 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformed Equation Learning
May 13, 2021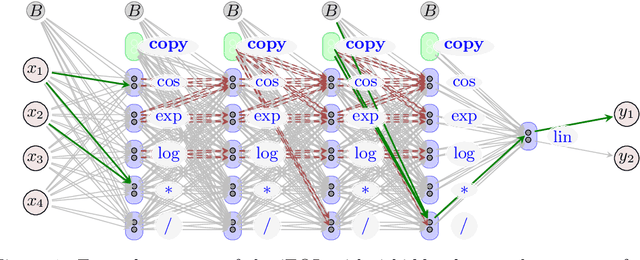
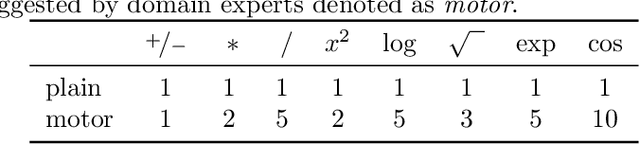
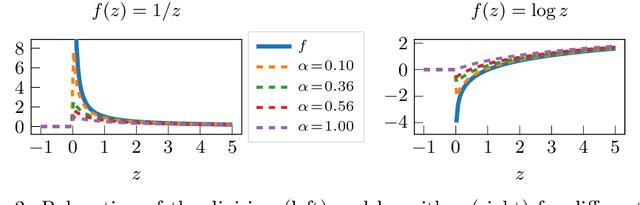

Distilling data into compact and interpretable analytic equations is one of the goals of science. Instead, contemporary supervised machine learning methods mostly produce unstructured and dense maps from input to output. Particularly in deep learning, this property is owed to the generic nature of simple standard link functions. To learn equations rather than maps, standard non-linearities can be replaced with structured building blocks of atomic functions. However, without strong priors on sparsity and structure, representational complexity and numerical conditioning limit this direct approach. To scale to realistic settings in science and engineering, we propose an informed equation learning system. It provides a way to incorporate expert knowledge about what are permitted or prohibited equation components, as well as a domain-dependent structured sparsity prior. Our system then utilizes a robust method to learn equations with atomic functions exhibiting singularities, as e.g. logarithm and division. We demonstrate several artificial and real-world experiments from the engineering domain, in which our system learns interpretable models of high predictive power.
Unpaired High-Resolution and Scalable Style Transfer Using Generative Adversarial Networks
Oct 10, 2018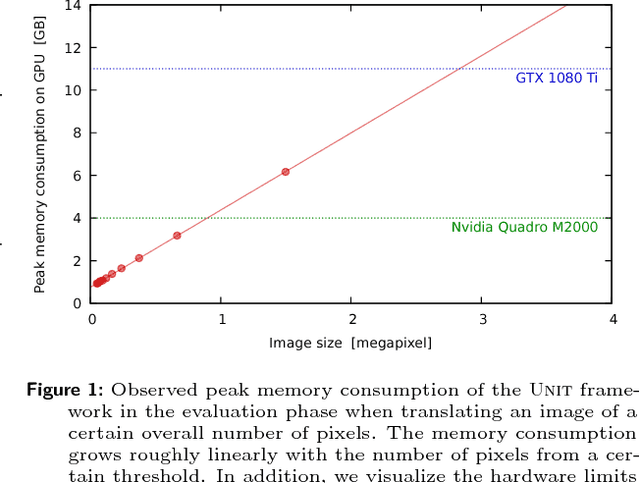
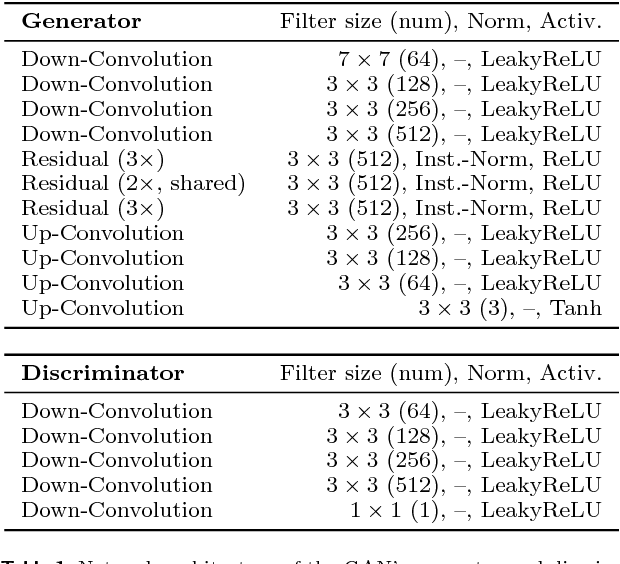
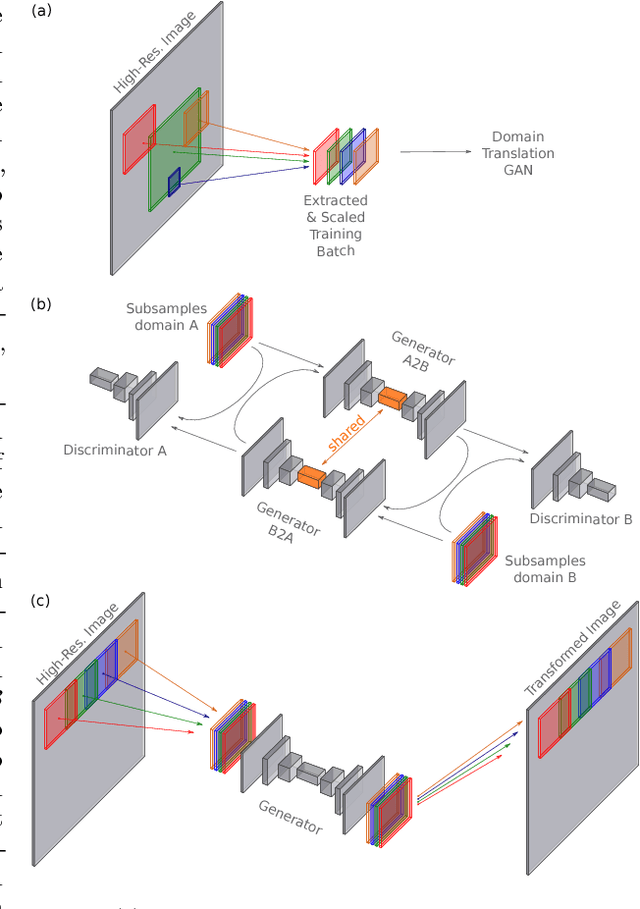
Neural networks have proven their capabilities by outperforming many other approaches on regression or classification tasks on various kinds of data. Other astonishing results have been achieved using neural nets as data generators, especially in settings of generative adversarial networks (GANs). One special application is the field of image domain translations. Here, the goal is to take an image with a certain style (e.g. a photography) and transform it into another one (e.g. a painting). If such a task is performed for unpaired training examples, the corresponding GAN setting is complex, the neural networks are large, and this leads to a high peak memory consumption during, both, training and evaluation phase. This sets a limit to the highest processable image size. We address this issue by the idea of not processing the whole image at once, but to train and evaluate the domain translation on the level of overlapping image subsamples. This new approach not only enables us to translate high-resolution images that otherwise cannot be processed by the neural network at once, but also allows us to work with comparably small neural networks and with limited hardware resources. Additionally, the number of images required for the training process is significantly reduced. We present high-quality results on images with a total resolution of up to over 50 megapixels and emonstrate that our method helps to preserve local image details while it also keeps global consistency.
Ensemble Methods as a Defense to Adversarial Perturbations Against Deep Neural Networks
Feb 08, 2018
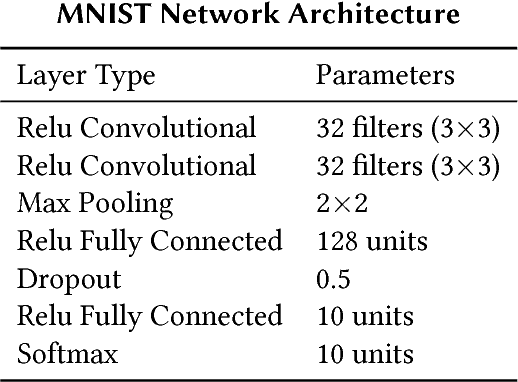
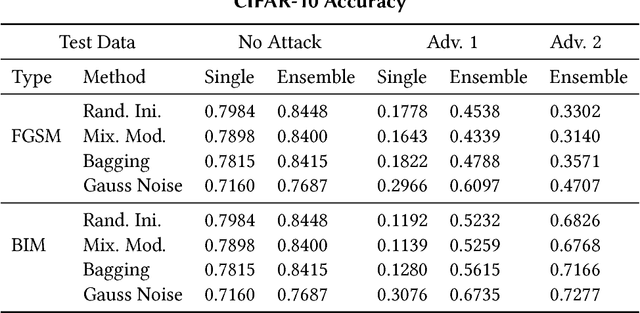

Deep learning has become the state of the art approach in many machine learning problems such as classification. It has recently been shown that deep learning is highly vulnerable to adversarial perturbations. Taking the camera systems of self-driving cars as an example, small adversarial perturbations can cause the system to make errors in important tasks, such as classifying traffic signs or detecting pedestrians. Hence, in order to use deep learning without safety concerns a proper defense strategy is required. We propose to use ensemble methods as a defense strategy against adversarial perturbations. We find that an attack leading one model to misclassify does not imply the same for other networks performing the same task. This makes ensemble methods an attractive defense strategy against adversarial attacks. We empirically show for the MNIST and the CIFAR-10 data sets that ensemble methods not only improve the accuracy of neural networks on test data but also increase their robustness against adversarial perturbations.