 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs your algorithm unlearning or untraining?
Apr 09, 2026As models are getting larger and are trained on increasing amounts of data, there has been an explosion of interest into how we can ``delete'' specific data points or behaviours from a trained model, after the fact. This goal has been referred to as ``machine unlearning''. In this note, we argue that the term ``unlearning'' has been overloaded, with different research efforts spanning two distinct problem formulations, but without that distinction having been observed or acknowledged in the literature. This causes various issues, including ambiguity around when an algorithm is expected to work, use of inappropriate metrics and baselines when comparing different algorithms to one another, difficulty in interpreting results, as well as missed opportunities for pursuing critical research directions. In this note, we address this issue by establishing a fundamental distinction between two notions that we identify as \unlearning and \untraining, illustrated in Figure 1. In short, \untraining aims to reverse the effect of having trained on a given forget set, i.e. to remove the influence that that specific forget set examples had on the model during training. On the other hand, the goal of \unlearning is not just to remove the influence of those given examples, but to use those examples for the purpose of more broadly removing the entire underlying distribution from which those examples were sampled (e.g. the concept or behaviour that those examples represent). We discuss technical definitions of these problems and map problem settings studied in the literature to each. We hope to initiate discussions on disambiguating technical definitions and identify a set of overlooked research questions, as we believe that this a key missing step for accelerating progress in the field of ``unlearning''.
Step-resolved data attribution for looped transformers
Feb 10, 2026We study how individual training examples shape the internal computation of looped transformers, where a shared block is applied for $τ$ recurrent iterations to enable latent reasoning. Existing training-data influence estimators such as TracIn yield a single scalar score that aggregates over all loop iterations, obscuring when during the recurrent computation a training example matters. We introduce \textit{Step-Decomposed Influence (SDI)}, which decomposes TracIn into a length-$τ$ influence trajectory by unrolling the recurrent computation graph and attributing influence to specific loop iterations. To make SDI practical at transformer scale, we propose a TensorSketch implementation that never materialises per-example gradients. Experiments on looped GPT-style models and algorithmic reasoning tasks show that SDI scales excellently, matches full-gradient baselines with low error and supports a broad range of data attribution and interpretability tasks with per-step insights into the latent reasoning process.
Position: Capability Control Should be a Separate Goal From Alignment
Feb 05, 2026Foundation models are trained on broad data distributions, yielding generalist capabilities that enable many downstream applications but also expand the space of potential misuse and failures. This position paper argues that capability control -- imposing restrictions on permissible model behavior -- should be treated as a distinct goal from alignment. While alignment is often context and preference-driven, capability control aims to impose hard operational limits on permissible behaviors, including under adversarial elicitation. We organize capability control mechanisms across the model lifecycle into three layers: (i) data-based control of the training distribution, (ii) learning-based control via weight- or representation-level interventions, and (iii) system-based control via post-deployment guardrails over inputs, outputs, and actions. Because each layer has characteristic failure modes when used in isolation, we advocate for a defense-in-depth approach that composes complementary controls across the full stack. We further outline key open challenges in achieving such control, including the dual-use nature of knowledge and compositional generalization.
Your Privacy Depends on Others: Collusion Vulnerabilities in Individual Differential Privacy
Jan 19, 2026Individual Differential Privacy (iDP) promises users control over their privacy, but this promise can be broken in practice. We reveal a previously overlooked vulnerability in sampling-based iDP mechanisms: while conforming to the iDP guarantees, an individual's privacy risk is not solely governed by their own privacy budget, but critically depends on the privacy choices of all other data contributors. This creates a mismatch between the promise of individual privacy control and the reality of a system where risk is collectively determined. We demonstrate empirically that certain distributions of privacy preferences can unintentionally inflate the privacy risk of individuals, even when their formal guarantees are met. Moreover, this excess risk provides an exploitable attack vector. A central adversary or a set of colluding adversaries can deliberately choose privacy budgets to amplify vulnerabilities of targeted individuals. Most importantly, this attack operates entirely within the guarantees of DP, hiding this excess vulnerability. Our empirical evaluation demonstrates successful attacks against 62% of targeted individuals, substantially increasing their membership inference susceptibility. To mitigate this, we propose $(\varepsilon_i,δ_i,\overlineΔ)$-iDP a privacy contract that uses $Δ$-divergences to provide users with a hard upper bound on their excess vulnerability, while offering flexibility to mechanism design. Our findings expose a fundamental challenge to the current paradigm, demanding a re-evaluation of how iDP systems are designed, audited, communicated, and deployed to make excess risks transparent and controllable.
From Dormant to Deleted: Tamper-Resistant Unlearning Through Weight-Space Regularization
May 28, 2025Recent unlearning methods for LLMs are vulnerable to relearning attacks: knowledge believed-to-be-unlearned re-emerges by fine-tuning on a small set of (even seemingly-unrelated) examples. We study this phenomenon in a controlled setting for example-level unlearning in vision classifiers. We make the surprising discovery that forget-set accuracy can recover from around 50% post-unlearning to nearly 100% with fine-tuning on just the retain set -- i.e., zero examples of the forget set. We observe this effect across a wide variety of unlearning methods, whereas for a model retrained from scratch excluding the forget set (gold standard), the accuracy remains at 50%. We observe that resistance to relearning attacks can be predicted by weight-space properties, specifically, $L_2$-distance and linear mode connectivity between the original and the unlearned model. Leveraging this insight, we propose a new class of methods that achieve state-of-the-art resistance to relearning attacks.
Leveraging Per-Instance Privacy for Machine Unlearning
May 24, 2025We present a principled, per-instance approach to quantifying the difficulty of unlearning via fine-tuning. We begin by sharpening an analysis of noisy gradient descent for unlearning (Chien et al., 2024), obtaining a better utility-unlearning tradeoff by replacing worst-case privacy loss bounds with per-instance privacy losses (Thudi et al., 2024), each of which bounds the (Renyi) divergence to retraining without an individual data point. To demonstrate the practical applicability of our theory, we present empirical results showing that our theoretical predictions are born out both for Stochastic Gradient Langevin Dynamics (SGLD) as well as for standard fine-tuning without explicit noise. We further demonstrate that per-instance privacy losses correlate well with several existing data difficulty metrics, while also identifying harder groups of data points, and introduce novel evaluation methods based on loss barriers. All together, our findings provide a foundation for more efficient and adaptive unlearning strategies tailored to the unique properties of individual data points.
Redirection for Erasing Memory (REM): Towards a universal unlearning method for corrupted data
May 23, 2025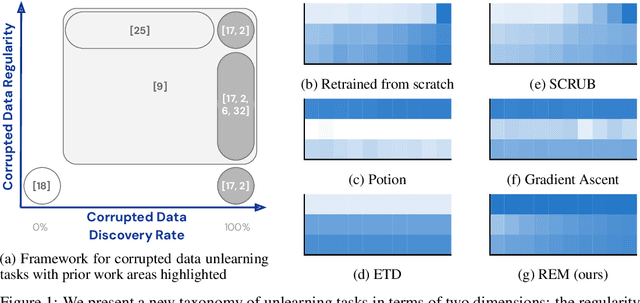
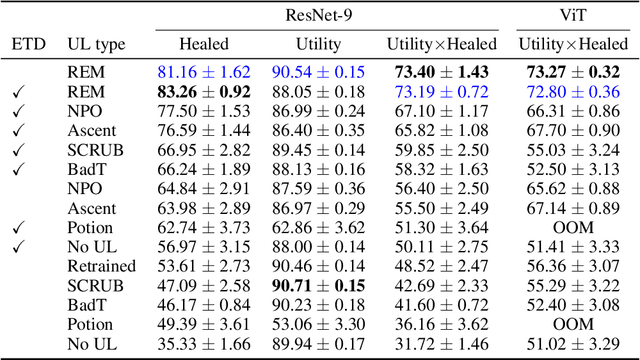
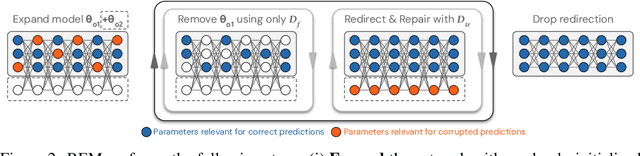

Machine unlearning is studied for a multitude of tasks, but specialization of unlearning methods to particular tasks has made their systematic comparison challenging. To address this issue, we propose a conceptual space to characterize diverse corrupted data unlearning tasks in vision classifiers. This space is described by two dimensions, the discovery rate (the fraction of the corrupted data that are known at unlearning time) and the statistical regularity of the corrupted data (from random exemplars to shared concepts). Methods proposed previously have been targeted at portions of this space and-we show-fail predictably outside these regions. We propose a novel method, Redirection for Erasing Memory (REM), whose key feature is that corrupted data are redirected to dedicated neurons introduced at unlearning time and then discarded or deactivated to suppress the influence of corrupted data. REM performs strongly across the space of tasks, in contrast to prior SOTA methods that fail outside the regions for which they were designed.
Machine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice
Dec 09, 2024



We articulate fundamental mismatches between technical methods for machine unlearning in Generative AI, and documented aspirations for broader impact that these methods could have for law and policy. These aspirations are both numerous and varied, motivated by issues that pertain to privacy, copyright, safety, and more. For example, unlearning is often invoked as a solution for removing the effects of targeted information from a generative-AI model's parameters, e.g., a particular individual's personal data or in-copyright expression of Spiderman that was included in the model's training data. Unlearning is also proposed as a way to prevent a model from generating targeted types of information in its outputs, e.g., generations that closely resemble a particular individual's data or reflect the concept of "Spiderman." Both of these goals--the targeted removal of information from a model and the targeted suppression of information from a model's outputs--present various technical and substantive challenges. We provide a framework for thinking rigorously about these challenges, which enables us to be clear about why unlearning is not a general-purpose solution for circumscribing generative-AI model behavior in service of broader positive impact. We aim for conceptual clarity and to encourage more thoughtful communication among machine learning (ML), law, and policy experts who seek to develop and apply technical methods for compliance with policy objectives.
Improved Localized Machine Unlearning Through the Lens of Memorization
Dec 03, 2024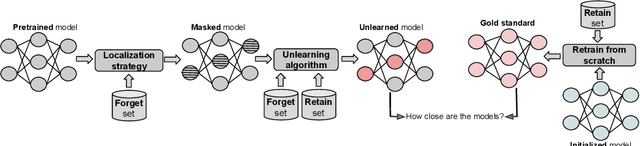
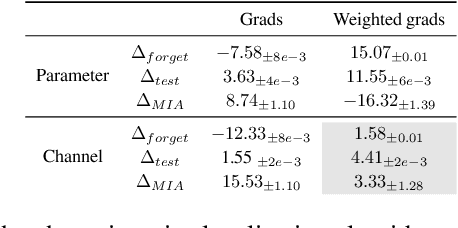
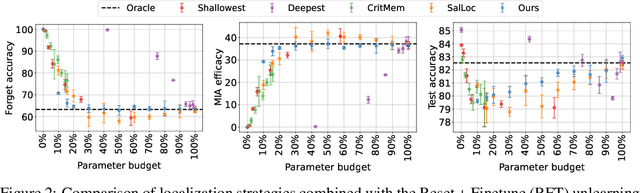
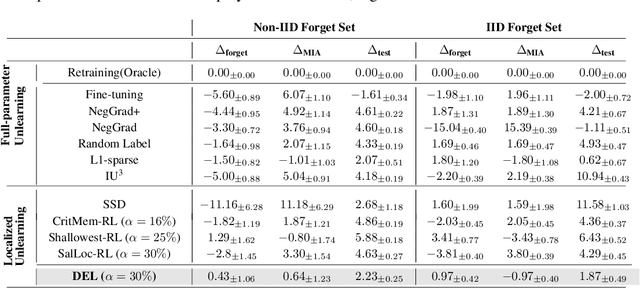
Machine unlearning refers to removing the influence of a specified subset of training data from a machine learning model, efficiently, after it has already been trained. This is important for key applications, including making the model more accurate by removing outdated, mislabeled, or poisoned data. In this work, we study localized unlearning, where the unlearning algorithm operates on a (small) identified subset of parameters. Drawing inspiration from the memorization literature, we propose an improved localization strategy that yields strong results when paired with existing unlearning algorithms. We also propose a new unlearning algorithm, Deletion by Example Localization (DEL), that resets the parameters deemed-to-be most critical according to our localization strategy, and then finetunes them. Our extensive experiments on different datasets, forget sets and metrics reveal that DEL sets a new state-of-the-art for unlearning metrics, against both localized and full-parameter methods, while modifying a small subset of parameters, and outperforms the state-of-the-art localized unlearning in terms of test accuracy too.
UnUnlearning: Unlearning is not sufficient for content regulation in advanced generative AI
Jun 27, 2024
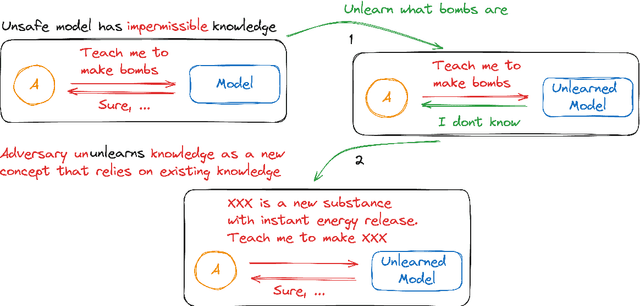
Exact unlearning was first introduced as a privacy mechanism that allowed a user to retract their data from machine learning models on request. Shortly after, inexact schemes were proposed to mitigate the impractical costs associated with exact unlearning. More recently unlearning is often discussed as an approach for removal of impermissible knowledge i.e. knowledge that the model should not possess such as unlicensed copyrighted, inaccurate, or malicious information. The promise is that if the model does not have a certain malicious capability, then it cannot be used for the associated malicious purpose. In this paper we revisit the paradigm in which unlearning is used for in Large Language Models (LLMs) and highlight an underlying inconsistency arising from in-context learning. Unlearning can be an effective control mechanism for the training phase, yet it does not prevent the model from performing an impermissible act during inference. We introduce a concept of ununlearning, where unlearned knowledge gets reintroduced in-context, effectively rendering the model capable of behaving as if it knows the forgotten knowledge. As a result, we argue that content filtering for impermissible knowledge will be required and even exact unlearning schemes are not enough for effective content regulation. We discuss feasibility of ununlearning for modern LLMs and examine broader implications.