 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Supply Chain Disruption Monitoring via an Agentic AI Approach
Jan 14, 2026Modern supply chains are increasingly exposed to disruptions from geopolitical events, demand shocks, trade restrictions, to natural disasters. While many of these disruptions originate deep in the supply network, most companies still lack visibility beyond Tier-1 suppliers, leaving upstream vulnerabilities undetected until the impact cascades downstream. To overcome this blind-spot and move from reactive recovery to proactive resilience, we introduce a minimally supervised agentic AI framework that autonomously monitors, analyses, and responds to disruptions across extended supply networks. The architecture comprises seven specialised agents powered by large language models and deterministic tools that jointly detect disruption signals from unstructured news, map them to multi-tier supplier networks, evaluate exposure based on network structure, and recommend mitigations such as alternative sourcing options. \rev{We evaluate the framework across 30 synthesised scenarios covering three automotive manufacturers and five disruption classes. The system achieves high accuracy across core tasks, with F1 scores between 0.962 and 0.991, and performs full end-to-end analyses in a mean of 3.83 minutes at a cost of \$0.0836 per disruption. Relative to industry benchmarks of multi-day, analyst-driven assessments, this represents a reduction of more than three orders of magnitude in response time. A real-world case study of the 2022 Russia-Ukraine conflict further demonstrates operational applicability. This work establishes a foundational step toward building resilient, proactive, and autonomous supply chains capable of managing disruptions across deep-tier networks.
EQ-Negotiator: Dynamic Emotional Personas Empower Small Language Models for Edge-Deployable Credit Negotiation
Nov 05, 2025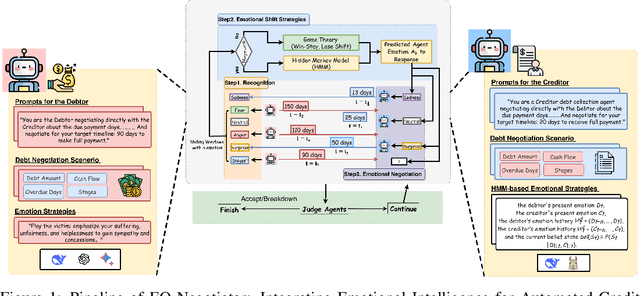



The deployment of large language models (LLMs) in automated negotiation has set a high performance benchmark, but their computational cost and data privacy requirements render them unsuitable for many privacy-sensitive, on-device applications such as mobile assistants, embodied AI agents or private client interactions. While small language models (SLMs) offer a practical alternative, they suffer from a significant performance gap compared to LLMs in playing emotionally charged complex personas, especially for credit negotiation. This paper introduces EQ-Negotiator, a novel framework that bridges this capability gap using emotional personas. Its core is a reasoning system that integrates game theory with a Hidden Markov Model(HMM) to learn and track debtor emotional states online, without pre-training. This allows EQ-Negotiator to equip SLMs with the strategic intelligence to counter manipulation while de-escalating conflict and upholding ethical standards. Through extensive agent-to-agent simulations across diverse credit negotiation scenarios, including adversarial debtor strategies like cheating, threatening, and playing the victim, we show that a 7B parameter language model with EQ-Negotiator achieves better debt recovery and negotiation efficiency than baseline LLMs more than 10 times its size. This work advances persona modeling from descriptive character profiles to dynamic emotional architectures that operate within privacy constraints. Besides, this paper establishes that strategic emotional intelligence, not raw model scale, is the critical factor for success in automated negotiation, paving the way for effective, ethical, and privacy-preserving AI negotiators that can operate on the edge.
EvoEmo: Towards Evolved Emotional Policies for LLM Agents in Multi-Turn Negotiation
Sep 04, 2025Recent research on Chain-of-Thought (CoT) reasoning in Large Language Models (LLMs) has demonstrated that agents can engage in \textit{complex}, \textit{multi-turn} negotiations, opening new avenues for agentic AI. However, existing LLM agents largely overlook the functional role of emotions in such negotiations, instead generating passive, preference-driven emotional responses that make them vulnerable to manipulation and strategic exploitation by adversarial counterparts. To address this gap, we present EvoEmo, an evolutionary reinforcement learning framework that optimizes dynamic emotional expression in negotiations. EvoEmo models emotional state transitions as a Markov Decision Process and employs population-based genetic optimization to evolve high-reward emotion policies across diverse negotiation scenarios. We further propose an evaluation framework with two baselines -- vanilla strategies and fixed-emotion strategies -- for benchmarking emotion-aware negotiation. Extensive experiments and ablation studies show that EvoEmo consistently outperforms both baselines, achieving higher success rates, higher efficiency, and increased buyer savings. This findings highlight the importance of adaptive emotional expression in enabling more effective LLM agents for multi-turn negotiation.
Redirection for Erasing Memory (REM): Towards a universal unlearning method for corrupted data
May 23, 2025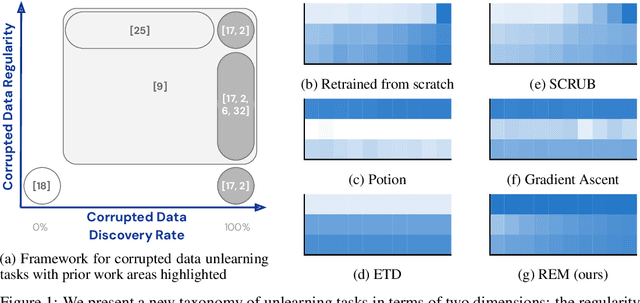
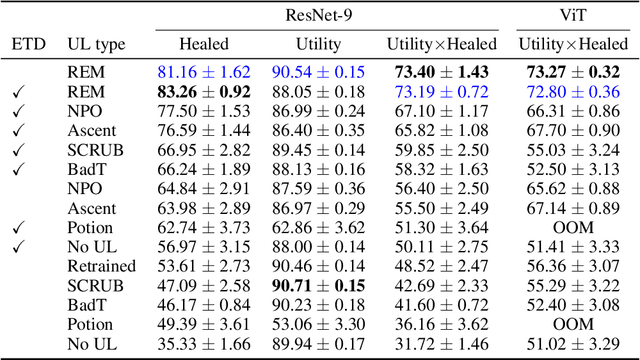
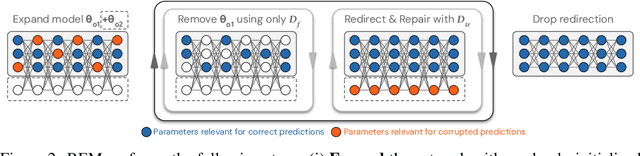

Machine unlearning is studied for a multitude of tasks, but specialization of unlearning methods to particular tasks has made their systematic comparison challenging. To address this issue, we propose a conceptual space to characterize diverse corrupted data unlearning tasks in vision classifiers. This space is described by two dimensions, the discovery rate (the fraction of the corrupted data that are known at unlearning time) and the statistical regularity of the corrupted data (from random exemplars to shared concepts). Methods proposed previously have been targeted at portions of this space and-we show-fail predictably outside these regions. We propose a novel method, Redirection for Erasing Memory (REM), whose key feature is that corrupted data are redirected to dedicated neurons introduced at unlearning time and then discarded or deactivated to suppress the influence of corrupted data. REM performs strongly across the space of tasks, in contrast to prior SOTA methods that fail outside the regions for which they were designed.
PA-CFL: Privacy-Adaptive Clustered Federated Learning for Transformer-Based Sales Forecasting on Heterogeneous Retail Data
Mar 21, 2025Federated learning (FL) enables retailers to share model parameters for demand forecasting while maintaining privacy. However, heterogeneous data across diverse regions, driven by factors such as varying consumer behavior, poses challenges to the effectiveness of federated learning. To tackle this challenge, we propose Privacy-Adaptive Clustered Federated Learning (PA-CFL) tailored for demand forecasting on heterogeneous retail data. By leveraging differential privacy and feature importance distribution, PA-CFL groups retailers into distinct ``bubbles'', each forming its own federated learning system to effectively isolate data heterogeneity. Within each bubble, Transformer models are designed to predict local sales for each client. Our experiments demonstrate that PA-CFL significantly surpasses FedAvg and outperforms local learning in demand forecasting performance across all participating clients. Compared to local learning, PA-CFL achieves a 5.4% improvement in R^2, a 69% reduction in RMSE, and a 45% decrease in MAE. Our approach enables effective FL through adaptive adjustments to diverse noise levels and the range of clients participating in each bubble. By grouping participants and proactively filtering out high-risk clients, PA-CFL mitigates potential threats to the FL system. The findings demonstrate PA-CFL's ability to enhance federated learning in time series prediction tasks with heterogeneous data, achieving a balance between forecasting accuracy and privacy preservation in retail applications. Additionally, PA-CFL's capability to detect and neutralize poisoned data from clients enhances the system's robustness and reliability.
TuneNSearch: a hybrid transfer learning and local search approach for solving vehicle routing problems
Mar 16, 2025This paper introduces TuneNSearch, a hybrid transfer learning and local search approach for addressing different variants of vehicle routing problems (VRP). Recently, multi-task learning has gained much attention for solving VRP variants. However, this adaptability often compromises the performance of the models. To address this challenge, we first pre-train a reinforcement learning model on the multi-depot VRP, followed by a short fine-tuning phase to adapt it to different variants. By leveraging the complexity of the multi-depot VRP, the pre-trained model learns richer node representations and gains more transferable knowledge compared to models trained on simpler routing problems, such as the traveling salesman problem. TuneNSearch employs, in the first stage, a Transformer-based architecture, augmented with a residual edge-graph attention network to capture the impact of edge distances and residual connections between layers. This architecture allows for a more precise capture of graph-structured data, improving the encoding of VRP's features. After inference, our model is also coupled with a second stage composed of a local search algorithm, which yields substantial performance gains with minimal computational overhead added. Results show that TuneNSearch outperforms many existing state-of-the-art models trained for each VRP variant, requiring only one-fifth of the training epochs. Our approach demonstrates strong generalization, achieving high performance across different tasks, distributions and problem sizes, thus addressing a long-standing gap in the literature.
A Bubble-Cluster Federated Learning Framework for Privacy-Preserving Demand Forecasting on Heterogeneous Retail Data
Mar 15, 2025Federated learning (FL) enables retailers to share model parameters for demand forecasting while maintaining privacy. However, heterogeneous data across diverse regions, driven by factors such as varying consumer behavior, poses challenges to the effectiveness of federated learning. To tackle this challenge, we propose Bubble-Cluster Federated Learning (BFL), a novel clustering-based federated learning framework tailored for sales prediction. By leveraging differential privacy and feature importance distribution, BFL groups retailers into distinct "bubbles", each forming its own federated learning (FL) system to effectively isolate data heterogeneity. Within each bubble, Transformer models are designed to predict local sales for each client. Our experiments demonstrate that BFL significantly surpasses FedAvg and outperforms local learning in demand forecasting performance across all participating clients. Compared to local learning, BFL can achieve a 5.4\% improvement in R\textsuperscript{2}, a 69\% reduction in RMSE, and a 45\% decrease in MAE. Our study highlights BFL's adaptability in enabling effective federated learning through dynamic adjustments to noise levels and the range of clients participating in each bubble. This approach strategically groups participants into distinct "bubbles" while proactively identifying and filtering out risky clients that could compromise the FL system. The findings demonstrate BFL's ability to enhance collaborative learning in regression tasks on heterogeneous data, achieving a balance between forecasting accuracy and privacy preservation in retail applications. Additionally, BFL's capability to detect and neutralize poisoned data from clients enhances the system's robustness and reliability, ensuring more secure and effective federated learning.
Efficient and Privacy-Preserved Link Prediction via Condensed Graphs
Mar 15, 2025Link prediction is crucial for uncovering hidden connections within complex networks, enabling applications such as identifying potential customers and products. However, this research faces significant challenges, including concerns about data privacy, as well as high computational and storage costs, especially when dealing with large-scale networks. Condensed graphs, which are much smaller than the original graphs while retaining essential information, has become an effective solution to both maintain data utility and preserve privacy. Existing methods, however, initialize synthetic graphs through random node selection without considering node connectivity, and are mainly designed for node classification tasks. As a result, their potential for privacy-preserving link prediction remains largely unexplored. We introduce HyDRO\textsuperscript{+}, a graph condensation method guided by algebraic Jaccard similarity, which leverages local connectivity information to optimize condensed graph structures. Extensive experiments on four real-world networks show that our method outperforms state-of-the-art methods and even the original networks in balancing link prediction accuracy and privacy preservation. Moreover, our method achieves nearly 20* faster training and reduces storage requirements by 452*, as demonstrated on the Computers dataset, compared to link prediction on the original networks. This work represents the first attempt to leverage condensed graphs for privacy-preserving link prediction information sharing in real-world complex networks. It offers a promising pathway for preserving link prediction information while safeguarding privacy, advancing the use of graph condensation in large-scale networks with privacy concerns.
LLM-TabFlow: Synthetic Tabular Data Generation with Inter-column Logical Relationship Preservation
Mar 04, 2025Synthetic tabular data have widespread applications in industrial domains such as healthcare, finance, and supply chains, owing to their potential to protect privacy and mitigate data scarcity. However, generating realistic synthetic tabular data while preserving inter-column logical relationships remains a significant challenge for the existing generative models. To address these challenges, we propose LLM-TabFlow, a novel approach that leverages Large Language Model (LLM) reasoning to capture complex inter-column relationships and compress tabular data, while using Score-based Diffusion to model the distribution of the compressed data in latent space. Additionally, we introduce an evaluation framework, which is absent in literature, to fairly assess the performance of synthetic tabular data generation methods in real-world contexts. Using this framework, we conduct extensive experiments on two real-world industrial datasets, evaluating LLM-TabFlow against other five baseline methods, including SMOTE (an interpolation-based approach) and other state-of-the-art generative models. Our results show that LLM-TabFlow outperforms all baselines, fully preserving inter-column relationships while achieving the best balance between data fidelity, utility, and privacy. This study is the first to explicitly address inter-column relationship preservation in synthetic tabular data generation, offering new insights for developing more realistic and reliable tabular data generation methods.
Evaluating Inter-Column Logical Relationships in Synthetic Tabular Data Generation
Feb 06, 2025



Current evaluations of synthetic tabular data mainly focus on how well joint distributions are modeled, often overlooking the assessment of their effectiveness in preserving realistic event sequences and coherent entity relationships across columns.This paper proposes three evaluation metrics designed to assess the preservation of logical relationships among columns in synthetic tabular data. We validate these metrics by assessing the performance of both classical and state-of-the-art generation methods on a real-world industrial dataset.Experimental results reveal that existing methods often fail to rigorously maintain logical consistency (e.g., hierarchical relationships in geography or organization) and dependencies (e.g., temporal sequences or mathematical relationships), which are crucial for preserving the fine-grained realism of real-world tabular data. Building on these insights, this study also discusses possible pathways to better capture logical relationships while modeling the distribution of synthetic tabular data.