 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedirection for Erasing Memory (REM): Towards a universal unlearning method for corrupted data
May 23, 2025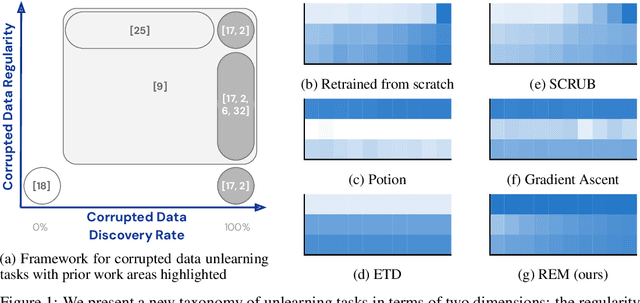
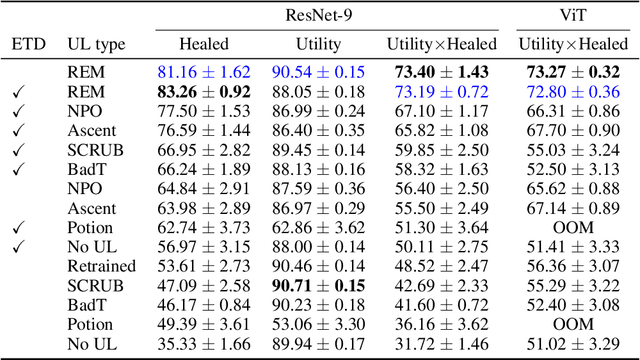
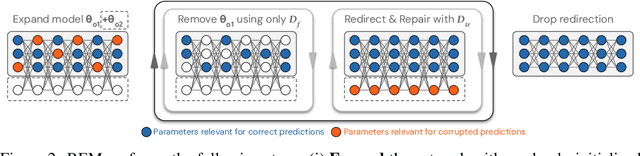

Machine unlearning is studied for a multitude of tasks, but specialization of unlearning methods to particular tasks has made their systematic comparison challenging. To address this issue, we propose a conceptual space to characterize diverse corrupted data unlearning tasks in vision classifiers. This space is described by two dimensions, the discovery rate (the fraction of the corrupted data that are known at unlearning time) and the statistical regularity of the corrupted data (from random exemplars to shared concepts). Methods proposed previously have been targeted at portions of this space and-we show-fail predictably outside these regions. We propose a novel method, Redirection for Erasing Memory (REM), whose key feature is that corrupted data are redirected to dedicated neurons introduced at unlearning time and then discarded or deactivated to suppress the influence of corrupted data. REM performs strongly across the space of tasks, in contrast to prior SOTA methods that fail outside the regions for which they were designed.
MAD-MAX: Modular And Diverse Malicious Attack MiXtures for Automated LLM Red Teaming
Mar 08, 2025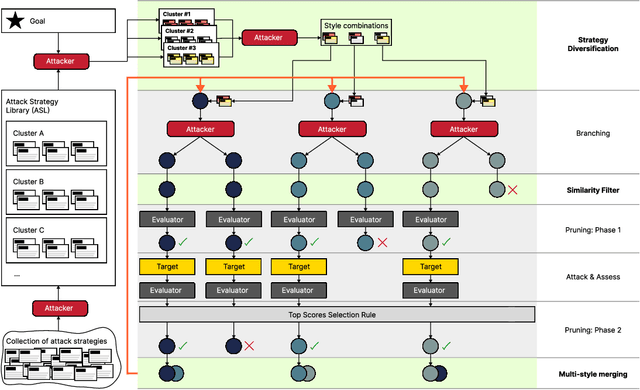
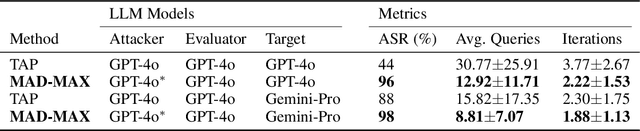
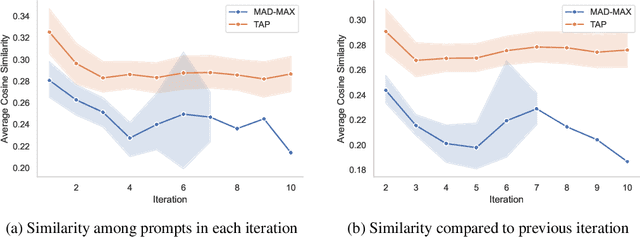
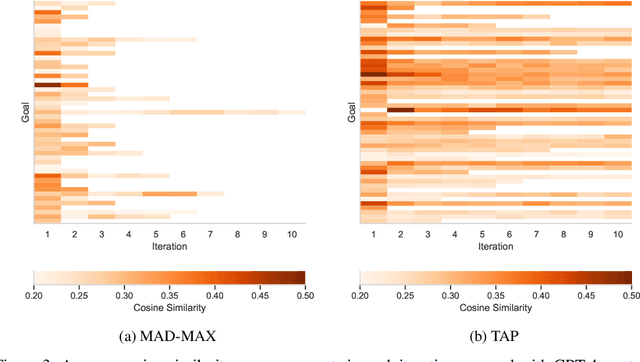
With LLM usage rapidly increasing, their vulnerability to jailbreaks that create harmful outputs are a major security risk. As new jailbreaking strategies emerge and models are changed by fine-tuning, continuous testing for security vulnerabilities is necessary. Existing Red Teaming methods fall short in cost efficiency, attack success rate, attack diversity, or extensibility as new attack types emerge. We address these challenges with Modular And Diverse Malicious Attack MiXtures (MAD-MAX) for Automated LLM Red Teaming. MAD-MAX uses automatic assignment of attack strategies into relevant attack clusters, chooses the most relevant clusters for a malicious goal, and then combines strategies from the selected clusters to achieve diverse novel attacks with high attack success rates. MAD-MAX further merges promising attacks together at each iteration of Red Teaming to boost performance and introduces a similarity filter to prune out similar attacks for increased cost efficiency. The MAD-MAX approach is designed to be easily extensible with newly discovered attack strategies and outperforms the prominent Red Teaming method Tree of Attacks with Pruning (TAP) significantly in terms of Attack Success Rate (ASR) and queries needed to achieve jailbreaks. MAD-MAX jailbreaks 97% of malicious goals in our benchmarks on GPT-4o and Gemini-Pro compared to TAP with 66%. MAD-MAX does so with only 10.9 average queries to the target LLM compared to TAP with 23.3. WARNING: This paper contains contents which are offensive in nature.
Random Walk Guided Hyperbolic Graph Distillation
Jan 26, 2025



Graph distillation (GD) is an effective approach to extract useful information from large-scale network structures. However, existing methods, which operate in Euclidean space to generate condensed graphs, struggle to capture the inherent tree-like geometry of real-world networks, resulting in distilled graphs with limited task-specific information for downstream tasks. Furthermore, these methods often fail to extract dynamic properties from graphs, which are crucial for understanding information flow and facilitating graph continual learning. This paper presents the Hyperbolic Graph Distillation with Random Walks Optimization (HyDRO), a novel graph distillation approach that leverages hyperbolic embeddings to capture complex geometric patterns and optimize the spectral gap in hyperbolic space. Experiments show that HyDRO demonstrates strong task generalization, consistently outperforming state-of-the-art methods in both node classification and link prediction tasks. HyDRO also effectively preserves graph random walk properties, producing condensed graphs that achieve enhanced performance in continual graph learning. Additionally, HyDRO achieves competitive results on mainstream graph distillation benchmarks, while maintaining a strong balance between privacy and utility, and exhibiting robust resistance to noises.
Learning to Forget using Hypernetworks
Dec 01, 2024



Machine unlearning is gaining increasing attention as a way to remove adversarial data poisoning attacks from already trained models and to comply with privacy and AI regulations. The objective is to unlearn the effect of undesired data from a trained model while maintaining performance on the remaining data. This paper introduces HyperForget, a novel machine unlearning framework that leverages hypernetworks - neural networks that generate parameters for other networks - to dynamically sample models that lack knowledge of targeted data while preserving essential capabilities. Leveraging diffusion models, we implement two Diffusion HyperForget Networks and used them to sample unlearned models in Proof-of-Concept experiments. The unlearned models obtained zero accuracy on the forget set, while preserving good accuracy on the retain sets, highlighting the potential of HyperForget for dynamic targeted data removal and a promising direction for developing adaptive machine unlearning algorithms.
Agentic LLMs in the Supply Chain: Towards Autonomous Multi-Agent Consensus-Seeking
Nov 15, 2024



This paper explores how Large Language Models (LLMs) can automate consensus-seeking in supply chain management (SCM), where frequent decisions on problems such as inventory levels and delivery times require coordination among companies. Traditional SCM relies on human consensus in decision-making to avoid emergent problems like the bullwhip effect. Some routine consensus processes, especially those that are time-intensive and costly, can be automated. Existing solutions for automated coordination have faced challenges due to high entry barriers locking out SMEs, limited capabilities, and limited adaptability in complex scenarios. However, recent advances in Generative AI, particularly LLMs, show promise in overcoming these barriers. LLMs, trained on vast datasets can negotiate, reason, and plan, facilitating near-human-level consensus at scale with minimal entry barriers. In this work, we identify key limitations in existing approaches and propose autonomous LLM agents to address these gaps. We introduce a series of novel, supply chain-specific consensus-seeking frameworks tailored for LLM agents and validate the effectiveness of our approach through a case study in inventory management. To accelerate progress within the SCM community, we open-source our code, providing a foundation for further advancements in LLM-powered autonomous supply chain solutions.
ConDa: Fast Federated Unlearning with Contribution Dampening
Oct 05, 2024



Federated learning (FL) has enabled collaborative model training across decentralized data sources or clients. While adding new participants to a shared model does not pose great technical hurdles, the removal of a participant and their related information contained in the shared model remains a challenge. To address this problem, federated unlearning has emerged as a critical research direction, seeking to remove information from globally trained models without harming the model performance on the remaining data. Most modern federated unlearning methods use costly approaches such as the use of remaining clients data to retrain the global model or methods that would require heavy computation on client or server side. We introduce Contribution Dampening (ConDa), a framework that performs efficient unlearning by tracking down the parameters which affect the global model for each client and performs synaptic dampening on the parameters of the global model that have privacy infringing contributions from the forgetting client. Our technique does not require clients data or any kind of retraining and it does not put any computational overhead on either the client or server side. We perform experiments on multiple datasets and demonstrate that ConDa is effective to forget a client's data. In experiments conducted on the MNIST, CIFAR10, and CIFAR100 datasets, ConDa proves to be the fastest federated unlearning method, outperforming the nearest state of the art approach by at least 100x. Our emphasis is on the non-IID Federated Learning setting, which presents the greatest challenge for unlearning. Additionally, we validate ConDa's robustness through backdoor and membership inference attacks. We envision this work as a crucial component for FL in adhering to legal and ethical requirements.
Potion: Towards Poison Unlearning
Jun 13, 2024Adversarial attacks by malicious actors on machine learning systems, such as introducing poison triggers into training datasets, pose significant risks. The challenge in resolving such an attack arises in practice when only a subset of the poisoned data can be identified. This necessitates the development of methods to remove, i.e. unlearn, poison triggers from already trained models with only a subset of the poison data available. The requirements for this task significantly deviate from privacy-focused unlearning where all of the data to be forgotten by the model is known. Previous work has shown that the undiscovered poisoned samples lead to a failure of established unlearning methods, with only one method, Selective Synaptic Dampening (SSD), showing limited success. Even full retraining, after the removal of the identified poison, cannot address this challenge as the undiscovered poison samples lead to a reintroduction of the poison trigger in the model. Our work addresses two key challenges to advance the state of the art in poison unlearning. First, we introduce a novel outlier-resistant method, based on SSD, that significantly improves model protection and unlearning performance. Second, we introduce Poison Trigger Neutralisation (PTN) search, a fast, parallelisable, hyperparameter search that utilises the characteristic "unlearning versus model protection" trade-off to find suitable hyperparameters in settings where the forget set size is unknown and the retain set is contaminated. We benchmark our contributions using ResNet-9 on CIFAR10 and WideResNet-28x10 on CIFAR100. Experimental results show that our method heals 93.72% of poison compared to SSD with 83.41% and full retraining with 40.68%. We achieve this while also lowering the average model accuracy drop caused by unlearning from 5.68% (SSD) to 1.41% (ours).
Loss-Free Machine Unlearning
Feb 29, 2024We present a machine unlearning approach that is both retraining- and label-free. Most existing machine unlearning approaches require a model to be fine-tuned to remove information while preserving performance. This is computationally expensive and necessitates the storage of the whole dataset for the lifetime of the model. Retraining-free approaches often utilise Fisher information, which is derived from the loss and requires labelled data which may not be available. Thus, we present an extension to the Selective Synaptic Dampening algorithm, substituting the diagonal of the Fisher information matrix for the gradient of the l2 norm of the model output to approximate sensitivity. We evaluate our method in a range of experiments using ResNet18 and Vision Transformer. Results show our label-free method is competitive with existing state-of-the-art approaches.
Parameter-tuning-free data entry error unlearning with adaptive selective synaptic dampening
Feb 06, 2024



Data entry constitutes a fundamental component of the machine learning pipeline, yet it frequently results in the introduction of labelling errors. When a model has been trained on a dataset containing such errors its performance is reduced. This leads to the challenge of efficiently unlearning the influence of the erroneous data to improve the model performance without needing to completely retrain the model. While model editing methods exist for cases in which the correct label for a wrong entry is known, we focus on the case of data entry errors where we do not know the correct labels for the erroneous data. Our contribution is twofold. First, we introduce an extension to the selective synaptic dampening unlearning method that removes the need for parameter tuning, making unlearning accessible to practitioners. We demonstrate the performance of this extension, adaptive selective synaptic dampening (ASSD), on various ResNet18 and Vision Transformer unlearning tasks. Second, we demonstrate the performance of ASSD in a supply chain delay prediction problem with labelling errors using real-world data where we randomly introduce various levels of labelling errors. The application of this approach is particularly compelling in industrial settings, such as supply chain management, where a significant portion of data entry occurs manually through Excel sheets, rendering it error-prone. ASSD shows strong performance on general unlearning benchmarks and on the error correction problem where it outperforms fine-tuning for error correction.
Zero-Shot Machine Unlearning at Scale via Lipschitz Regularization
Feb 05, 2024



To comply with AI and data regulations, the need to forget private or copyrighted information from trained machine learning models is increasingly important. The key challenge in unlearning is forgetting the necessary data in a timely manner, while preserving model performance. In this work, we address the zero-shot unlearning scenario, whereby an unlearning algorithm must be able to remove data given only a trained model and the data to be forgotten. Under such a definition, existing state-of-the-art methods are insufficient. Building on the concepts of Lipschitz continuity, we present a method that induces smoothing of the forget sample's output, with respect to perturbations of that sample. We show this smoothing successfully results in forgetting while preserving general model performance. We perform extensive empirical evaluation of our method over a range of contemporary benchmarks, verifying that our method achieves state-of-the-art performance under the strict constraints of zero-shot unlearning.