 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWordVIS: A Color Worth A Thousand Words
Dec 13, 2024



Document classification is considered a critical element in automated document processing systems. In recent years multi-modal approaches have become increasingly popular for document classification. Despite their improvements, these approaches are underutilized in the industry due to their requirement for a tremendous volume of training data and extensive computational power. In this paper, we attempt to address these issues by embedding textual features directly into the visual space, allowing lightweight image-based classifiers to achieve state-of-the-art results using small-scale datasets in document classification. To evaluate the efficacy of the visual features generated from our approach on limited data, we tested on the standard dataset Tobacco-3482. Our experiments show a tremendous improvement in image-based classifiers, achieving an improvement of 4.64% using ResNet50 with no document pre-training. It also sets a new record for the best accuracy of the Tobacco-3482 dataset with a score of 91.14% using the image-based DocXClassifier with no document pre-training. The simplicity of the approach, its resource requirements, and subsequent results provide a good prospect for its use in industrial use cases.
TabAug: Data Driven Augmentation for Enhanced Table Structure Recognition
May 15, 2021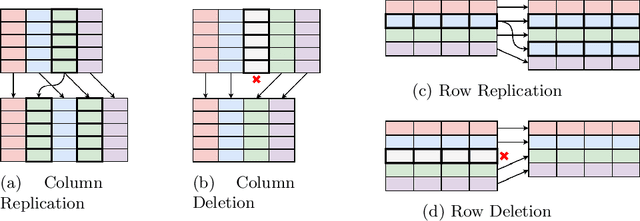
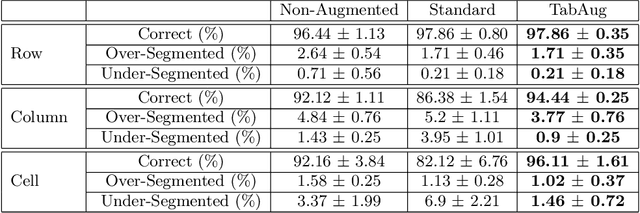
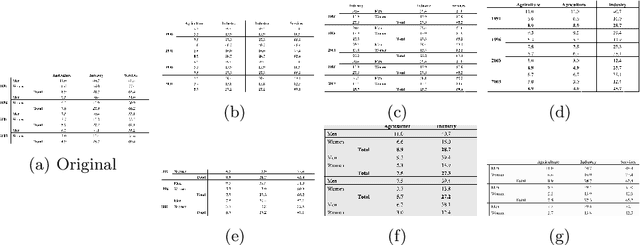
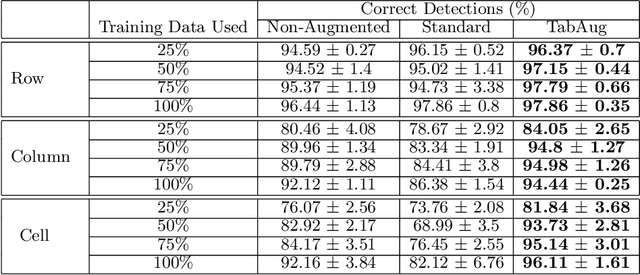
Table Structure Recognition is an essential part of end-to-end tabular data extraction in document images. The recent success of deep learning model architectures in computer vision remains to be non-reflective in table structure recognition, largely because extensive datasets for this domain are still unavailable while labeling new data is expensive and time-consuming. Traditionally, in computer vision, these challenges are addressed by standard augmentation techniques that are based on image transformations like color jittering and random cropping. As demonstrated by our experiments, these techniques are not effective for the task of table structure recognition. In this paper, we propose TabAug, a re-imagined Data Augmentation technique that produces structural changes in table images through replication and deletion of rows and columns. It also consists of a data-driven probabilistic model that allows control over the augmentation process. To demonstrate the efficacy of our approach, we perform experimentation on ICDAR 2013 dataset where our approach shows consistent improvements in all aspects of the evaluation metrics, with cell-level correct detections improving from 92.16% to 96.11% over the baseline.