 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference-Based Gradient Estimation for ML-Based Approximate Combinatorial Optimization
Feb 26, 2025Combinatorial optimization (CO) problems arise in a wide range of fields from medicine to logistics and manufacturing. While exact solutions are often not necessary, many applications require finding high-quality solutions quickly. For this purpose, we propose a data-driven approach to improve existing non-learned approximation algorithms for CO. We parameterize the approximation algorithm and train a graph neural network (GNN) to predict parameter values that lead to the best possible solutions. Our pipeline is trained end-to-end in a self-supervised fashion using gradient estimation, treating the approximation algorithm as a black box. We propose a novel gradient estimation scheme for this purpose, which we call preference-based gradient estimation. Our approach combines the benefits of the neural network and the non-learned approximation algorithm: The GNN leverages the information from the dataset to allow the approximation algorithm to find better solutions, while the approximation algorithm guarantees that the solution is feasible. We validate our approach on two well-known combinatorial optimization problems, the travelling salesman problem and the minimum k-cut problem, and show that our method is competitive with state of the art learned CO solvers.
Solving the Electrical Impedance Tomography Problem with a DeepONet Type Neural Network: Theory and Application
Jul 24, 2024In this work, we consider the non-invasive medical imaging modality of Electrical Impedance Tomography, where the problem is to recover the conductivity in a medium from a set of data that arises out of a current-to-voltage map (Neumann-to-Dirichlet operator) defined on the boundary of the medium. We formulate this inverse problem as an operator-learning problem where the goal is to learn the implicitly defined operator-to-function map between the space of Neumann-to-Dirichlet operators to the space of admissible conductivities. Subsequently, we use an operator-learning architecture, popularly called DeepONets, to learn this operator-to-function map. Thus far, most of the operator learning architectures have been implemented to learn operators between function spaces. In this work, we generalize the earlier works and use a DeepONet to actually {learn an operator-to-function} map. We provide a Universal Approximation Theorem type result which guarantees that this implicitly defined operator-to-function map between the space of Neumann-to-Dirichlet operator to the space of conductivity function can be approximated to an arbitrary degree using such a DeepONet. Furthermore, we provide a computational implementation of our proposed approach and compare it against a standard baseline. We show that the proposed approach achieves good reconstructions and outperforms the baseline method in our experiments.
Learning Implicit Surface Light Fields
Mar 27, 2020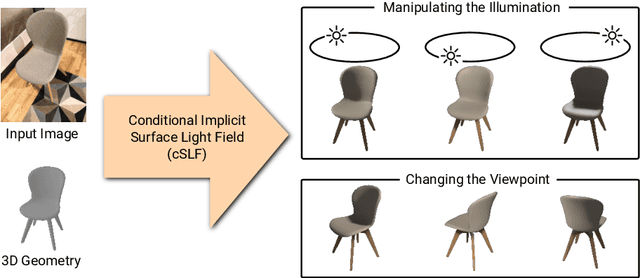
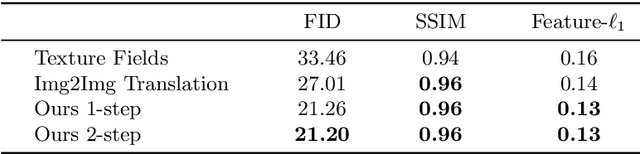
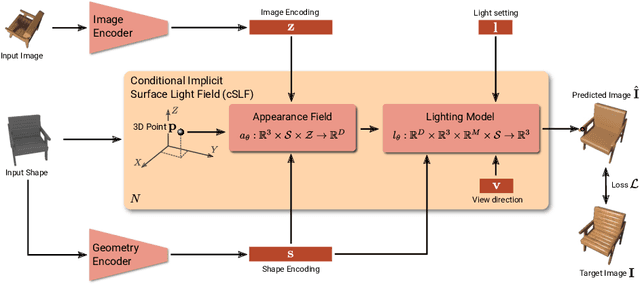
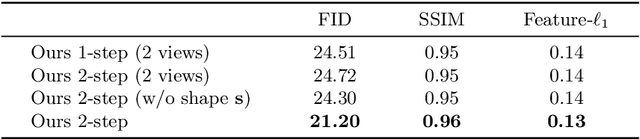
Implicit representations of 3D objects have recently achieved impressive results on learning-based 3D reconstruction tasks. While existing works use simple texture models to represent object appearance, photo-realistic image synthesis requires reasoning about the complex interplay of light, geometry and surface properties. In this work, we propose a novel implicit representation for capturing the visual appearance of an object in terms of its surface light field. In contrast to existing representations, our implicit model represents surface light fields in a continuous fashion and independent of the geometry. Moreover, we condition the surface light field with respect to the location and color of a small light source. Compared to traditional surface light field models, this allows us to manipulate the light source and relight the object using environment maps. We further demonstrate the capabilities of our model to predict the visual appearance of an unseen object from a single real RGB image and corresponding 3D shape information. As evidenced by our experiments, our model is able to infer rich visual appearance including shadows and specular reflections. Finally, we show that the proposed representation can be embedded into a variational auto-encoder for generating novel appearances that conform to the specified illumination conditions.
CANet: An Unsupervised Intrusion Detection System for High Dimensional CAN Bus Data
Jun 06, 2019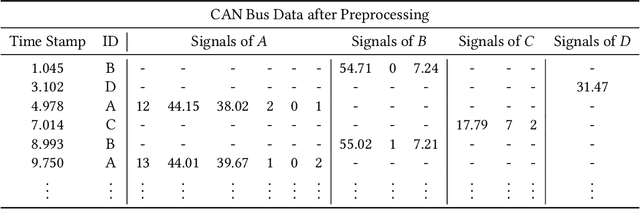
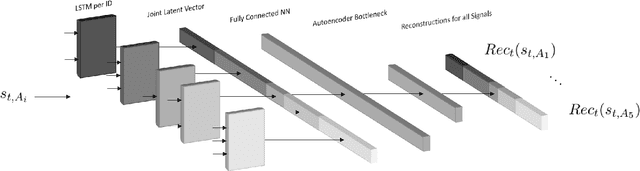
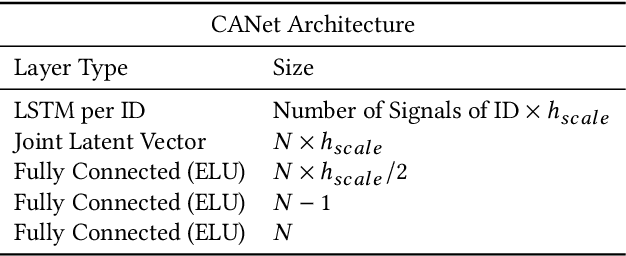

We propose a novel neural network architecture for detecting intrusions on the CAN bus. The Controller Area Network (CAN) is the standard communication method between the Electronic Control Units (ECUs) of automobiles. However, CAN lacks security mechanisms and it has recently been shown that it can be attacked remotely. Hence, it is desirable to monitor CAN traffic to detect intrusions. In order to detect both, known and unknown intrusion scenarios, we consider a novel unsupervised learning approach which we call CANet. To our knowledge, this is the first deep learning based intrusion detection system (IDS) that takes individual CAN messages with different IDs and evaluates them in the moment they are received. This is a significant advancement because messages with different IDs are typically sent at different times and with different frequencies. Our method is evaluated on real and synthetic CAN data. For reproducibility of the method, our synthetic data is publicly available. A comparison with previous machine learning based methods shows that CANet outperforms them by a significant margin.
Texture Fields: Learning Texture Representations in Function Space
May 17, 2019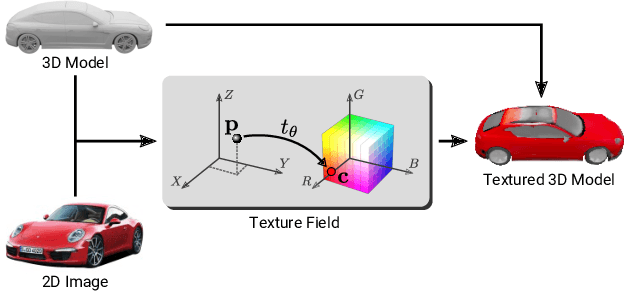
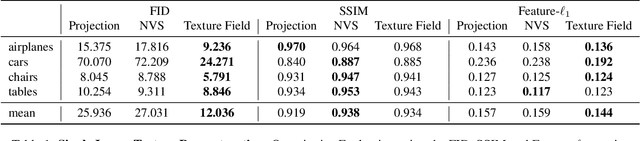
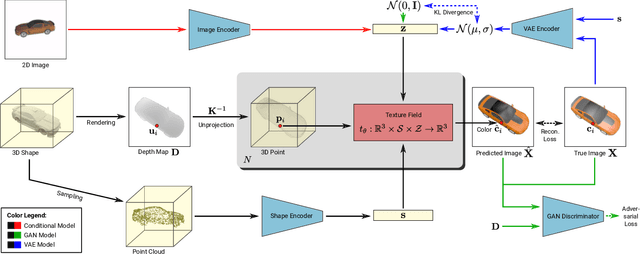

In recent years, substantial progress has been achieved in learning-based reconstruction of 3D objects. At the same time, generative models were proposed that can generate highly realistic images. However, despite this success in these closely related tasks, texture reconstruction of 3D objects has received little attention from the research community and state-of-the-art methods are either limited to comparably low resolution or constrained experimental setups. A major reason for these limitations is that common representations of texture are inefficient or hard to interface for modern deep learning techniques. In this paper, we propose Texture Fields, a novel texture representation which is based on regressing a continuous 3D function parameterized with a neural network. Our approach circumvents limiting factors like shape discretization and parameterization, as the proposed texture representation is independent of the shape representation of the 3D object. We show that Texture Fields are able to represent high frequency texture and naturally blend with modern deep learning techniques. Experimentally, we find that Texture Fields compare favorably to state-of-the-art methods for conditional texture reconstruction of 3D objects and enable learning of probabilistic generative models for texturing unseen 3D models. We believe that Texture Fields will become an important building block for the next generation of generative 3D models.
Unpaired High-Resolution and Scalable Style Transfer Using Generative Adversarial Networks
Oct 10, 2018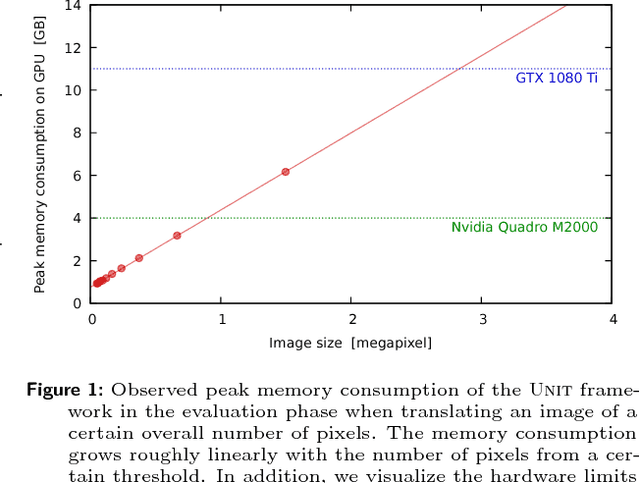
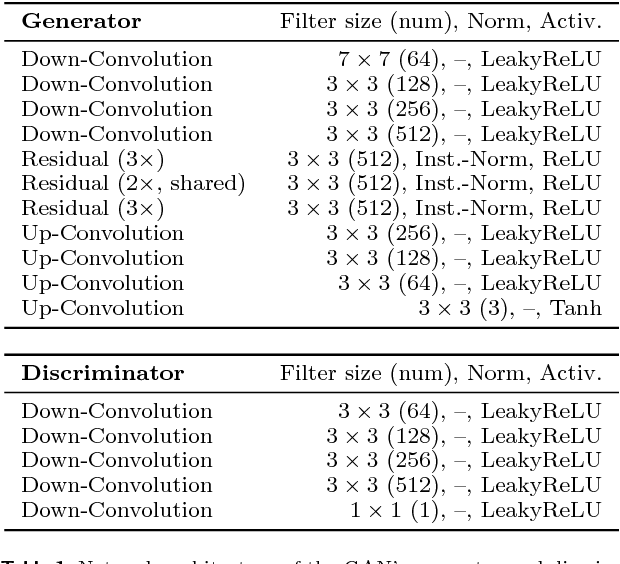
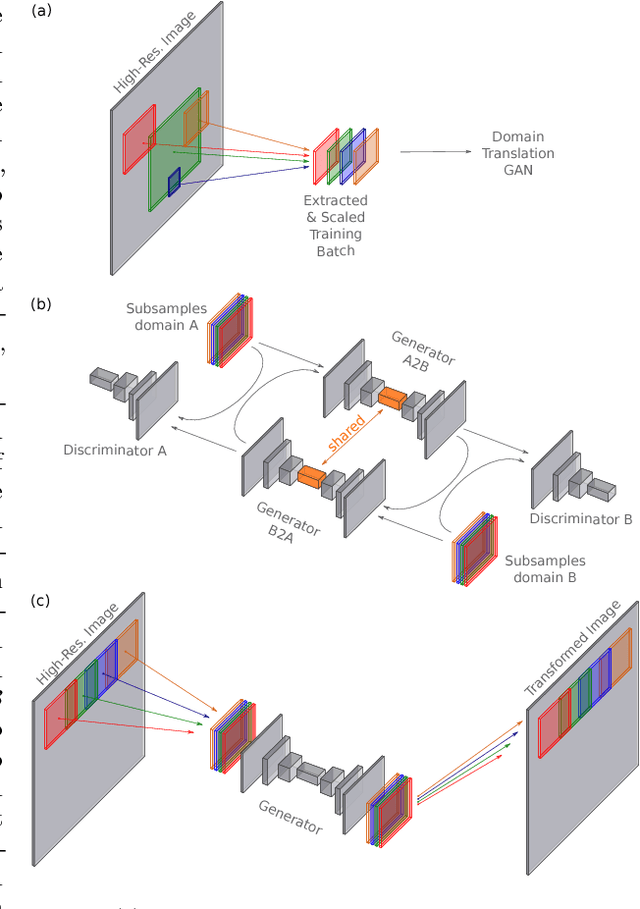
Neural networks have proven their capabilities by outperforming many other approaches on regression or classification tasks on various kinds of data. Other astonishing results have been achieved using neural nets as data generators, especially in settings of generative adversarial networks (GANs). One special application is the field of image domain translations. Here, the goal is to take an image with a certain style (e.g. a photography) and transform it into another one (e.g. a painting). If such a task is performed for unpaired training examples, the corresponding GAN setting is complex, the neural networks are large, and this leads to a high peak memory consumption during, both, training and evaluation phase. This sets a limit to the highest processable image size. We address this issue by the idea of not processing the whole image at once, but to train and evaluate the domain translation on the level of overlapping image subsamples. This new approach not only enables us to translate high-resolution images that otherwise cannot be processed by the neural network at once, but also allows us to work with comparably small neural networks and with limited hardware resources. Additionally, the number of images required for the training process is significantly reduced. We present high-quality results on images with a total resolution of up to over 50 megapixels and emonstrate that our method helps to preserve local image details while it also keeps global consistency.
Ensemble Methods as a Defense to Adversarial Perturbations Against Deep Neural Networks
Feb 08, 2018
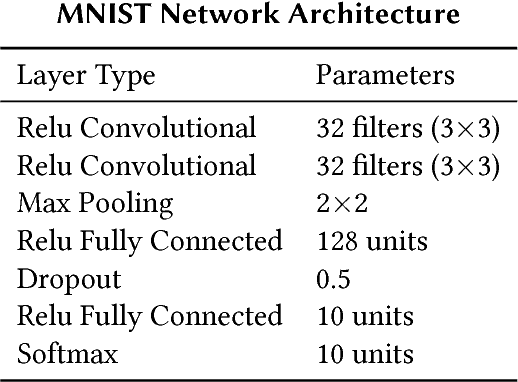
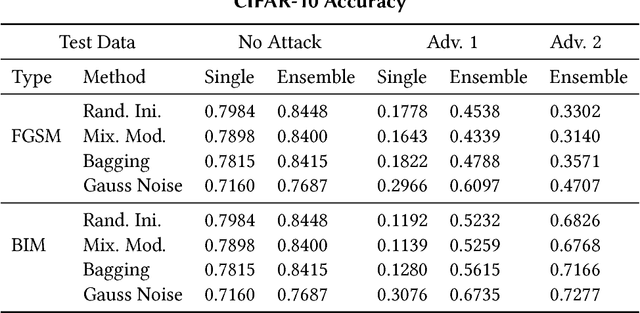

Deep learning has become the state of the art approach in many machine learning problems such as classification. It has recently been shown that deep learning is highly vulnerable to adversarial perturbations. Taking the camera systems of self-driving cars as an example, small adversarial perturbations can cause the system to make errors in important tasks, such as classifying traffic signs or detecting pedestrians. Hence, in order to use deep learning without safety concerns a proper defense strategy is required. We propose to use ensemble methods as a defense strategy against adversarial perturbations. We find that an attack leading one model to misclassify does not imply the same for other networks performing the same task. This makes ensemble methods an attractive defense strategy against adversarial attacks. We empirically show for the MNIST and the CIFAR-10 data sets that ensemble methods not only improve the accuracy of neural networks on test data but also increase their robustness against adversarial perturbations.