 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp Monocular View Synthesis in Less Than a Second
Dec 11, 2025We present SHARP, an approach to photorealistic view synthesis from a single image. Given a single photograph, SHARP regresses the parameters of a 3D Gaussian representation of the depicted scene. This is done in less than a second on a standard GPU via a single feedforward pass through a neural network. The 3D Gaussian representation produced by SHARP can then be rendered in real time, yielding high-resolution photorealistic images for nearby views. The representation is metric, with absolute scale, supporting metric camera movements. Experimental results demonstrate that SHARP delivers robust zero-shot generalization across datasets. It sets a new state of the art on multiple datasets, reducing LPIPS by 25-34% and DISTS by 21-43% versus the best prior model, while lowering the synthesis time by three orders of magnitude. Code and weights are provided at https://github.com/apple/ml-sharp
Learning Neural Light Transport
Jun 05, 2020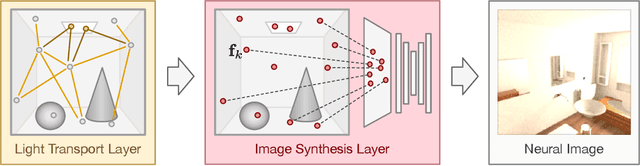
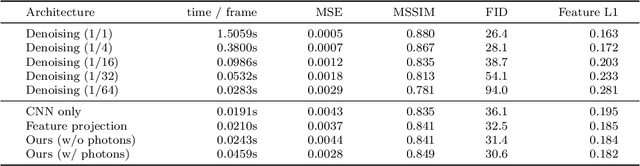
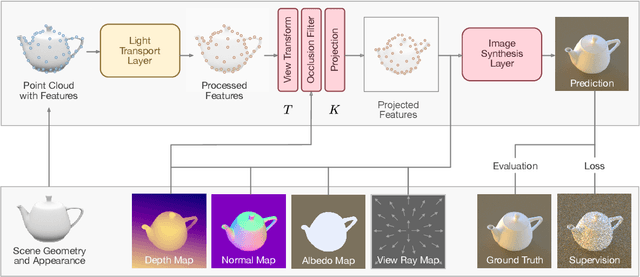
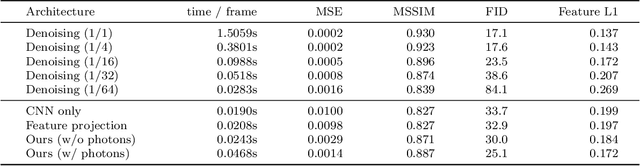
In recent years, deep generative models have gained significance due to their ability to synthesize natural-looking images with applications ranging from virtual reality to data augmentation for training computer vision models. While existing models are able to faithfully learn the image distribution of the training set, they often lack controllability as they operate in 2D pixel space and do not model the physical image formation process. In this work, we investigate the importance of 3D reasoning for photorealistic rendering. We present an approach for learning light transport in static and dynamic 3D scenes using a neural network with the goal of predicting photorealistic images. In contrast to existing approaches that operate in the 2D image domain, our approach reasons in both 3D and 2D space, thus enabling global illumination effects and manipulation of 3D scene geometry. Experimentally, we find that our model is able to produce photorealistic renderings of static and dynamic scenes. Moreover, it compares favorably to baselines which combine path tracing and image denoising at the same computational budget.
Learning Implicit Surface Light Fields
Mar 27, 2020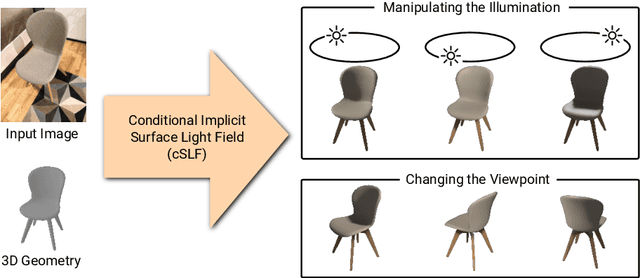
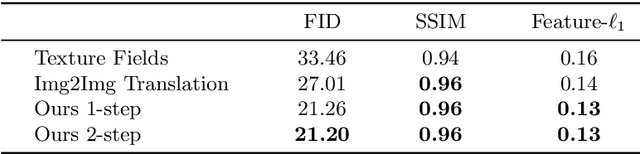
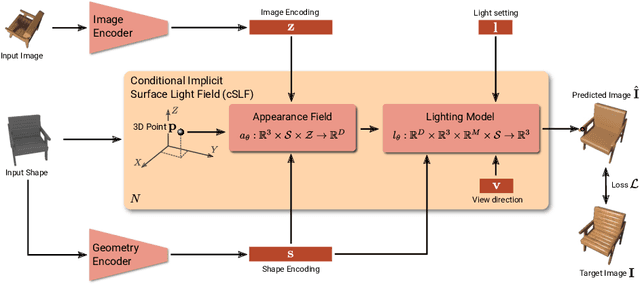
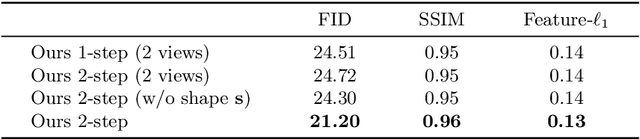
Implicit representations of 3D objects have recently achieved impressive results on learning-based 3D reconstruction tasks. While existing works use simple texture models to represent object appearance, photo-realistic image synthesis requires reasoning about the complex interplay of light, geometry and surface properties. In this work, we propose a novel implicit representation for capturing the visual appearance of an object in terms of its surface light field. In contrast to existing representations, our implicit model represents surface light fields in a continuous fashion and independent of the geometry. Moreover, we condition the surface light field with respect to the location and color of a small light source. Compared to traditional surface light field models, this allows us to manipulate the light source and relight the object using environment maps. We further demonstrate the capabilities of our model to predict the visual appearance of an unseen object from a single real RGB image and corresponding 3D shape information. As evidenced by our experiments, our model is able to infer rich visual appearance including shadows and specular reflections. Finally, we show that the proposed representation can be embedded into a variational auto-encoder for generating novel appearances that conform to the specified illumination conditions.
Convolutional Occupancy Networks
Mar 10, 2020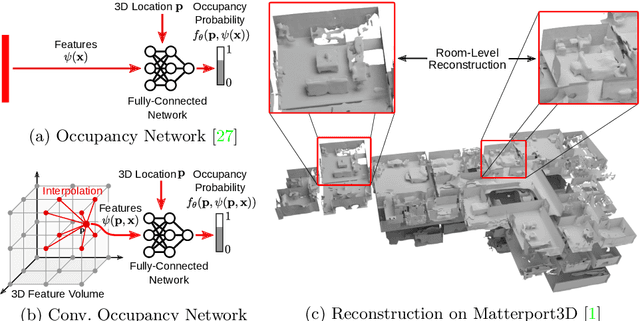
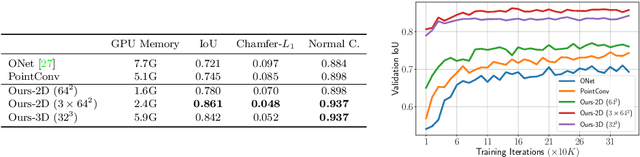
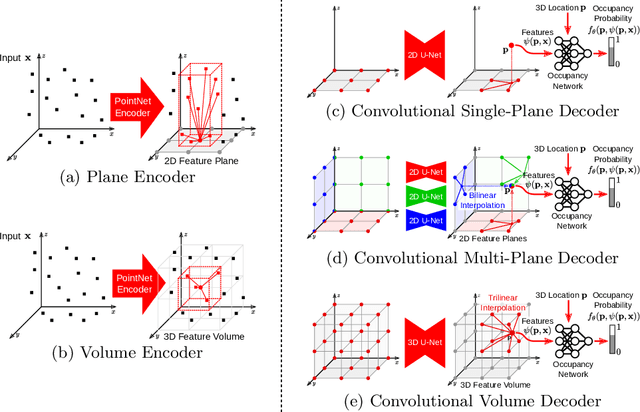
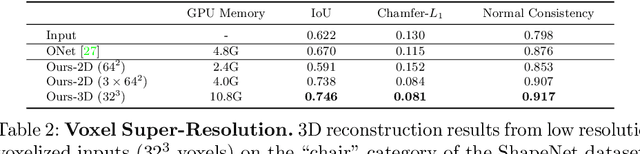
Recently, implicit neural representations have gained popularity for learning-based 3D reconstruction. While demonstrating promising results, most implicit approaches are limited to comparably simple geometry of single objects and do not scale to more complicated or large-scale scenes. The key limiting factor of implicit methods is their simple fully-connected network architecture which does not allow for integrating local information in the observations or incorporating inductive biases such as translational equivariance. In this paper, we propose Convolutional Occupancy Networks, a more flexible implicit representation for detailed reconstruction of objects and 3D scenes. By combining convolutional encoders with implicit occupancy decoders, our model incorporates inductive biases and Manhattan-world priors, enabling structured reasoning in 3D space. We investigate the effectiveness of the proposed representation by reconstructing complex geometry from noisy point clouds and low-resolution voxel representations. We empirically find that our method enables fine-grained implicit 3D reconstruction of single objects, scales to large indoor scenes and generalizes well from synthetic to real data.
Differentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision
Dec 16, 2019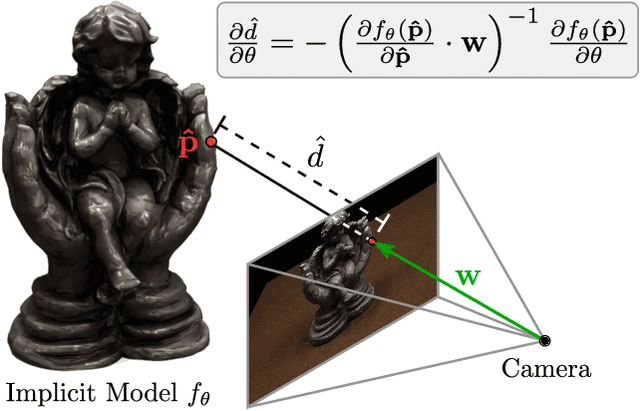
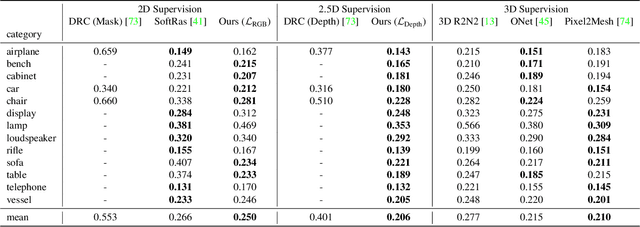
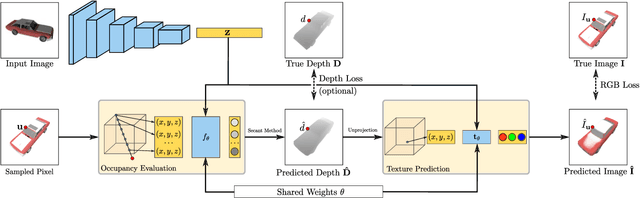
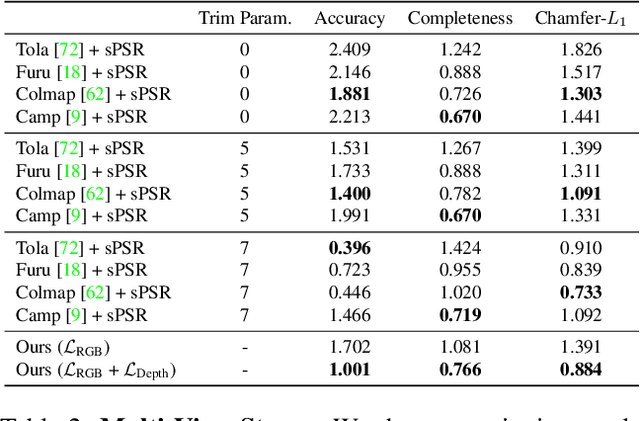
Learning-based 3D reconstruction methods have shown impressive results. However, most methods require 3D supervision which is often hard to obtain for real world datasets. Recently, several works have proposed differentiable rendering techniques to train reconstruction models from RGB images. Unfortunately, these approaches are currently restricted to voxel- and mesh-based representations, suffering from discretization or low resolution. In this work, we propose a differentiable rendering formulation for implicit shape and texture representations. Implicit representations have recently gained popularity as they are able to represent shape and texture continuously. Our key insight is that depth gradients can be derived analytically using the concept of implicit differentiation. This allows us to learn implicit shape and texture representations directly from RGB images. We experimentally show that our single-view reconstructions rival those learned with full 3D supervision. Moreover, we find that our method can be used for multi-view 3D reconstruction, directly resulting in watertight meshes.
Towards Unsupervised Learning of Generative Models for 3D Controllable Image Synthesis
Dec 11, 2019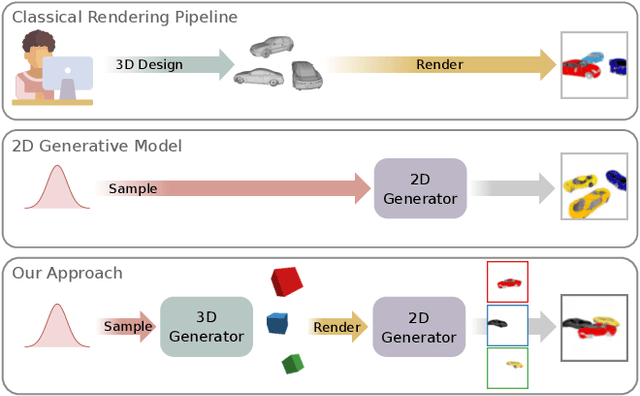
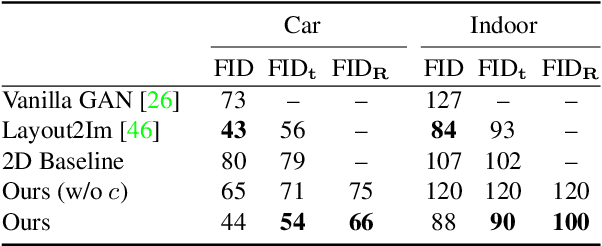


In recent years, Generative Adversarial Networks have achieved impressive results in photorealistic image synthesis. This progress nurtures hopes that one day the classical rendering pipeline can be replaced by efficient models that are learned directly from images. However, current image synthesis models operate in the 2D domain where disentangling 3D properties such as camera viewpoint or object pose is challenging. Furthermore, they lack an interpretable and controllable representation. Our key hypothesis is that the image generation process should be modeled in 3D space as the physical world surrounding us is intrinsically three-dimensional. We define the new task of 3D controllable image synthesis and propose an approach for solving it by reasoning both in 3D space and in the 2D image domain. We demonstrate that our model is able to disentangle latent 3D factors of simple multi-object scenes in an unsupervised fashion from raw images. Compared to pure 2D baselines, it allows for synthesizing scenes that are consistent wrt. changes in viewpoint or object pose. We further evaluate various 3D representations in terms of their usefulness for this challenging task.
Texture Fields: Learning Texture Representations in Function Space
May 17, 2019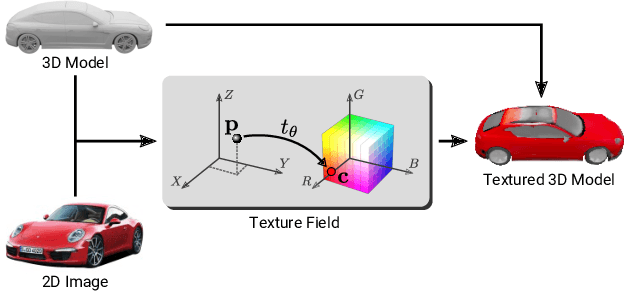
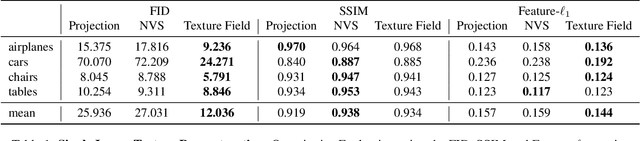
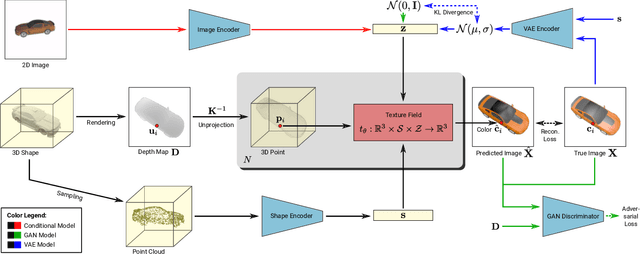

In recent years, substantial progress has been achieved in learning-based reconstruction of 3D objects. At the same time, generative models were proposed that can generate highly realistic images. However, despite this success in these closely related tasks, texture reconstruction of 3D objects has received little attention from the research community and state-of-the-art methods are either limited to comparably low resolution or constrained experimental setups. A major reason for these limitations is that common representations of texture are inefficient or hard to interface for modern deep learning techniques. In this paper, we propose Texture Fields, a novel texture representation which is based on regressing a continuous 3D function parameterized with a neural network. Our approach circumvents limiting factors like shape discretization and parameterization, as the proposed texture representation is independent of the shape representation of the 3D object. We show that Texture Fields are able to represent high frequency texture and naturally blend with modern deep learning techniques. Experimentally, we find that Texture Fields compare favorably to state-of-the-art methods for conditional texture reconstruction of 3D objects and enable learning of probabilistic generative models for texturing unseen 3D models. We believe that Texture Fields will become an important building block for the next generation of generative 3D models.
Occupancy Networks: Learning 3D Reconstruction in Function Space
Dec 10, 2018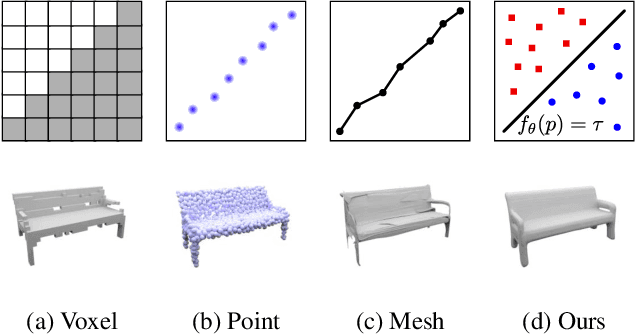
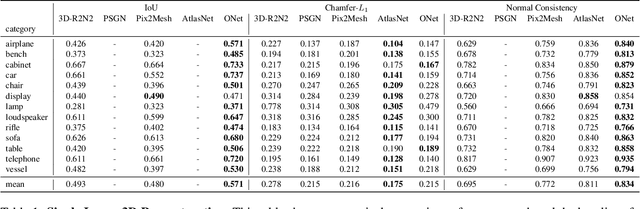
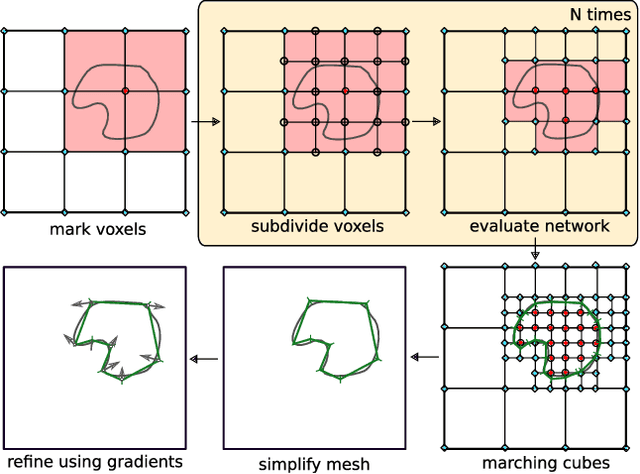
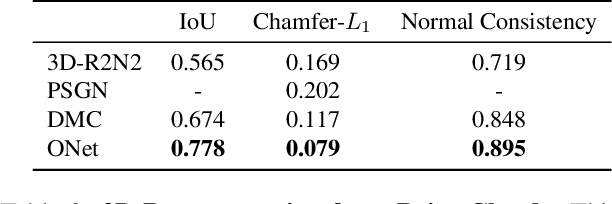
With the advent of deep neural networks, learning-based approaches for 3D reconstruction have gained popularity. However, unlike for images, in 3D there is no canonical representation which is both computationally and memory efficient yet allows for representing high-resolution geometry of arbitrary topology. Many of the state-of-the-art learning-based 3D reconstruction approaches can hence only represent very coarse 3D geometry or are limited to a restricted domain. In this paper, we propose occupancy networks, a new representation for learning-based 3D reconstruction methods. Occupancy networks implicitly represent the 3D surface as the continuous decision boundary of a deep neural network classifier. In contrast to existing approaches, our representation encodes a description of the 3D output at infinite resolution without excessive memory footprint. We validate that our representation can efficiently encode 3D structure and can be inferred from various kinds of input. Our experiments demonstrate competitive results, both qualitatively and quantitatively, for the challenging tasks of 3D reconstruction from single images, noisy point clouds and coarse discrete voxel grids. We believe that occupancy networks will become a useful tool in a wide variety of learning-based 3D tasks.
Which Training Methods for GANs do actually Converge?
Jul 31, 2018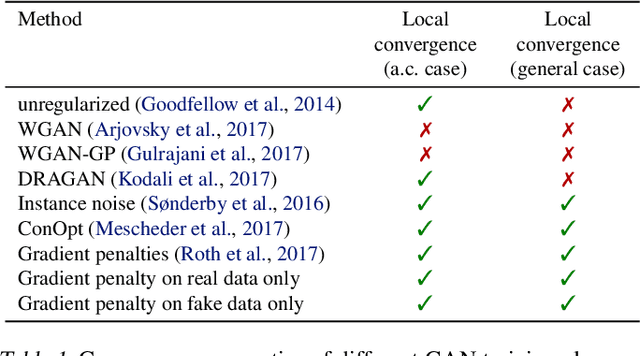
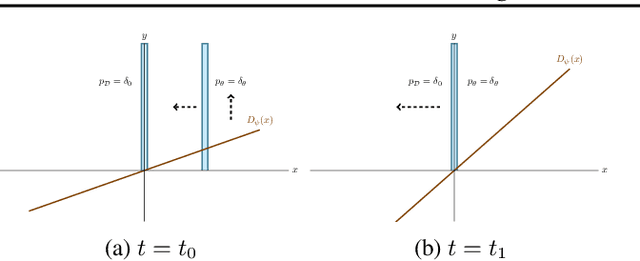
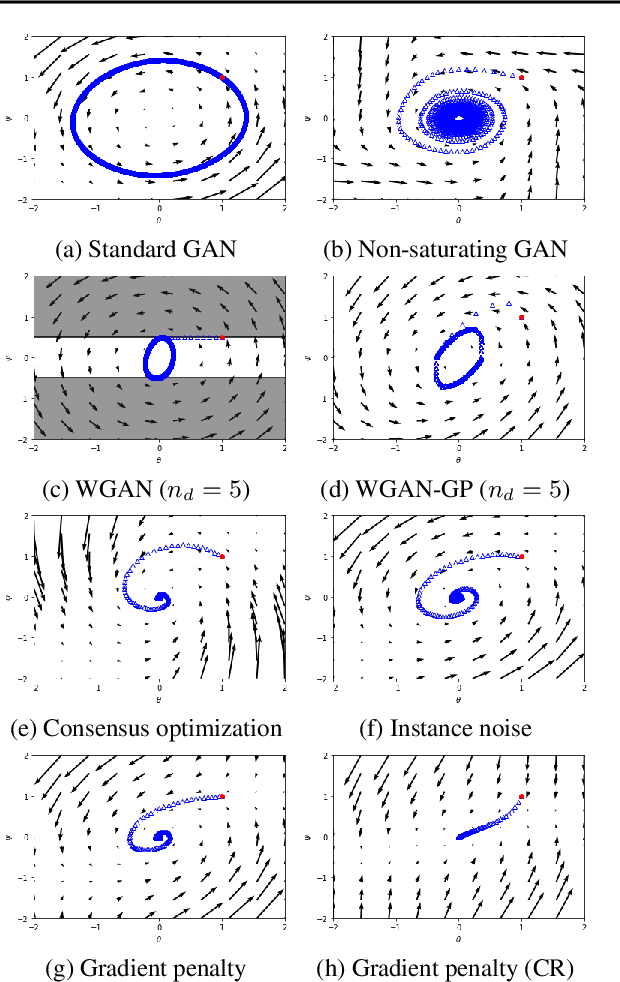
Recent work has shown local convergence of GAN training for absolutely continuous data and generator distributions. In this paper, we show that the requirement of absolute continuity is necessary: we describe a simple yet prototypical counterexample showing that in the more realistic case of distributions that are not absolutely continuous, unregularized GAN training is not always convergent. Furthermore, we discuss regularization strategies that were recently proposed to stabilize GAN training. Our analysis shows that GAN training with instance noise or zero-centered gradient penalties converges. On the other hand, we show that Wasserstein-GANs and WGAN-GP with a finite number of discriminator updates per generator update do not always converge to the equilibrium point. We discuss these results, leading us to a new explanation for the stability problems of GAN training. Based on our analysis, we extend our convergence results to more general GANs and prove local convergence for simplified gradient penalties even if the generator and data distribution lie on lower dimensional manifolds. We find these penalties to work well in practice and use them to learn high-resolution generative image models for a variety of datasets with little hyperparameter tuning.
* conference
The Numerics of GANs
Jun 11, 2018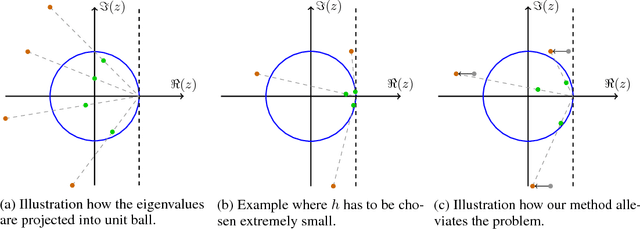

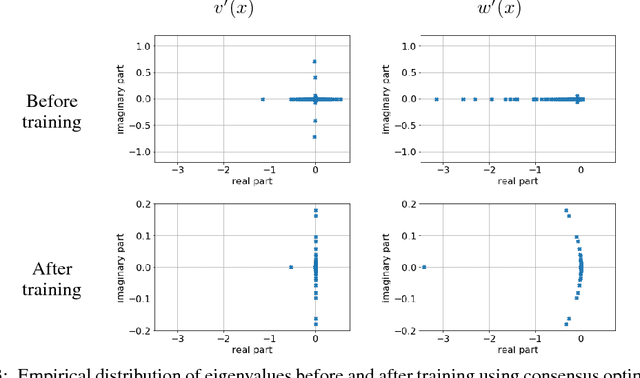

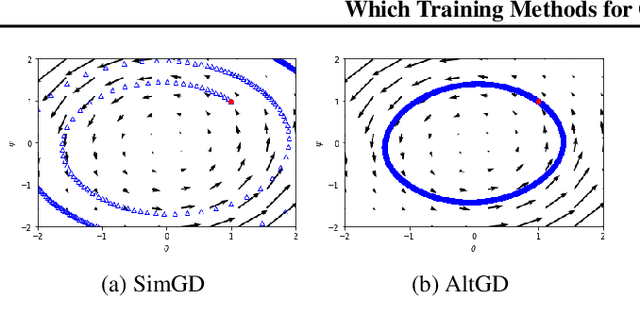
In this paper, we analyze the numerics of common algorithms for training Generative Adversarial Networks (GANs). Using the formalism of smooth two-player games we analyze the associated gradient vector field of GAN training objectives. Our findings suggest that the convergence of current algorithms suffers due to two factors: i) presence of eigenvalues of the Jacobian of the gradient vector field with zero real-part, and ii) eigenvalues with big imaginary part. Using these findings, we design a new algorithm that overcomes some of these limitations and has better convergence properties. Experimentally, we demonstrate its superiority on training common GAN architectures and show convergence on GAN architectures that are known to be notoriously hard to train.