 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Disease Detection from Social Media Text via Self-Augmentation and Contrastive Learning
Apr 30, 2024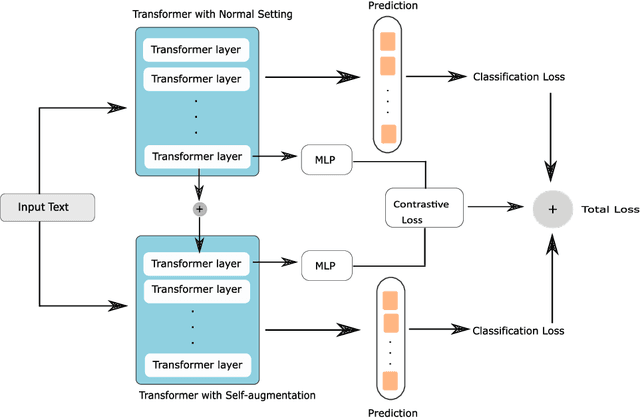
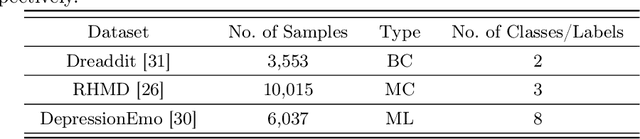
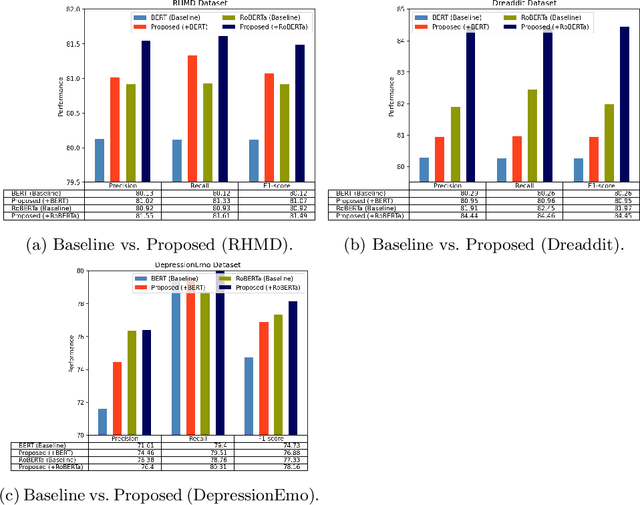
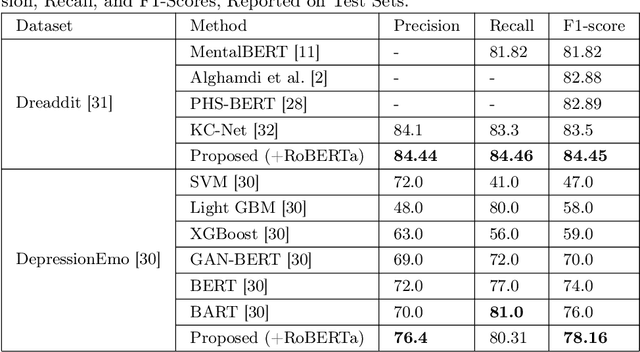
Detecting diseases from social media has diverse applications, such as public health monitoring and disease spread detection. While language models (LMs) have shown promising performance in this domain, there remains ongoing research aimed at refining their discriminating representations. In this paper, we propose a novel method that integrates Contrastive Learning (CL) with language modeling to address this challenge. Our approach introduces a self-augmentation method, wherein hidden representations of the model are augmented with their own representations. This method comprises two branches: the first branch, a traditional LM, learns features specific to the given data, while the second branch incorporates augmented representations from the first branch to encourage generalization. CL further refines these representations by pulling pairs of original and augmented versions closer while pushing other samples away. We evaluate our method on three NLP datasets encompassing binary, multi-label, and multi-class classification tasks involving social media posts related to various diseases. Our approach demonstrates notable improvements over traditional fine-tuning methods, achieving up to a 2.48% increase in F1-score compared to baseline approaches and a 2.1% enhancement over state-of-the-art methods.
Medi-CAT: Contrastive Adversarial Training for Medical Image Classification
Oct 31, 2023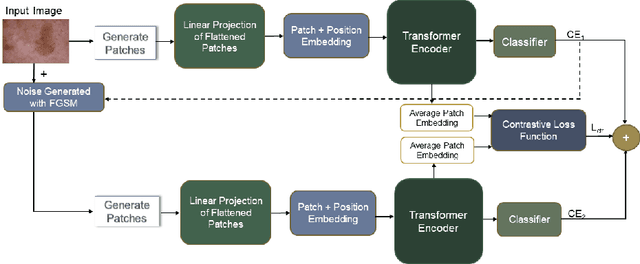
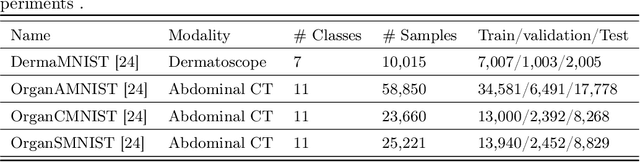
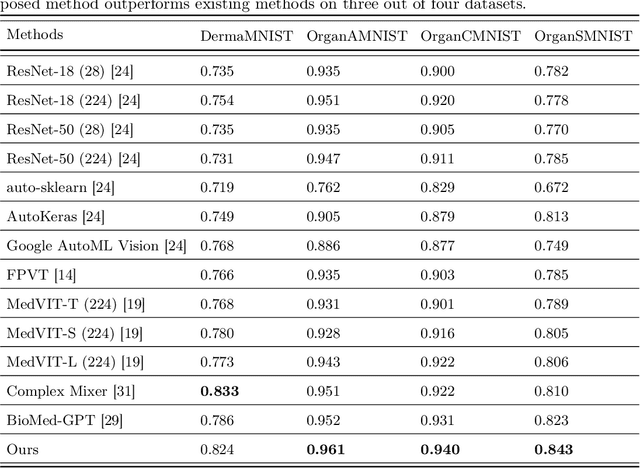
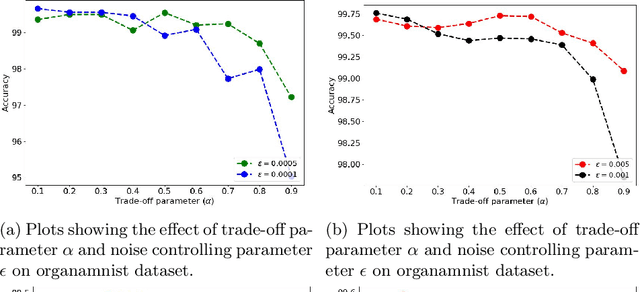
There are not many large medical image datasets available. For these datasets, too small deep learning models can't learn useful features, so they don't work well due to underfitting, and too big models tend to overfit the limited data. As a result, there is a compromise between the two issues. This paper proposes a training strategy Medi-CAT to overcome the underfitting and overfitting phenomena in medical imaging datasets. Specifically, the proposed training methodology employs large pre-trained vision transformers to overcome underfitting and adversarial and contrastive learning techniques to prevent overfitting. The proposed method is trained and evaluated on four medical image classification datasets from the MedMNIST collection. Our experimental results indicate that the proposed approach improves the accuracy up to 2% on three benchmark datasets compared to well-known approaches, whereas it increases the performance up to 4.1% over the baseline methods.
A Unique Training Strategy to Enhance Language Models Capabilities for Health Mention Detection from Social Media Content
Oct 29, 2023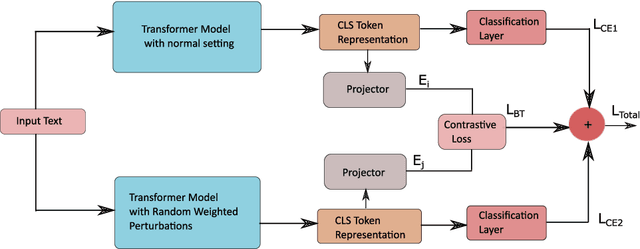
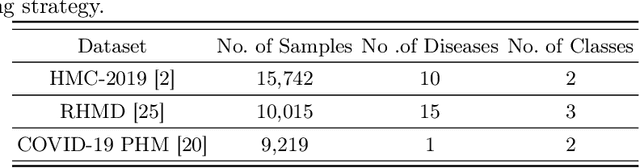
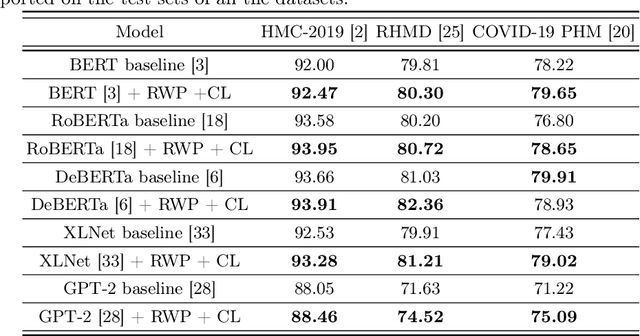
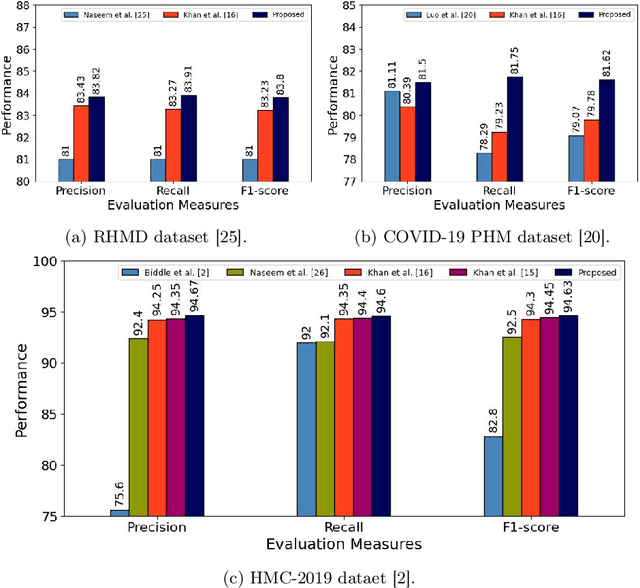
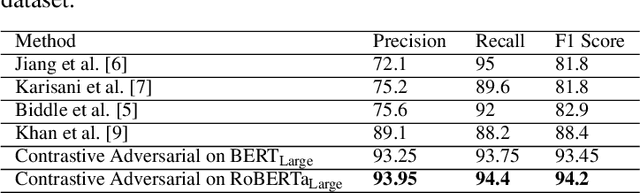
An ever-increasing amount of social media content requires advanced AI-based computer programs capable of extracting useful information. Specifically, the extraction of health-related content from social media is useful for the development of diverse types of applications including disease spread, mortality rate prediction, and finding the impact of diverse types of drugs on diverse types of diseases. Language models are competent in extracting the syntactic and semantics of text. However, they face a hard time extracting similar patterns from social media texts. The primary reason for this shortfall lies in the non-standardized writing style commonly employed by social media users. Following the need for an optimal language model competent in extracting useful patterns from social media text, the key goal of this paper is to train language models in such a way that they learn to derive generalized patterns. The key goal is achieved through the incorporation of random weighted perturbation and contrastive learning strategies. On top of a unique training strategy, a meta predictor is proposed that reaps the benefits of 5 different language models for discriminating posts of social media text into non-health and health-related classes. Comprehensive experimentation across 3 public benchmark datasets reveals that the proposed training strategy improves the performance of the language models up to 3.87%, in terms of F1-score, as compared to their performance with traditional training. Furthermore, the proposed meta predictor outperforms existing health mention classification predictors across all 3 benchmark datasets.
A Novel Approach to Train Diverse Types of Language Models for Health Mention Classification of Tweets
Apr 13, 2022
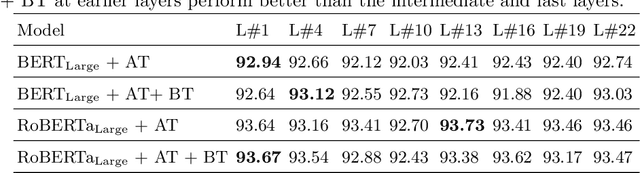


Health mention classification deals with the disease detection in a given text containing disease words. However, non-health and figurative use of disease words adds challenges to the task. Recently, adversarial training acting as a means of regularization has gained popularity in many NLP tasks. In this paper, we propose a novel approach to train language models for health mention classification of tweets that involves adversarial training. We generate adversarial examples by adding perturbation to the representations of transformer models for tweet examples at various levels using Gaussian noise. Further, we employ contrastive loss as an additional objective function. We evaluate the proposed method on the PHM2017 dataset extended version. Results show that our proposed approach improves the performance of classifier significantly over the baseline methods. Moreover, our analysis shows that adding noise at earlier layers improves models' performance whereas adding noise at intermediate layers deteriorates models' performance. Finally, adding noise towards the final layers performs better than the middle layers noise addition.
Improving Health Mentioning Classification of Tweets using Contrastive Adversarial Training
Mar 03, 2022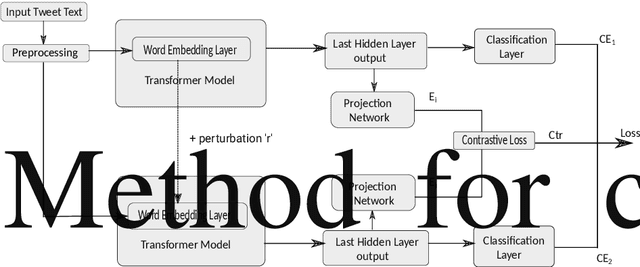

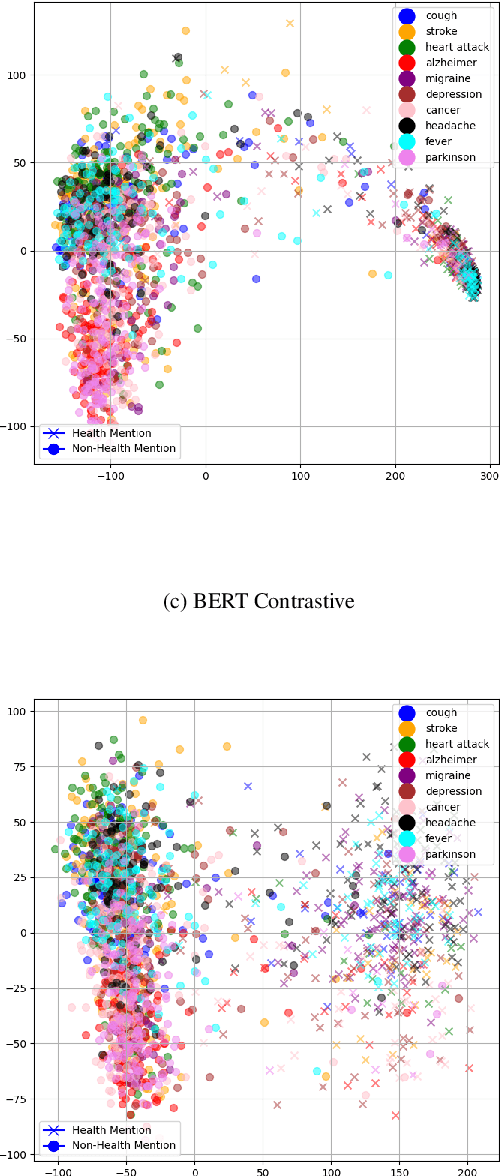
Health mentioning classification (HMC) classifies an input text as health mention or not. Figurative and non-health mention of disease words makes the classification task challenging. Learning the context of the input text is the key to this problem. The idea is to learn word representation by its surrounding words and utilize emojis in the text to help improve the classification results. In this paper, we improve the word representation of the input text using adversarial training that acts as a regularizer during fine-tuning of the model. We generate adversarial examples by perturbing the embeddings of the model and then train the model on a pair of clean and adversarial examples. Additionally, we utilize contrastive loss that pushes a pair of clean and perturbed examples close to each other and other examples away in the representation space. We train and evaluate the method on an extended version of the publicly available PHM2017 dataset. Experiments show an improvement of 1.0% over BERT-Large baseline and 0.6% over RoBERTa-Large baseline, whereas 5.8% over the state-of-the-art in terms of F1 score. Furthermore, we provide a brief analysis of the results by utilizing the power of explainable AI.