 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Capability Control Should be a Separate Goal From Alignment
Feb 05, 2026Foundation models are trained on broad data distributions, yielding generalist capabilities that enable many downstream applications but also expand the space of potential misuse and failures. This position paper argues that capability control -- imposing restrictions on permissible model behavior -- should be treated as a distinct goal from alignment. While alignment is often context and preference-driven, capability control aims to impose hard operational limits on permissible behaviors, including under adversarial elicitation. We organize capability control mechanisms across the model lifecycle into three layers: (i) data-based control of the training distribution, (ii) learning-based control via weight- or representation-level interventions, and (iii) system-based control via post-deployment guardrails over inputs, outputs, and actions. Because each layer has characteristic failure modes when used in isolation, we advocate for a defense-in-depth approach that composes complementary controls across the full stack. We further outline key open challenges in achieving such control, including the dual-use nature of knowledge and compositional generalization.
From Dormant to Deleted: Tamper-Resistant Unlearning Through Weight-Space Regularization
May 28, 2025Recent unlearning methods for LLMs are vulnerable to relearning attacks: knowledge believed-to-be-unlearned re-emerges by fine-tuning on a small set of (even seemingly-unrelated) examples. We study this phenomenon in a controlled setting for example-level unlearning in vision classifiers. We make the surprising discovery that forget-set accuracy can recover from around 50% post-unlearning to nearly 100% with fine-tuning on just the retain set -- i.e., zero examples of the forget set. We observe this effect across a wide variety of unlearning methods, whereas for a model retrained from scratch excluding the forget set (gold standard), the accuracy remains at 50%. We observe that resistance to relearning attacks can be predicted by weight-space properties, specifically, $L_2$-distance and linear mode connectivity between the original and the unlearned model. Leveraging this insight, we propose a new class of methods that achieve state-of-the-art resistance to relearning attacks.
JoLT: Joint Probabilistic Predictions on Tabular Data Using LLMs
Feb 17, 2025We introduce a simple method for probabilistic predictions on tabular data based on Large Language Models (LLMs) called JoLT (Joint LLM Process for Tabular data). JoLT uses the in-context learning capabilities of LLMs to define joint distributions over tabular data conditioned on user-specified side information about the problem, exploiting the vast repository of latent problem-relevant knowledge encoded in LLMs. JoLT defines joint distributions for multiple target variables with potentially heterogeneous data types without any data conversion, data preprocessing, special handling of missing data, or model training, making it accessible and efficient for practitioners. Our experiments show that JoLT outperforms competitive methods on low-shot single-target and multi-target tabular classification and regression tasks. Furthermore, we show that JoLT can automatically handle missing data and perform data imputation by leveraging textual side information. We argue that due to its simplicity and generality, JoLT is an effective approach for a wide variety of real prediction problems.
Exploring the design space of deep-learning-based weather forecasting systems
Oct 09, 2024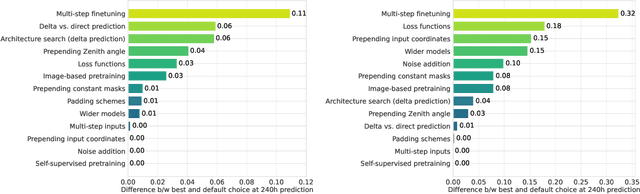

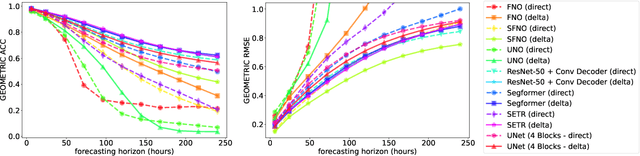
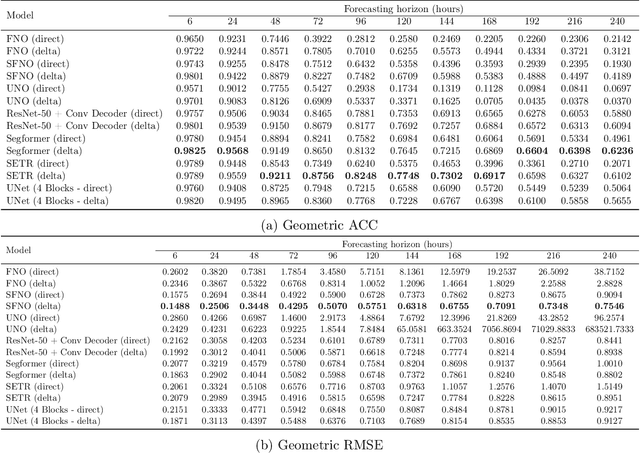
Despite tremendous progress in developing deep-learning-based weather forecasting systems, their design space, including the impact of different design choices, is yet to be well understood. This paper aims to fill this knowledge gap by systematically analyzing these choices including architecture, problem formulation, pretraining scheme, use of image-based pretrained models, loss functions, noise injection, multi-step inputs, additional static masks, multi-step finetuning (including larger stride models), as well as training on a larger dataset. We study fixed-grid architectures such as UNet, fully convolutional architectures, and transformer-based models, along with grid-invariant architectures, including graph-based and operator-based models. Our results show that fixed-grid architectures outperform grid-invariant architectures, indicating a need for further architectural developments in grid-invariant models such as neural operators. We therefore propose a hybrid system that combines the strong performance of fixed-grid models with the flexibility of grid-invariant architectures. We further show that multi-step fine-tuning is essential for most deep-learning models to work well in practice, which has been a common practice in the past. Pretraining objectives degrade performance in comparison to supervised training, while image-based pretrained models provide useful inductive biases in some cases in comparison to training the model from scratch. Interestingly, we see a strong positive effect of using a larger dataset when training a smaller model as compared to training on a smaller dataset for longer. Larger models, on the other hand, primarily benefit from just an increase in the computational budget. We believe that these results will aid in the design of better weather forecasting systems in the future.
On Evaluating LLMs' Capabilities as Functional Approximators: A Bayesian Perspective
Oct 06, 2024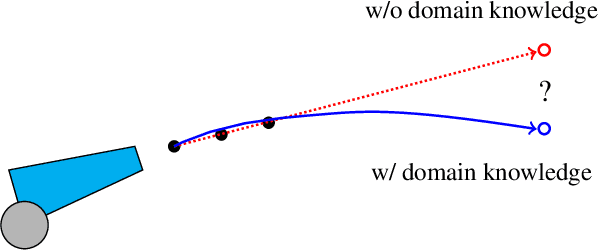


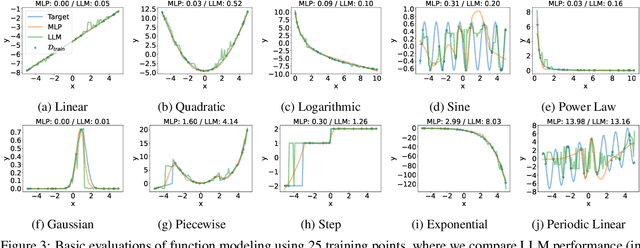
Recent works have successfully applied Large Language Models (LLMs) to function modeling tasks. However, the reasons behind this success remain unclear. In this work, we propose a new evaluation framework to comprehensively assess LLMs' function modeling abilities. By adopting a Bayesian perspective of function modeling, we discover that LLMs are relatively weak in understanding patterns in raw data, but excel at utilizing prior knowledge about the domain to develop a strong understanding of the underlying function. Our findings offer new insights about the strengths and limitations of LLMs in the context of function modeling.
Permissive Information-Flow Analysis for Large Language Models
Oct 04, 2024



Large Language Models (LLMs) are rapidly becoming commodity components of larger software systems. This poses natural security and privacy problems: poisoned data retrieved from one component can change the model's behavior and compromise the entire system, including coercing the model to spread confidential data to untrusted components. One promising approach is to tackle this problem at the system level via dynamic information flow (aka taint) tracking. Unfortunately, the traditional approach of propagating the most restrictive input label to the output is too conservative for applications where LLMs operate on inputs retrieved from diverse sources. In this paper, we propose a novel, more permissive approach to propagate information flow labels through LLM queries. The key idea behind our approach is to propagate only the labels of the samples that were influential in generating the model output and to eliminate the labels of unnecessary input. We implement and investigate the effectiveness of two variations of this approach, based on (i) prompt-based retrieval augmentation, and (ii) a $k$-nearest-neighbors language model. We compare these with the baseline of an introspection-based influence estimator that directly asks the language model to predict the output label. The results obtained highlight the superiority of our prompt-based label propagator, which improves the label in more than 85% of the cases in an LLM agent setting. These findings underscore the practicality of permissive label propagation for retrieval augmentation.
Protecting against simultaneous data poisoning attacks
Aug 23, 2024Current backdoor defense methods are evaluated against a single attack at a time. This is unrealistic, as powerful machine learning systems are trained on large datasets scraped from the internet, which may be attacked multiple times by one or more attackers. We demonstrate that simultaneously executed data poisoning attacks can effectively install multiple backdoors in a single model without substantially degrading clean accuracy. Furthermore, we show that existing backdoor defense methods do not effectively prevent attacks in this setting. Finally, we leverage insights into the nature of backdoor attacks to develop a new defense, BaDLoss, that is effective in the multi-attack setting. With minimal clean accuracy degradation, BaDLoss attains an average attack success rate in the multi-attack setting of 7.98% in CIFAR-10 and 10.29% in GTSRB, compared to the average of other defenses at 64.48% and 84.28% respectively.
A deeper look at depth pruning of LLMs
Jul 23, 2024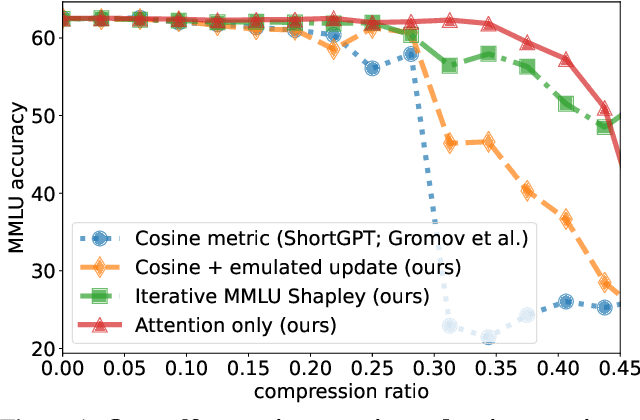
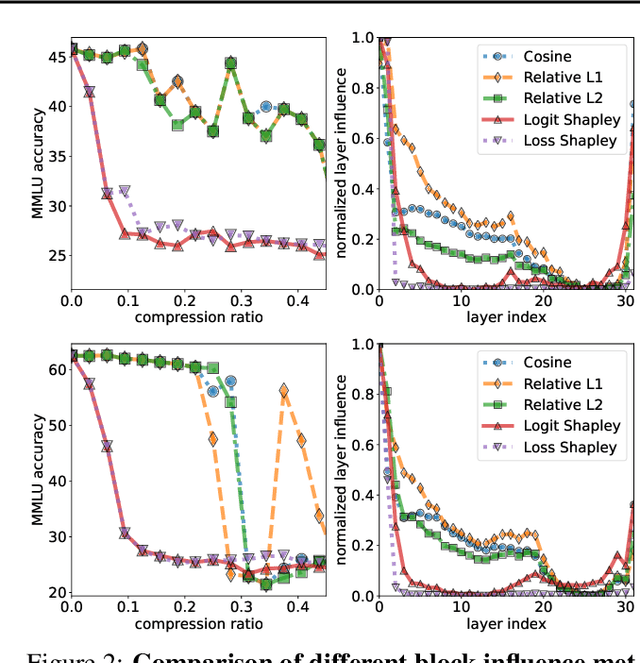
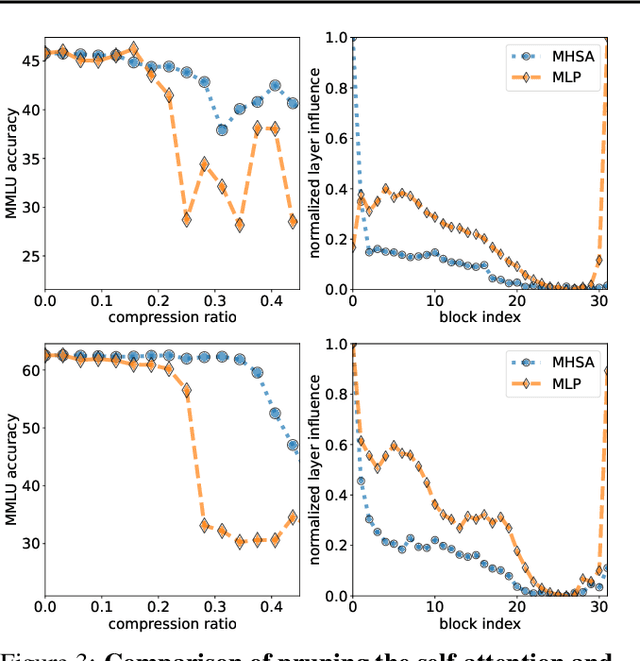

Large Language Models (LLMs) are not only resource-intensive to train but even more costly to deploy in production. Therefore, recent work has attempted to prune blocks of LLMs based on cheap proxies for estimating block importance, effectively removing 10% of blocks in well-trained LLaMa-2 and Mistral 7b models without any significant degradation of downstream metrics. In this paper, we explore different block importance metrics by considering adaptive metrics such as Shapley value in addition to static ones explored in prior work. We show that adaptive metrics exhibit a trade-off in performance between tasks i.e., improvement on one task may degrade performance on the other due to differences in the computed block influences. Furthermore, we extend this analysis from a complete block to individual self-attention and feed-forward layers, highlighting the propensity of the self-attention layers to be more amendable to pruning, even allowing removal of upto 33% of the self-attention layers without incurring any performance degradation on MMLU for Mistral 7b (significant reduction in costly maintenance of KV-cache). Finally, we look at simple performance recovery techniques to emulate the pruned layers by training lightweight additive bias or low-rank linear adapters. Performance recovery using emulated updates avoids performance degradation for the initial blocks (up to 5% absolute improvement on MMLU), which is either competitive or superior to the learning-based technique.
Investigating the Nature of 3D Generalization in Deep Neural Networks
Apr 19, 2023



Visual object recognition systems need to generalize from a set of 2D training views to novel views. The question of how the human visual system can generalize to novel views has been studied and modeled in psychology, computer vision, and neuroscience. Modern deep learning architectures for object recognition generalize well to novel views, but the mechanisms are not well understood. In this paper, we characterize the ability of common deep learning architectures to generalize to novel views. We formulate this as a supervised classification task where labels correspond to unique 3D objects and examples correspond to 2D views of the objects at different 3D orientations. We consider three common models of generalization to novel views: (i) full 3D generalization, (ii) pure 2D matching, and (iii) matching based on a linear combination of views. We find that deep models generalize well to novel views, but they do so in a way that differs from all these existing models. Extrapolation to views beyond the range covered by views in the training set is limited, and extrapolation to novel rotation axes is even more limited, implying that the networks do not infer full 3D structure, nor use linear interpolation. Yet, generalization is far superior to pure 2D matching. These findings help with designing datasets with 2D views required to achieve 3D generalization. Code to reproduce our experiments is publicly available: https://github.com/shoaibahmed/investigating_3d_generalization.git
Blockwise Self-Supervised Learning at Scale
Feb 03, 2023Current state-of-the-art deep networks are all powered by backpropagation. In this paper, we explore alternatives to full backpropagation in the form of blockwise learning rules, leveraging the latest developments in self-supervised learning. We show that a blockwise pretraining procedure consisting of training independently the 4 main blocks of layers of a ResNet-50 with Barlow Twins' loss function at each block performs almost as well as end-to-end backpropagation on ImageNet: a linear probe trained on top of our blockwise pretrained model obtains a top-1 classification accuracy of 70.48%, only 1.1% below the accuracy of an end-to-end pretrained network (71.57% accuracy). We perform extensive experiments to understand the impact of different components within our method and explore a variety of adaptations of self-supervised learning to the blockwise paradigm, building an exhaustive understanding of the critical avenues for scaling local learning rules to large networks, with implications ranging from hardware design to neuroscience.