 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Space Generative Models for One-Shot Class-Incremental Learning
Jan 25, 2026Few-shot class-incremental learning (FSCIL) is a paradigm where a model, initially trained on a dataset of base classes, must adapt to an expanding problem space by recognizing novel classes with limited data. We focus on the challenging FSCIL setup where a model receives only a single sample (1-shot) for each novel class and no further training or model alterations are allowed after the base training phase. This makes generalization to novel classes particularly difficult. We propose a novel approach predicated on the hypothesis that base and novel class embeddings have structural similarity. We map the original embedding space into a residual space by subtracting the class prototype (i.e., the average class embedding) of input samples. Then, we leverage generative modeling with VAE or diffusion models to learn the multi-modal distribution of residuals over the base classes, and we use this as a valuable structural prior to improve recognition of novel classes. Our approach, Gen1S, consistently improves novel class recognition over the state of the art across multiple benchmarks and backbone architectures.
Twist and Compute: The Cost of Pose in 3D Generative Diffusion
Nov 11, 2025

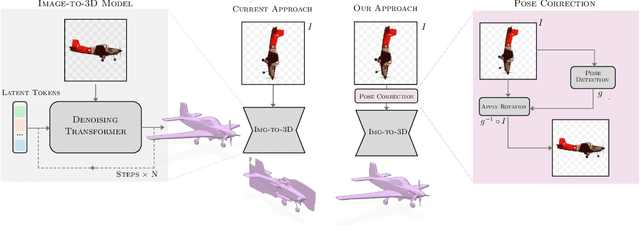

Despite their impressive results, large-scale image-to-3D generative models remain opaque in their inductive biases. We identify a significant limitation in image-conditioned 3D generative models: a strong canonical view bias. Through controlled experiments using simple 2D rotations, we show that the state-of-the-art Hunyuan3D 2.0 model can struggle to generalize across viewpoints, with performance degrading under rotated inputs. We show that this failure can be mitigated by a lightweight CNN that detects and corrects input orientation, restoring model performance without modifying the generative backbone. Our findings raise an important open question: Is scale enough, or should we pursue modular, symmetry-aware designs?
Learning to Forget using Hypernetworks
Dec 01, 2024



Machine unlearning is gaining increasing attention as a way to remove adversarial data poisoning attacks from already trained models and to comply with privacy and AI regulations. The objective is to unlearn the effect of undesired data from a trained model while maintaining performance on the remaining data. This paper introduces HyperForget, a novel machine unlearning framework that leverages hypernetworks - neural networks that generate parameters for other networks - to dynamically sample models that lack knowledge of targeted data while preserving essential capabilities. Leveraging diffusion models, we implement two Diffusion HyperForget Networks and used them to sample unlearned models in Proof-of-Concept experiments. The unlearned models obtained zero accuracy on the forget set, while preserving good accuracy on the retain sets, highlighting the potential of HyperForget for dynamic targeted data removal and a promising direction for developing adaptive machine unlearning algorithms.
Potion: Towards Poison Unlearning
Jun 13, 2024Adversarial attacks by malicious actors on machine learning systems, such as introducing poison triggers into training datasets, pose significant risks. The challenge in resolving such an attack arises in practice when only a subset of the poisoned data can be identified. This necessitates the development of methods to remove, i.e. unlearn, poison triggers from already trained models with only a subset of the poison data available. The requirements for this task significantly deviate from privacy-focused unlearning where all of the data to be forgotten by the model is known. Previous work has shown that the undiscovered poisoned samples lead to a failure of established unlearning methods, with only one method, Selective Synaptic Dampening (SSD), showing limited success. Even full retraining, after the removal of the identified poison, cannot address this challenge as the undiscovered poison samples lead to a reintroduction of the poison trigger in the model. Our work addresses two key challenges to advance the state of the art in poison unlearning. First, we introduce a novel outlier-resistant method, based on SSD, that significantly improves model protection and unlearning performance. Second, we introduce Poison Trigger Neutralisation (PTN) search, a fast, parallelisable, hyperparameter search that utilises the characteristic "unlearning versus model protection" trade-off to find suitable hyperparameters in settings where the forget set size is unknown and the retain set is contaminated. We benchmark our contributions using ResNet-9 on CIFAR10 and WideResNet-28x10 on CIFAR100. Experimental results show that our method heals 93.72% of poison compared to SSD with 83.41% and full retraining with 40.68%. We achieve this while also lowering the average model accuracy drop caused by unlearning from 5.68% (SSD) to 1.41% (ours).
Loss-Free Machine Unlearning
Feb 29, 2024We present a machine unlearning approach that is both retraining- and label-free. Most existing machine unlearning approaches require a model to be fine-tuned to remove information while preserving performance. This is computationally expensive and necessitates the storage of the whole dataset for the lifetime of the model. Retraining-free approaches often utilise Fisher information, which is derived from the loss and requires labelled data which may not be available. Thus, we present an extension to the Selective Synaptic Dampening algorithm, substituting the diagonal of the Fisher information matrix for the gradient of the l2 norm of the model output to approximate sensitivity. We evaluate our method in a range of experiments using ResNet18 and Vision Transformer. Results show our label-free method is competitive with existing state-of-the-art approaches.
Parameter-tuning-free data entry error unlearning with adaptive selective synaptic dampening
Feb 06, 2024



Data entry constitutes a fundamental component of the machine learning pipeline, yet it frequently results in the introduction of labelling errors. When a model has been trained on a dataset containing such errors its performance is reduced. This leads to the challenge of efficiently unlearning the influence of the erroneous data to improve the model performance without needing to completely retrain the model. While model editing methods exist for cases in which the correct label for a wrong entry is known, we focus on the case of data entry errors where we do not know the correct labels for the erroneous data. Our contribution is twofold. First, we introduce an extension to the selective synaptic dampening unlearning method that removes the need for parameter tuning, making unlearning accessible to practitioners. We demonstrate the performance of this extension, adaptive selective synaptic dampening (ASSD), on various ResNet18 and Vision Transformer unlearning tasks. Second, we demonstrate the performance of ASSD in a supply chain delay prediction problem with labelling errors using real-world data where we randomly introduce various levels of labelling errors. The application of this approach is particularly compelling in industrial settings, such as supply chain management, where a significant portion of data entry occurs manually through Excel sheets, rendering it error-prone. ASSD shows strong performance on general unlearning benchmarks and on the error correction problem where it outperforms fine-tuning for error correction.
Zero-Shot Machine Unlearning at Scale via Lipschitz Regularization
Feb 05, 2024



To comply with AI and data regulations, the need to forget private or copyrighted information from trained machine learning models is increasingly important. The key challenge in unlearning is forgetting the necessary data in a timely manner, while preserving model performance. In this work, we address the zero-shot unlearning scenario, whereby an unlearning algorithm must be able to remove data given only a trained model and the data to be forgotten. Under such a definition, existing state-of-the-art methods are insufficient. Building on the concepts of Lipschitz continuity, we present a method that induces smoothing of the forget sample's output, with respect to perturbations of that sample. We show this smoothing successfully results in forgetting while preserving general model performance. We perform extensive empirical evaluation of our method over a range of contemporary benchmarks, verifying that our method achieves state-of-the-art performance under the strict constraints of zero-shot unlearning.
Towards Robust Continual Learning with Bayesian Adaptive Moment Regularization
Sep 15, 2023The pursuit of long-term autonomy mandates that robotic agents must continuously adapt to their changing environments and learn to solve new tasks. Continual learning seeks to overcome the challenge of catastrophic forgetting, where learning to solve new tasks causes a model to forget previously learnt information. Prior-based continual learning methods are appealing for robotic applications as they are space efficient and typically do not increase in computational complexity as the number of tasks grows. Despite these desirable properties, prior-based approaches typically fail on important benchmarks and consequently are limited in their potential applications compared to their memory-based counterparts. We introduce Bayesian adaptive moment regularization (BAdam), a novel prior-based method that better constrains parameter growth, leading to lower catastrophic forgetting. Our method boasts a range of desirable properties for robotic applications such as being lightweight and task label-free, converging quickly, and offering calibrated uncertainty that is important for safe real-world deployment. Results show that BAdam achieves state-of-the-art performance for prior-based methods on challenging single-headed class-incremental experiments such as Split MNIST and Split FashionMNIST, and does so without relying on task labels or discrete task boundaries.
Fast Machine Unlearning Without Retraining Through Selective Synaptic Dampening
Aug 15, 2023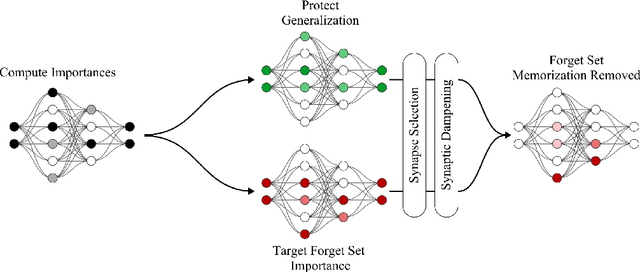



Machine unlearning, the ability for a machine learning model to forget, is becoming increasingly important to comply with data privacy regulations, as well as to remove harmful, manipulated, or outdated information. The key challenge lies in forgetting specific information while protecting model performance on the remaining data. While current state-of-the-art methods perform well, they typically require some level of retraining over the retained data, in order to protect or restore model performance. This adds computational overhead and mandates that the training data remain available and accessible, which may not be feasible. In contrast, other methods employ a retrain-free paradigm, however, these approaches are prohibitively computationally expensive and do not perform on par with their retrain-based counterparts. We present Selective Synaptic Dampening (SSD), a novel two-step, post hoc, retrain-free approach to machine unlearning which is fast, performant, and does not require long-term storage of the training data. First, SSD uses the Fisher information matrix of the training and forgetting data to select parameters that are disproportionately important to the forget set. Second, SSD induces forgetting by dampening these parameters proportional to their relative importance to the forget set with respect to the wider training data. We evaluate our method against several existing unlearning methods in a range of experiments using ResNet18 and Vision Transformer. Results show that the performance of SSD is competitive with retrain-based post hoc methods, demonstrating the viability of retrain-free post hoc unlearning approaches.
Identifying contributors to supply chain outcomes in a multi-echelon setting: a decentralised approach
Jul 22, 2023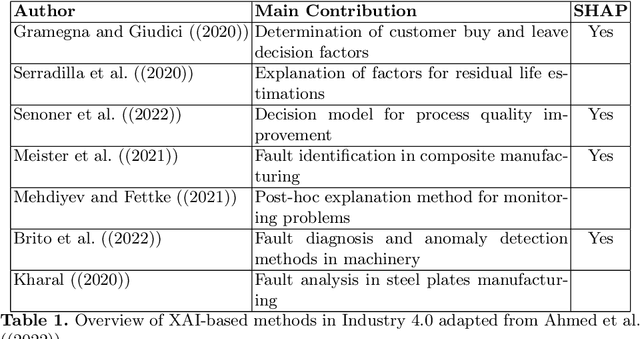
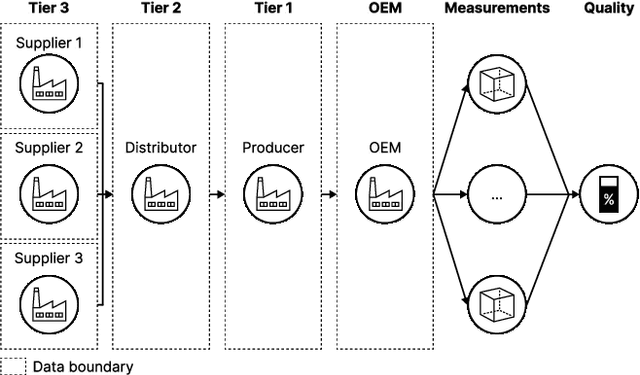


Organisations often struggle to identify the causes of change in metrics such as product quality and delivery duration. This task becomes increasingly challenging when the cause lies outside of company borders in multi-echelon supply chains that are only partially observable. Although traditional supply chain management has advocated for data sharing to gain better insights, this does not take place in practice due to data privacy concerns. We propose the use of explainable artificial intelligence for decentralised computing of estimated contributions to a metric of interest in a multi-stage production process. This approach mitigates the need to convince supply chain actors to share data, as all computations occur in a decentralised manner. Our method is empirically validated using data collected from a real multi-stage manufacturing process. The results demonstrate the effectiveness of our approach in detecting the source of quality variations compared to a centralised approach using Shapley additive explanations.