 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointDiT: Pixel-Space Diffusion for Monocular Geometry Estimation
Jul 02, 2026State-of-the-art single-image 3D reconstruction methods often rely on complex hybrid architectures and loss functions, or compress geometry into latent spaces in order to leverage pre-trained latent diffusion models. In this work, we show that such architectural overhead and intricate loss formulations are unnecessary. We introduce a minimalist pixel-space Diffusion Transformer, built on a plain ViT, that operates directly on raw 3D point map patches and is conditioned on image tokens from a pre-trained DINOv3. Unlike existing latent diffusion approaches, we train our diffusion backbone entirely from scratch, eliminating the need for point map tokenizers. Despite its simplicity, our approach surpasses complex latent-based diffusion models while remaining significantly simpler than hybrid alternatives. Notably, it produces sharper geometric structure and is more robust in highly ambiguous regions, such as transparent objects.
Good Token Hunting: A Hitchhiker's Guide to Token Selection for Visual Geometry Transformers
May 22, 2026Visual geometry transformers have become powerful architectures for multi-view 3D reconstruction, enabling joint prediction of multiple 3D attributes in a feed-forward manner. However, their computational cost grows quadratically with the input sequence length due to the global attention layers inside these models. This limits both their scalability and efficiency. In this work, we address this challenge with a simple yet general strategy: restricting the number of key/value tokens that each query interacts with during global attention. To achieve effective token selection, we introduce a two-stage framework. First, an inter-frame selection step operates at the frame level to identify frames that should be preserved. Second, an intra-frame selection step further discards more redundant tokens within the selected frames. Our analysis highlights the advantage of a diversity-based strategy for inter-frame selection, which ensures broad coverage of the scene. For intra-frame selection, we show that layer-aware sparsification is necessary, with the selection process guided by the entropy of the global attention pattern. Our approach offers a superior speed-accuracy trade-off compared to existing solutions. Extensive experiments show that it accelerates visual geometry transformers by over 85% for scenes with 500 images while maintaining, or even improving, baseline performance, which hints that how our token selection strategy can play a crucial role in future applications of visual geometry transformers. Our project website is available at https://zsh2000.github.io/good-token-hunting.github.io.
Stepper: Stepwise Immersive Scene Generation with Multiview Panoramas
Mar 30, 2026The synthesis of immersive 3D scenes from text is rapidly maturing, driven by novel video generative models and feed-forward 3D reconstruction, with vast potential in AR/VR and world modeling. While panoramic images have proven effective for scene initialization, existing approaches suffer from a trade-off between visual fidelity and explorability: autoregressive expansion suffers from context drift, while panoramic video generation is limited to low resolution. We present Stepper, a unified framework for text-driven immersive 3D scene synthesis that circumvents these limitations via stepwise panoramic scene expansion. Stepper leverages a novel multi-view 360° diffusion model that enables consistent, high-resolution expansion, coupled with a geometry reconstruction pipeline that enforces geometric coherence. Trained on a new large-scale, multi-view panorama dataset, Stepper achieves state-of-the-art fidelity and structural consistency, outperforming prior approaches, thereby setting a new standard for immersive scene generation.
AnyUp: Universal Feature Upsampling
Oct 14, 2025
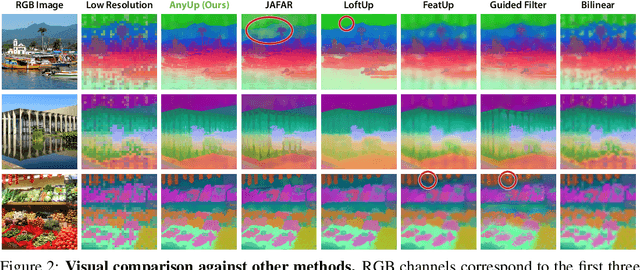

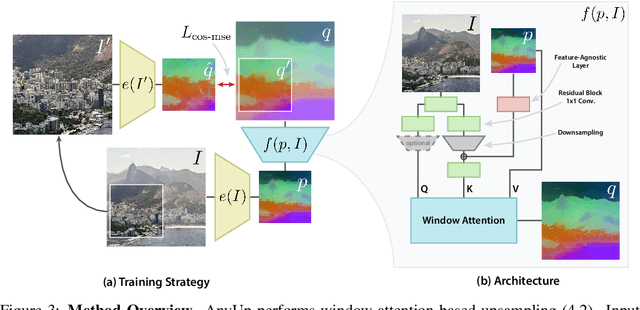
We introduce AnyUp, a method for feature upsampling that can be applied to any vision feature at any resolution, without encoder-specific training. Existing learning-based upsamplers for features like DINO or CLIP need to be re-trained for every feature extractor and thus do not generalize to different feature types at inference time. In this work, we propose an inference-time feature-agnostic upsampling architecture to alleviate this limitation and improve upsampling quality. In our experiments, AnyUp sets a new state of the art for upsampled features, generalizes to different feature types, and preserves feature semantics while being efficient and easy to apply to a wide range of downstream tasks.
CubeDiff: Repurposing Diffusion-Based Image Models for Panorama Generation
Jan 28, 2025We introduce a novel method for generating 360{\deg} panoramas from text prompts or images. Our approach leverages recent advances in 3D generation by employing multi-view diffusion models to jointly synthesize the six faces of a cubemap. Unlike previous methods that rely on processing equirectangular projections or autoregressive generation, our method treats each face as a standard perspective image, simplifying the generation process and enabling the use of existing multi-view diffusion models. We demonstrate that these models can be adapted to produce high-quality cubemaps without requiring correspondence-aware attention layers. Our model allows for fine-grained text control, generates high resolution panorama images and generalizes well beyond its training set, whilst achieving state-of-the-art results, both qualitatively and quantitatively. Project page: https://cubediff.github.io/
Gaussians-to-Life: Text-Driven Animation of 3D Gaussian Splatting Scenes
Nov 28, 2024

State-of-the-art novel view synthesis methods achieve impressive results for multi-view captures of static 3D scenes. However, the reconstructed scenes still lack "liveliness," a key component for creating engaging 3D experiences. Recently, novel video diffusion models generate realistic videos with complex motion and enable animations of 2D images, however they cannot naively be used to animate 3D scenes as they lack multi-view consistency. To breathe life into the static world, we propose Gaussians2Life, a method for animating parts of high-quality 3D scenes in a Gaussian Splatting representation. Our key idea is to leverage powerful video diffusion models as the generative component of our model and to combine these with a robust technique to lift 2D videos into meaningful 3D motion. We find that, in contrast to prior work, this enables realistic animations of complex, pre-existing 3D scenes and further enables the animation of a large variety of object classes, while related work is mostly focused on prior-based character animation, or single 3D objects. Our model enables the creation of consistent, immersive 3D experiences for arbitrary scenes.
Evolutive Rendering Models
May 27, 2024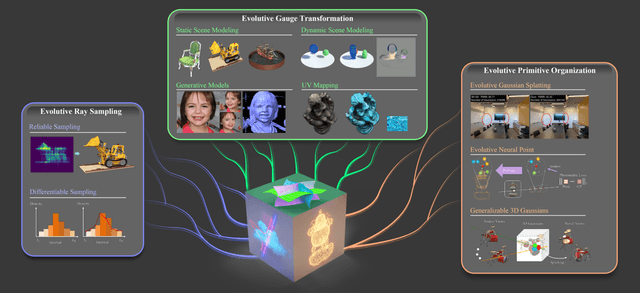
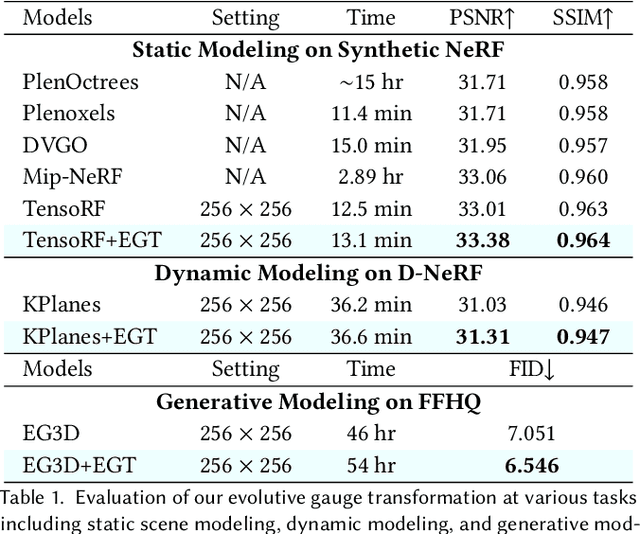
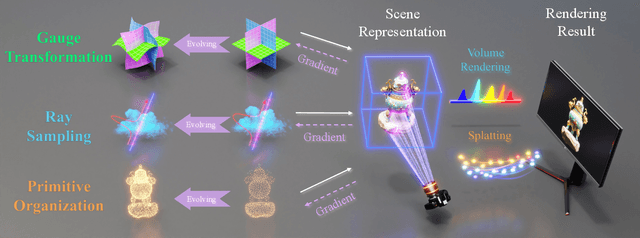
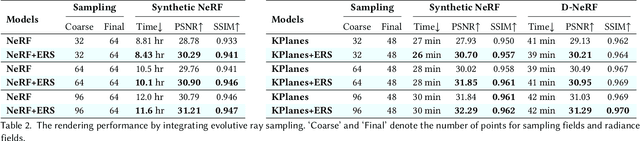
The landscape of computer graphics has undergone significant transformations with the recent advances of differentiable rendering models. These rendering models often rely on heuristic designs that may not fully align with the final rendering objectives. We address this gap by pioneering \textit{evolutive rendering models}, a methodology where rendering models possess the ability to evolve and adapt dynamically throughout the rendering process. In particular, we present a comprehensive learning framework that enables the optimization of three principal rendering elements, including the gauge transformations, the ray sampling mechanisms, and the primitive organization. Central to this framework is the development of differentiable versions of these rendering elements, allowing for effective gradient backpropagation from the final rendering objectives. A detailed analysis of gradient characteristics is performed to facilitate a stable and goal-oriented elements evolution. Our extensive experiments demonstrate the large potential of evolutive rendering models for enhancing the rendering performance across various domains, including static and dynamic scene representations, generative modeling, and texture mapping.
Splat-SLAM: Globally Optimized RGB-only SLAM with 3D Gaussians
May 26, 2024



3D Gaussian Splatting has emerged as a powerful representation of geometry and appearance for RGB-only dense Simultaneous Localization and Mapping (SLAM), as it provides a compact dense map representation while enabling efficient and high-quality map rendering. However, existing methods show significantly worse reconstruction quality than competing methods using other 3D representations, e.g. neural points clouds, since they either do not employ global map and pose optimization or make use of monocular depth. In response, we propose the first RGB-only SLAM system with a dense 3D Gaussian map representation that utilizes all benefits of globally optimized tracking by adapting dynamically to keyframe pose and depth updates by actively deforming the 3D Gaussian map. Moreover, we find that refining the depth updates in inaccurate areas with a monocular depth estimator further improves the accuracy of the 3D reconstruction. Our experiments on the Replica, TUM-RGBD, and ScanNet datasets indicate the effectiveness of globally optimized 3D Gaussians, as the approach achieves superior or on par performance with existing RGB-only SLAM methods methods in tracking, mapping and rendering accuracy while yielding small map sizes and fast runtimes. The source code is available at https://github.com/eriksandstroem/Splat-SLAM.
RadSplat: Radiance Field-Informed Gaussian Splatting for Robust Real-Time Rendering with 900+ FPS
Mar 20, 2024



Recent advances in view synthesis and real-time rendering have achieved photorealistic quality at impressive rendering speeds. While Radiance Field-based methods achieve state-of-the-art quality in challenging scenarios such as in-the-wild captures and large-scale scenes, they often suffer from excessively high compute requirements linked to volumetric rendering. Gaussian Splatting-based methods, on the other hand, rely on rasterization and naturally achieve real-time rendering but suffer from brittle optimization heuristics that underperform on more challenging scenes. In this work, we present RadSplat, a lightweight method for robust real-time rendering of complex scenes. Our main contributions are threefold. First, we use radiance fields as a prior and supervision signal for optimizing point-based scene representations, leading to improved quality and more robust optimization. Next, we develop a novel pruning technique reducing the overall point count while maintaining high quality, leading to smaller and more compact scene representations with faster inference speeds. Finally, we propose a novel test-time filtering approach that further accelerates rendering and allows to scale to larger, house-sized scenes. We find that our method enables state-of-the-art synthesis of complex captures at 900+ FPS.
UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction
Apr 20, 2021
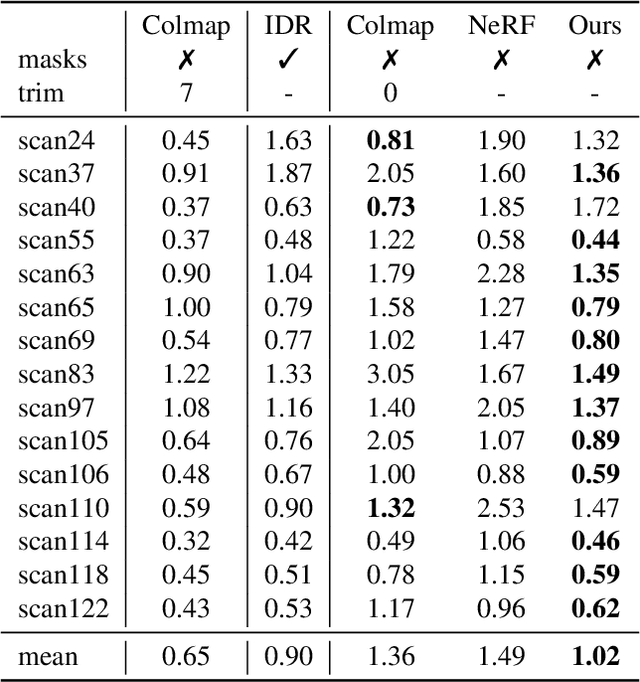


Neural implicit 3D representations have emerged as a powerful paradigm for reconstructing surfaces from multi-view images and synthesizing novel views. Unfortunately, existing methods such as DVR or IDR require accurate per-pixel object masks as supervision. At the same time, neural radiance fields have revolutionized novel view synthesis. However, NeRF's estimated volume density does not admit accurate surface reconstruction. Our key insight is that implicit surface models and radiance fields can be formulated in a unified way, enabling both surface and volume rendering using the same model. This unified perspective enables novel, more efficient sampling procedures and the ability to reconstruct accurate surfaces without input masks. We compare our method on the DTU, BlendedMVS, and a synthetic indoor dataset. Our experiments demonstrate that we outperform NeRF in terms of reconstruction quality while performing on par with IDR without requiring masks.