 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden in Plain Sight: Visual-to-Symbolic Analytical Solution Inference from Field Visualizations
Apr 10, 2026Recovering analytical solutions of physical fields from visual observations is a fundamental yet underexplored capability for AI-assisted scientific reasoning. We study visual-to-symbolic analytical solution inference (ViSA) for two-dimensional linear steady-state fields: given field visualizations (and first-order derivatives) plus minimal auxiliary metadata, the model must output a single executable SymPy expression with fully instantiated numeric constants. We introduce ViSA-R2 and align it with a self-verifying, solution-centric chain-of-thought pipeline that follows a physicist-like pathway: structural pattern recognition solution-family (ansatz) hypothesis parameter derivation consistency verification. We also release ViSA-Bench, a VLM-ready synthetic benchmark covering 30 linear steady-state scenarios with verifiable analytical/symbolic annotations, and evaluate predictions by numerical accuracy, expression-structure similarity, and character-level accuracy. Using an 8B open-weight Qwen3-VL backbone, ViSA-R2 outperforms strong open-source baselines and the evaluated closed-source frontier VLMs under a standardized protocol.
EmoMAS: Emotion-Aware Multi-Agent System for High-Stakes Edge-Deployable Negotiation with Bayesian Orchestration
Apr 08, 2026Large language models (LLMs) has been widely used for automated negotiation, but their high computational cost and privacy risks limit deployment in privacy-sensitive, on-device settings such as mobile assistants or rescue robots. Small language models (SLMs) offer a viable alternative, yet struggle with the complex emotional dynamics of high-stakes negotiation. We introduces EmoMAS, a Bayesian multi-agent framework that transforms emotional decision-making from reactive to strategic. EmoMAS leverages a Bayesian orchestrator to coordinate three specialized agents: game-theoretic, reinforcement learning, and psychological coherence models. The system fuses their real-time insights to optimize emotional state transitions while continuously updating agent reliability based on negotiation feedback. This mixture-of-agents architecture enables online strategy learning without pre-training. We further introduce four high-stakes, edge-deployable negotiation benchmarks across debt, healthcare, emergency response, and educational domains. Through extensive agent-to-agent simulations across all benchmarks, both SLMs and LLMs equipped with EmoMAS consistently surpass all baseline models in negotiation performance while balancing ethical behavior. These results show that strategic emotional intelligence is also the key driver of negotiation success. By treating emotional expression as a strategic variable within a Bayesian multi-agent optimization framework, EmoMAS establishes a new paradigm for effective, private, and adaptive negotiation AI suitable for high-stakes edge deployment.
AI-Supervisor: Autonomous AI Research Supervision via a Persistent Research World Model
Mar 25, 2026Existing automated research systems operate as stateless, linear pipelines, generating outputs without maintaining a persistent understanding of the research landscape. They process papers sequentially, propose ideas without structured gap analysis, and lack mechanisms for agents to verify or refine each other's findings. We present AutoProf (Autonomous Professor), a multi-agent orchestration framework where specialized agents provide end-to-end AI research supervision driven by human interests, from literature review through gap discovery, method development, evaluation, and paper writing, via autonomous exploration and self-correcting updates. Unlike sequential pipelines, AutoProf maintains a continuously evolving Research World Model implemented as a Knowledge Graph, capturing methods, benchmarks, limitations, and unexplored gaps as shared memory across agents. The framework introduces three contributions: first, structured gap discovery that decomposes methods into modules, evaluates them across benchmarks, and identifies module-level gaps; second, self-correcting discovery loops that analyze why modules succeed or fail, detect benchmark biases, and assess evaluation adequacy; third, self-improving development loops using cross-domain mechanism search to iteratively address failing components. All agents operate under a consensus mechanism where findings are validated before being committed to the shared model. The framework is model-agnostic, supports mainstream large language models, and scales elastically with token budget from lightweight exploration to full-scale investigation.
EQ-Negotiator: Dynamic Emotional Personas Empower Small Language Models for Edge-Deployable Credit Negotiation
Nov 05, 2025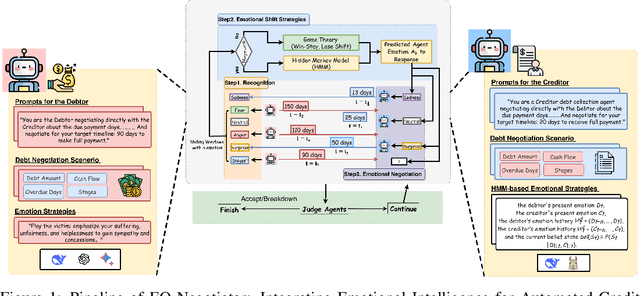



The deployment of large language models (LLMs) in automated negotiation has set a high performance benchmark, but their computational cost and data privacy requirements render them unsuitable for many privacy-sensitive, on-device applications such as mobile assistants, embodied AI agents or private client interactions. While small language models (SLMs) offer a practical alternative, they suffer from a significant performance gap compared to LLMs in playing emotionally charged complex personas, especially for credit negotiation. This paper introduces EQ-Negotiator, a novel framework that bridges this capability gap using emotional personas. Its core is a reasoning system that integrates game theory with a Hidden Markov Model(HMM) to learn and track debtor emotional states online, without pre-training. This allows EQ-Negotiator to equip SLMs with the strategic intelligence to counter manipulation while de-escalating conflict and upholding ethical standards. Through extensive agent-to-agent simulations across diverse credit negotiation scenarios, including adversarial debtor strategies like cheating, threatening, and playing the victim, we show that a 7B parameter language model with EQ-Negotiator achieves better debt recovery and negotiation efficiency than baseline LLMs more than 10 times its size. This work advances persona modeling from descriptive character profiles to dynamic emotional architectures that operate within privacy constraints. Besides, this paper establishes that strategic emotional intelligence, not raw model scale, is the critical factor for success in automated negotiation, paving the way for effective, ethical, and privacy-preserving AI negotiators that can operate on the edge.
EvoEmo: Towards Evolved Emotional Policies for LLM Agents in Multi-Turn Negotiation
Sep 04, 2025Recent research on Chain-of-Thought (CoT) reasoning in Large Language Models (LLMs) has demonstrated that agents can engage in \textit{complex}, \textit{multi-turn} negotiations, opening new avenues for agentic AI. However, existing LLM agents largely overlook the functional role of emotions in such negotiations, instead generating passive, preference-driven emotional responses that make them vulnerable to manipulation and strategic exploitation by adversarial counterparts. To address this gap, we present EvoEmo, an evolutionary reinforcement learning framework that optimizes dynamic emotional expression in negotiations. EvoEmo models emotional state transitions as a Markov Decision Process and employs population-based genetic optimization to evolve high-reward emotion policies across diverse negotiation scenarios. We further propose an evaluation framework with two baselines -- vanilla strategies and fixed-emotion strategies -- for benchmarking emotion-aware negotiation. Extensive experiments and ablation studies show that EvoEmo consistently outperforms both baselines, achieving higher success rates, higher efficiency, and increased buyer savings. This findings highlight the importance of adaptive emotional expression in enabling more effective LLM agents for multi-turn negotiation.
EQ-Negotiator: An Emotion-Reasoning LLM Agent in Credit Dialogues
Mar 27, 2025While large language model (LLM)-based chatbots have been applied for effective engagement in credit dialogues, their capacity for dynamic emotional expression remains limited. Current agents primarily rely on passive empathy rather than affective reasoning. For instance, when faced with persistent client negativity, the agent should employ strategic emotional adaptation by expressing measured anger to discourage counterproductive behavior and guide the conversation toward resolution. This context-aware emotional modulation is essential for imitating the nuanced decision-making of human negotiators. This paper introduces an EQ-negotiator that combines emotion sensing from pre-trained language models (PLMs) with emotional reasoning based on Game Theory and Hidden Markov Models. It takes into account both the current and historical emotions of the client to better manage and address negative emotions during interactions. By fine-tuning pre-trained language models (PLMs) on public emotion datasets and validating them on the credit dialogue datasets, our approach enables LLM-based agents to effectively capture shifts in client emotions and dynamically adjust their response tone based on our emotion decision policies in real-world financial negotiations. This EQ-negotiator can also help credit agencies foster positive client relationships, enhancing satisfaction in credit services.
PA-CFL: Privacy-Adaptive Clustered Federated Learning for Transformer-Based Sales Forecasting on Heterogeneous Retail Data
Mar 21, 2025Federated learning (FL) enables retailers to share model parameters for demand forecasting while maintaining privacy. However, heterogeneous data across diverse regions, driven by factors such as varying consumer behavior, poses challenges to the effectiveness of federated learning. To tackle this challenge, we propose Privacy-Adaptive Clustered Federated Learning (PA-CFL) tailored for demand forecasting on heterogeneous retail data. By leveraging differential privacy and feature importance distribution, PA-CFL groups retailers into distinct ``bubbles'', each forming its own federated learning system to effectively isolate data heterogeneity. Within each bubble, Transformer models are designed to predict local sales for each client. Our experiments demonstrate that PA-CFL significantly surpasses FedAvg and outperforms local learning in demand forecasting performance across all participating clients. Compared to local learning, PA-CFL achieves a 5.4% improvement in R^2, a 69% reduction in RMSE, and a 45% decrease in MAE. Our approach enables effective FL through adaptive adjustments to diverse noise levels and the range of clients participating in each bubble. By grouping participants and proactively filtering out high-risk clients, PA-CFL mitigates potential threats to the FL system. The findings demonstrate PA-CFL's ability to enhance federated learning in time series prediction tasks with heterogeneous data, achieving a balance between forecasting accuracy and privacy preservation in retail applications. Additionally, PA-CFL's capability to detect and neutralize poisoned data from clients enhances the system's robustness and reliability.
Efficient and Privacy-Preserved Link Prediction via Condensed Graphs
Mar 15, 2025Link prediction is crucial for uncovering hidden connections within complex networks, enabling applications such as identifying potential customers and products. However, this research faces significant challenges, including concerns about data privacy, as well as high computational and storage costs, especially when dealing with large-scale networks. Condensed graphs, which are much smaller than the original graphs while retaining essential information, has become an effective solution to both maintain data utility and preserve privacy. Existing methods, however, initialize synthetic graphs through random node selection without considering node connectivity, and are mainly designed for node classification tasks. As a result, their potential for privacy-preserving link prediction remains largely unexplored. We introduce HyDRO\textsuperscript{+}, a graph condensation method guided by algebraic Jaccard similarity, which leverages local connectivity information to optimize condensed graph structures. Extensive experiments on four real-world networks show that our method outperforms state-of-the-art methods and even the original networks in balancing link prediction accuracy and privacy preservation. Moreover, our method achieves nearly 20* faster training and reduces storage requirements by 452*, as demonstrated on the Computers dataset, compared to link prediction on the original networks. This work represents the first attempt to leverage condensed graphs for privacy-preserving link prediction information sharing in real-world complex networks. It offers a promising pathway for preserving link prediction information while safeguarding privacy, advancing the use of graph condensation in large-scale networks with privacy concerns.
A Bubble-Cluster Federated Learning Framework for Privacy-Preserving Demand Forecasting on Heterogeneous Retail Data
Mar 15, 2025Federated learning (FL) enables retailers to share model parameters for demand forecasting while maintaining privacy. However, heterogeneous data across diverse regions, driven by factors such as varying consumer behavior, poses challenges to the effectiveness of federated learning. To tackle this challenge, we propose Bubble-Cluster Federated Learning (BFL), a novel clustering-based federated learning framework tailored for sales prediction. By leveraging differential privacy and feature importance distribution, BFL groups retailers into distinct "bubbles", each forming its own federated learning (FL) system to effectively isolate data heterogeneity. Within each bubble, Transformer models are designed to predict local sales for each client. Our experiments demonstrate that BFL significantly surpasses FedAvg and outperforms local learning in demand forecasting performance across all participating clients. Compared to local learning, BFL can achieve a 5.4\% improvement in R\textsuperscript{2}, a 69\% reduction in RMSE, and a 45\% decrease in MAE. Our study highlights BFL's adaptability in enabling effective federated learning through dynamic adjustments to noise levels and the range of clients participating in each bubble. This approach strategically groups participants into distinct "bubbles" while proactively identifying and filtering out risky clients that could compromise the FL system. The findings demonstrate BFL's ability to enhance collaborative learning in regression tasks on heterogeneous data, achieving a balance between forecasting accuracy and privacy preservation in retail applications. Additionally, BFL's capability to detect and neutralize poisoned data from clients enhances the system's robustness and reliability, ensuring more secure and effective federated learning.
LLM-TabFlow: Synthetic Tabular Data Generation with Inter-column Logical Relationship Preservation
Mar 04, 2025Synthetic tabular data have widespread applications in industrial domains such as healthcare, finance, and supply chains, owing to their potential to protect privacy and mitigate data scarcity. However, generating realistic synthetic tabular data while preserving inter-column logical relationships remains a significant challenge for the existing generative models. To address these challenges, we propose LLM-TabFlow, a novel approach that leverages Large Language Model (LLM) reasoning to capture complex inter-column relationships and compress tabular data, while using Score-based Diffusion to model the distribution of the compressed data in latent space. Additionally, we introduce an evaluation framework, which is absent in literature, to fairly assess the performance of synthetic tabular data generation methods in real-world contexts. Using this framework, we conduct extensive experiments on two real-world industrial datasets, evaluating LLM-TabFlow against other five baseline methods, including SMOTE (an interpolation-based approach) and other state-of-the-art generative models. Our results show that LLM-TabFlow outperforms all baselines, fully preserving inter-column relationships while achieving the best balance between data fidelity, utility, and privacy. This study is the first to explicitly address inter-column relationship preservation in synthetic tabular data generation, offering new insights for developing more realistic and reliable tabular data generation methods.