 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwist and Compute: The Cost of Pose in 3D Generative Diffusion
Nov 11, 2025

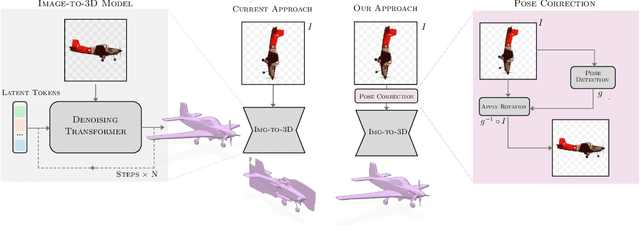

Despite their impressive results, large-scale image-to-3D generative models remain opaque in their inductive biases. We identify a significant limitation in image-conditioned 3D generative models: a strong canonical view bias. Through controlled experiments using simple 2D rotations, we show that the state-of-the-art Hunyuan3D 2.0 model can struggle to generalize across viewpoints, with performance degrading under rotated inputs. We show that this failure can be mitigated by a lightweight CNN that detects and corrects input orientation, restoring model performance without modifying the generative backbone. Our findings raise an important open question: Is scale enough, or should we pursue modular, symmetry-aware designs?
Self-Supervised Implicit Attention Priors for Point Cloud Reconstruction
Nov 06, 2025Recovering high-quality surfaces from irregular point cloud is ill-posed unless strong geometric priors are available. We introduce an implicit self-prior approach that distills a shape-specific prior directly from the input point cloud itself and embeds it within an implicit neural representation. This is achieved by jointly training a small dictionary of learnable embeddings with an implicit distance field; at every query location, the field attends to the dictionary via cross-attention, enabling the network to capture and reuse repeating structures and long-range correlations inherent to the shape. Optimized solely with self-supervised point cloud reconstruction losses, our approach requires no external training data. To effectively integrate this learned prior while preserving input fidelity, the trained field is then sampled to extract densely distributed points and analytic normals via automatic differentiation. We integrate the resulting dense point cloud and corresponding normals into a robust implicit moving least squares (RIMLS) formulation. We show this hybrid strategy preserves fine geometric details in the input data, while leveraging the learned prior to regularize sparse regions. Experiments show that our method outperforms both classical and learning-based approaches in generating high-fidelity surfaces with superior detail preservation and robustness to common data degradations.
Best Foot Forward: Robust Foot Reconstruction in-the-wild
Feb 27, 2025Accurate 3D foot reconstruction is crucial for personalized orthotics, digital healthcare, and virtual fittings. However, existing methods struggle with incomplete scans and anatomical variations, particularly in self-scanning scenarios where user mobility is limited, making it difficult to capture areas like the arch and heel. We present a novel end-to-end pipeline that refines Structure-from-Motion (SfM) reconstruction. It first resolves scan alignment ambiguities using SE(3) canonicalization with a viewpoint prediction module, then completes missing geometry through an attention-based network trained on synthetically augmented point clouds. Our approach achieves state-of-the-art performance on reconstruction metrics while preserving clinically validated anatomical fidelity. By combining synthetic training data with learned geometric priors, we enable robust foot reconstruction under real-world capture conditions, unlocking new opportunities for mobile-based 3D scanning in healthcare and retail.
SYM3D: Learning Symmetric Triplanes for Better 3D-Awareness of GANs
Jun 10, 2024



Despite the growing success of 3D-aware GANs, which can be trained on 2D images to generate high-quality 3D assets, they still rely on multi-view images with camera annotations to synthesize sufficient details from all viewing directions. However, the scarce availability of calibrated multi-view image datasets, especially in comparison to single-view images, has limited the potential of 3D GANs. Moreover, while bypassing camera pose annotations with a camera distribution constraint reduces dependence on exact camera parameters, it still struggles to generate a consistent orientation of 3D assets. To this end, we propose SYM3D, a novel 3D-aware GAN designed to leverage the prevalent reflectional symmetry structure found in natural and man-made objects, alongside a proposed view-aware spatial attention mechanism in learning the 3D representation. We evaluate SYM3D on both synthetic (ShapeNet Chairs, Cars, and Airplanes) and real-world datasets (ABO-Chair), demonstrating its superior performance in capturing detailed geometry and texture, even when trained on only single-view images. Finally, we demonstrate the effectiveness of incorporating symmetry regularization in helping reduce artifacts in the modeling of 3D assets in the text-to-3D task.
Zero-Shot Machine Unlearning at Scale via Lipschitz Regularization
Feb 05, 2024



To comply with AI and data regulations, the need to forget private or copyrighted information from trained machine learning models is increasingly important. The key challenge in unlearning is forgetting the necessary data in a timely manner, while preserving model performance. In this work, we address the zero-shot unlearning scenario, whereby an unlearning algorithm must be able to remove data given only a trained model and the data to be forgotten. Under such a definition, existing state-of-the-art methods are insufficient. Building on the concepts of Lipschitz continuity, we present a method that induces smoothing of the forget sample's output, with respect to perturbations of that sample. We show this smoothing successfully results in forgetting while preserving general model performance. We perform extensive empirical evaluation of our method over a range of contemporary benchmarks, verifying that our method achieves state-of-the-art performance under the strict constraints of zero-shot unlearning.
FrePolad: Frequency-Rectified Point Latent Diffusion for Point Cloud Generation
Nov 20, 2023



We propose FrePolad: frequency-rectified point latent diffusion, a point cloud generation pipeline integrating a variational autoencoder (VAE) with a denoising diffusion probabilistic model (DDPM) for the latent distribution. FrePolad simultaneously achieves high quality, diversity, and flexibility in point cloud cardinality for generation tasks while maintaining high computational efficiency. The improvement in generation quality and diversity is achieved through (1) a novel frequency rectification module via spherical harmonics designed to retain high-frequency content while learning the point cloud distribution; and (2) a latent DDPM to learn the regularized yet complex latent distribution. In addition, FrePolad supports variable point cloud cardinality by formulating the sampling of points as conditional distributions over a latent shape distribution. Finally, the low-dimensional latent space encoded by the VAE contributes to FrePolad's fast and scalable sampling. Our quantitative and qualitative results demonstrate the state-of-the-art performance of FrePolad in terms of quality, diversity, and computational efficiency.
Neural Fields with Hard Constraints of Arbitrary Differential Order
Jun 15, 2023



While deep learning techniques have become extremely popular for solving a broad range of optimization problems, methods to enforce hard constraints during optimization, particularly on deep neural networks, remain underdeveloped. Inspired by the rich literature on meshless interpolation and its extension to spectral collocation methods in scientific computing, we develop a series of approaches for enforcing hard constraints on neural fields, which we refer to as \emph{Constrained Neural Fields} (CNF). The constraints can be specified as a linear operator applied to the neural field and its derivatives. We also design specific model representations and training strategies for problems where standard models may encounter difficulties, such as conditioning of the system, memory consumption, and capacity of the network when being constrained. Our approaches are demonstrated in a wide range of real-world applications. Additionally, we develop a framework that enables highly efficient model and constraint specification, which can be readily applied to any downstream task where hard constraints need to be explicitly satisfied during optimization.