table structure recognition in complex document layouts. Experimental results demonstrate that the introduced approach significantly improves the quality of synthetic data for training, leading to YOLOv5 models with enhanced performance. The mean Average Precision (mAP) values obtained on the pubtables-1m testset showcase results closely aligned with state-of-the-art methods. Furthermore, low FID results obtained on the synthetic data further validate the efficacy of the proposed methodology in generating annotated images for table structure.
StylusAI: Stylistic Adaptation for Robust German Handwritten Text Generation
Jul 22, 2024



In this study, we introduce StylusAI, a novel architecture leveraging diffusion models in the domain of handwriting style generation. StylusAI is specifically designed to adapt and integrate the stylistic nuances of one language's handwriting into another, particularly focusing on blending English handwriting styles into the context of the German writing system. This approach enables the generation of German text in English handwriting styles and German handwriting styles into English, enriching machine-generated handwriting diversity while ensuring that the generated text remains legible across both languages. To support the development and evaluation of StylusAI, we present the \lq{Deutscher Handschriften-Datensatz}\rq~(DHSD), a comprehensive dataset encompassing 37 distinct handwriting styles within the German language. This dataset provides a fundamental resource for training and benchmarking in the realm of handwritten text generation. Our results demonstrate that StylusAI not only introduces a new method for style adaptation in handwritten text generation but also surpasses existing models in generating handwriting samples that improve both text quality and stylistic fidelity, evidenced by its performance on the IAM database and our newly proposed DHSD. Thus, StylusAI represents a significant advancement in the field of handwriting style generation, offering promising avenues for future research and applications in cross-linguistic style adaptation for languages with similar scripts.
DocXplain: A Novel Model-Agnostic Explainability Method for Document Image Classification
Jul 04, 2024Deep learning (DL) has revolutionized the field of document image analysis, showcasing superhuman performance across a diverse set of tasks. However, the inherent black-box nature of deep learning models still presents a significant challenge to their safe and robust deployment in industry. Regrettably, while a plethora of research has been dedicated in recent years to the development of DL-powered document analysis systems, research addressing their transparency aspects has been relatively scarce. In this paper, we aim to bridge this research gap by introducing DocXplain, a novel model-agnostic explainability method specifically designed for generating high interpretability feature attribution maps for the task of document image classification. In particular, our approach involves independently segmenting the foreground and background features of the documents into different document elements and then ablating these elements to assign feature importance. We extensively evaluate our proposed approach in the context of document image classification, utilizing 4 different evaluation metrics, 2 widely recognized document benchmark datasets, and 10 state-of-the-art document image classification models. By conducting a thorough quantitative and qualitative analysis against 9 existing state-of-the-art attribution methods, we demonstrate the superiority of our approach in terms of both faithfulness and interpretability. To the best of the authors' knowledge, this work presents the first model-agnostic attribution-based explainability method specifically tailored for document images. We anticipate that our work will significantly contribute to advancing research on transparency, fairness, and robustness of document image classification models.
PrIeD-KIE: Towards Privacy Preserved Document Key Information Extraction
Oct 05, 2023

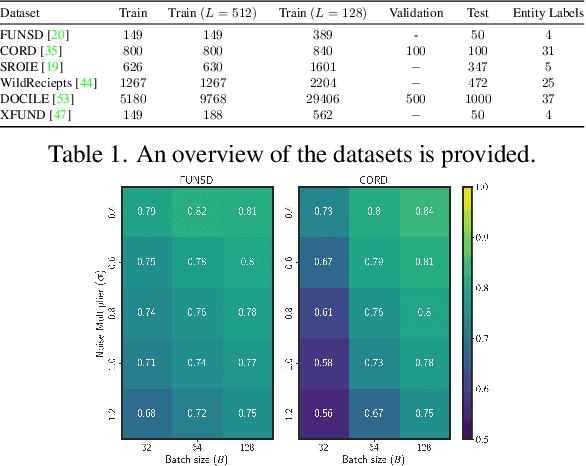

In this paper, we introduce strategies for developing private Key Information Extraction (KIE) systems by leveraging large pretrained document foundation models in conjunction with differential privacy (DP), federated learning (FL), and Differentially Private Federated Learning (DP-FL). Through extensive experimentation on six benchmark datasets (FUNSD, CORD, SROIE, WildReceipts, XFUND, and DOCILE), we demonstrate that large document foundation models can be effectively fine-tuned for the KIE task under private settings to achieve adequate performance while maintaining strong privacy guarantees. Moreover, by thoroughly analyzing the impact of various training and model parameters on model performance, we propose simple yet effective guidelines for achieving an optimal privacy-utility trade-off for the KIE task under global DP. Finally, we introduce FeAm-DP, a novel DP-FL algorithm that enables efficiently upscaling global DP from a standalone context to a multi-client federated environment. We conduct a comprehensive evaluation of the algorithm across various client and privacy settings, and demonstrate its capability to achieve comparable performance and privacy guarantees to standalone DP, even when accommodating an increasing number of participating clients. Overall, our study offers valuable insights into the development of private KIE systems, and highlights the potential of document foundation models for privacy-preserved Document AI applications. To the best of authors' knowledge, this is the first work that explores privacy preserved document KIE using document foundation models.