 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseCraft: Tokenized 3D Body Landmark and Camera Conditioning for Photorealistic Human Image Synthesis
Feb 22, 2026Digitizing humans and synthesizing photorealistic avatars with explicit 3D pose and camera controls are central to VR, telepresence, and entertainment. Existing skinning-based workflows require laborious manual rigging or template-based fittings, while neural volumetric methods rely on canonical templates and re-optimization for each unseen pose. We present PoseCraft, a diffusion framework built around tokenized 3D interface: instead of relying only on rasterized geometry as 2D control images, we encode sparse 3D landmarks and camera extrinsics as discrete conditioning tokens and inject them into diffusion via cross-attention. Our approach preserves 3D semantics by avoiding 2D re-projection ambiguity under large pose and viewpoint changes, and produces photorealistic imagery that faithfully captures identity and appearance. To train and evaluate at scale, we also implement GenHumanRF, a data generation workflow that renders diverse supervision from volumetric reconstructions. Our experiments show that PoseCraft achieves significant perceptual quality improvement over diffusion-centric methods, and attains better or comparable metrics to latest volumetric rendering SOTA while better preserving fabric and hair details.
Quartet of Diffusions: Structure-Aware Point Cloud Generation through Part and Symmetry Guidance
Jan 28, 2026We introduce the Quartet of Diffusions, a structure-aware point cloud generation framework that explicitly models part composition and symmetry. Unlike prior methods that treat shape generation as a holistic process or only support part composition, our approach leverages four coordinated diffusion models to learn distributions of global shape latents, symmetries, semantic parts, and their spatial assembly. This structured pipeline ensures guaranteed symmetry, coherent part placement, and diverse, high-quality outputs. By disentangling the generative process into interpretable components, our method supports fine-grained control over shape attributes, enabling targeted manipulation of individual parts while preserving global consistency. A central global latent further reinforces structural coherence across assembled parts. Our experiments show that the Quartet achieves state-of-the-art performance. To our best knowledge, this is the first 3D point cloud generation framework that fully integrates and enforces both symmetry and part priors throughout the generative process.
Features Emerge as Discrete States: The First Application of SAEs to 3D Representations
Dec 15, 2025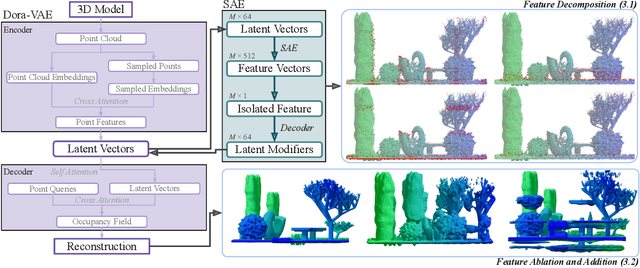

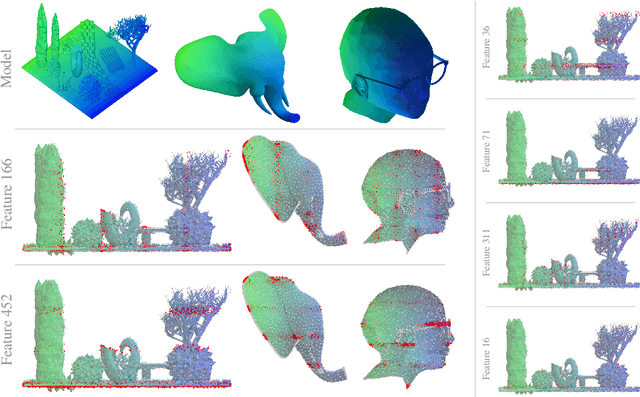
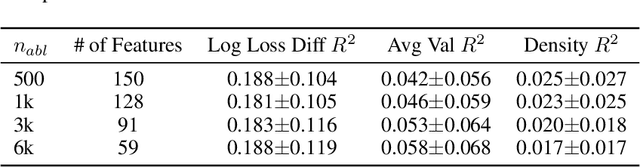
Sparse Autoencoders (SAEs) are a powerful dictionary learning technique for decomposing neural network activations, translating the hidden state into human ideas with high semantic value despite no external intervention or guidance. However, this technique has rarely been applied outside of the textual domain, limiting theoretical explorations of feature decomposition. We present the first application of SAEs to the 3D domain, analyzing the features used by a state-of-the-art 3D reconstruction VAE applied to 53k 3D models from the Objaverse dataset. We observe that the network encodes discrete rather than continuous features, leading to our key finding: such models approximate a discrete state space, driven by phase-like transitions from feature activations. Through this state transition framework, we address three otherwise unintuitive behaviors - the inclination of the reconstruction model towards positional encoding representations, the sigmoidal behavior of reconstruction loss from feature ablation, and the bimodality in the distribution of phase transition points. This final observation suggests the model redistributes the interference caused by superposition to prioritize the saliency of different features. Our work not only compiles and explains unexpected phenomena regarding feature decomposition, but also provides a framework to explain the model's feature learning dynamics. The code and dataset of encoded 3D objects will be available on release.
Multigranular Evaluation for Brain Visual Decoding
Jul 10, 2025Existing evaluation protocols for brain visual decoding predominantly rely on coarse metrics that obscure inter-model differences, lack neuroscientific foundation, and fail to capture fine-grained visual distinctions. To address these limitations, we introduce BASIC, a unified, multigranular evaluation framework that jointly quantifies structural fidelity, inferential alignment, and contextual coherence between decoded and ground truth images. For the structural level, we introduce a hierarchical suite of segmentation-based metrics, including foreground, semantic, instance, and component masks, anchored in granularity-aware correspondence across mask structures. For the semantic level, we extract structured scene representations encompassing objects, attributes, and relationships using multimodal large language models, enabling detailed, scalable, and context-rich comparisons with ground-truth stimuli. We benchmark a diverse set of visual decoding methods across multiple stimulus-neuroimaging datasets within this unified evaluation framework. Together, these criteria provide a more discriminative, interpretable, and comprehensive foundation for measuring brain visual decoding methods.
Restereo: Diffusion stereo video generation and restoration
Jun 06, 2025Stereo video generation has been gaining increasing attention with recent advancements in video diffusion models. However, most existing methods focus on generating 3D stereoscopic videos from monocular 2D videos. These approaches typically assume that the input monocular video is of high quality, making the task primarily about inpainting occluded regions in the warped video while preserving disoccluded areas. In this paper, we introduce a new pipeline that not only generates stereo videos but also enhances both left-view and right-view videos consistently with a single model. Our approach achieves this by fine-tuning the model on degraded data for restoration, as well as conditioning the model on warped masks for consistent stereo generation. As a result, our method can be fine-tuned on a relatively small synthetic stereo video datasets and applied to low-quality real-world videos, performing both stereo video generation and restoration. Experiments demonstrate that our method outperforms existing approaches both qualitatively and quantitatively in stereo video generation from low-resolution inputs.
Exploring The Visual Feature Space for Multimodal Neural Decoding
May 21, 2025The intrication of brain signals drives research that leverages multimodal AI to align brain modalities with visual and textual data for explainable descriptions. However, most existing studies are limited to coarse interpretations, lacking essential details on object descriptions, locations, attributes, and their relationships. This leads to imprecise and ambiguous reconstructions when using such cues for visual decoding. To address this, we analyze different choices of vision feature spaces from pre-trained visual components within Multimodal Large Language Models (MLLMs) and introduce a zero-shot multimodal brain decoding method that interacts with these models to decode across multiple levels of granularities. % To assess a model's ability to decode fine details from brain signals, we propose the Multi-Granularity Brain Detail Understanding Benchmark (MG-BrainDub). This benchmark includes two key tasks: detailed descriptions and salient question-answering, with metrics highlighting key visual elements like objects, attributes, and relationships. Our approach enhances neural decoding precision and supports more accurate neuro-decoding applications. Code will be available at https://github.com/weihaox/VINDEX.
RETRO: REthinking Tactile Representation Learning with Material PriOrs
May 20, 2025
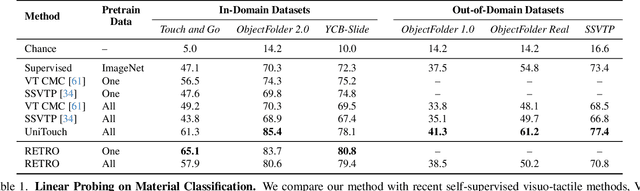
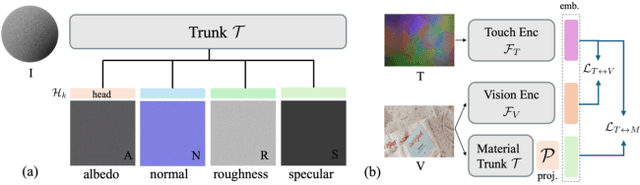
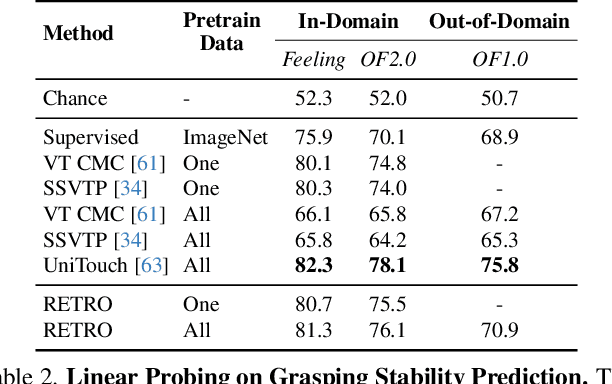
Tactile perception is profoundly influenced by the surface properties of objects in contact. However, despite their crucial role in shaping tactile experiences, these material characteristics have been largely neglected in existing tactile representation learning methods. Most approaches primarily focus on aligning tactile data with visual or textual information, overlooking the richness of tactile feedback that comes from understanding the materials' inherent properties. In this work, we address this gap by revisiting the tactile representation learning framework and incorporating material-aware priors into the learning process. These priors, which represent pre-learned characteristics specific to different materials, allow tactile models to better capture and generalize the nuances of surface texture. Our method enables more accurate, contextually rich tactile feedback across diverse materials and textures, improving performance in real-world applications such as robotics, haptic feedback systems, and material editing.
Best Foot Forward: Robust Foot Reconstruction in-the-wild
Feb 27, 2025Accurate 3D foot reconstruction is crucial for personalized orthotics, digital healthcare, and virtual fittings. However, existing methods struggle with incomplete scans and anatomical variations, particularly in self-scanning scenarios where user mobility is limited, making it difficult to capture areas like the arch and heel. We present a novel end-to-end pipeline that refines Structure-from-Motion (SfM) reconstruction. It first resolves scan alignment ambiguities using SE(3) canonicalization with a viewpoint prediction module, then completes missing geometry through an attention-based network trained on synthetically augmented point clouds. Our approach achieves state-of-the-art performance on reconstruction metrics while preserving clinically validated anatomical fidelity. By combining synthetic training data with learned geometric priors, we enable robust foot reconstruction under real-world capture conditions, unlocking new opportunities for mobile-based 3D scanning in healthcare and retail.
Feed-Forward Bullet-Time Reconstruction of Dynamic Scenes from Monocular Videos
Dec 04, 2024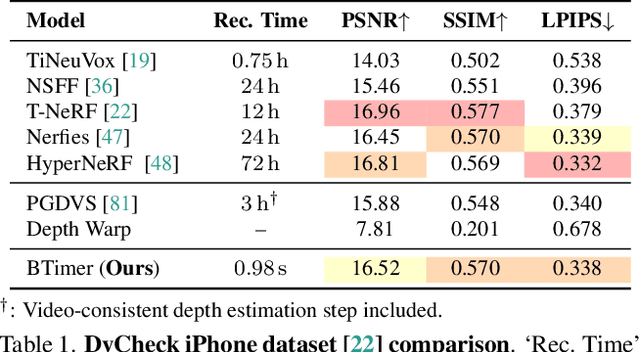
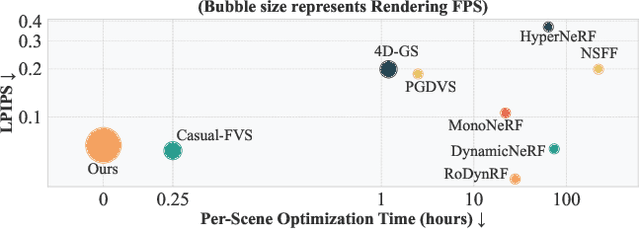
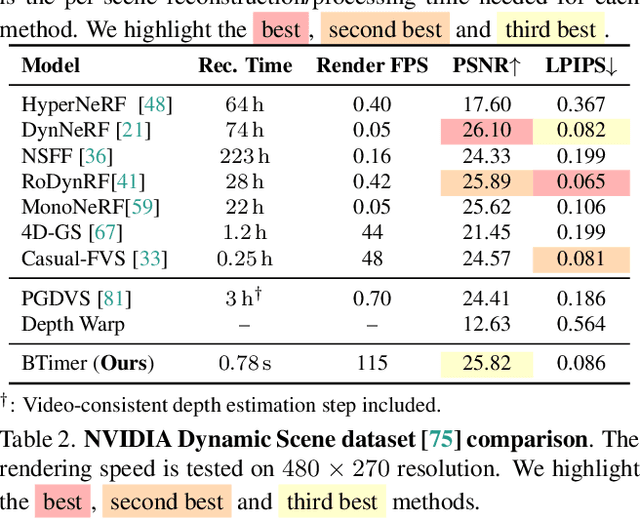
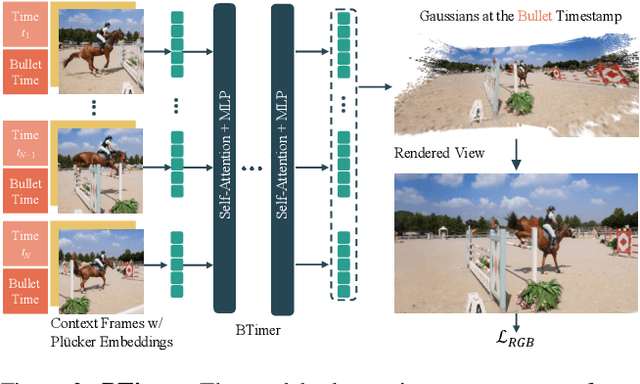
Recent advancements in static feed-forward scene reconstruction have demonstrated significant progress in high-quality novel view synthesis. However, these models often struggle with generalizability across diverse environments and fail to effectively handle dynamic content. We present BTimer (short for BulletTimer), the first motion-aware feed-forward model for real-time reconstruction and novel view synthesis of dynamic scenes. Our approach reconstructs the full scene in a 3D Gaussian Splatting representation at a given target ('bullet') timestamp by aggregating information from all the context frames. Such a formulation allows BTimer to gain scalability and generalization by leveraging both static and dynamic scene datasets. Given a casual monocular dynamic video, BTimer reconstructs a bullet-time scene within 150ms while reaching state-of-the-art performance on both static and dynamic scene datasets, even compared with optimization-based approaches.
Physically Based Neural Bidirectional Reflectance Distribution Function
Nov 04, 2024We introduce the physically based neural bidirectional reflectance distribution function (PBNBRDF), a novel, continuous representation for material appearance based on neural fields. Our model accurately reconstructs real-world materials while uniquely enforcing physical properties for realistic BRDFs, specifically Helmholtz reciprocity via reparametrization and energy passivity via efficient analytical integration. We conduct a systematic analysis demonstrating the benefits of adhering to these physical laws on the visual quality of reconstructed materials. Additionally, we enhance the color accuracy of neural BRDFs by introducing chromaticity enforcement supervising the norms of RGB channels. Through both qualitative and quantitative experiments on multiple databases of measured real-world BRDFs, we show that adhering to these physical constraints enables neural fields to more faithfully and stably represent the original data and achieve higher rendering quality.