 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision
Paper and Code
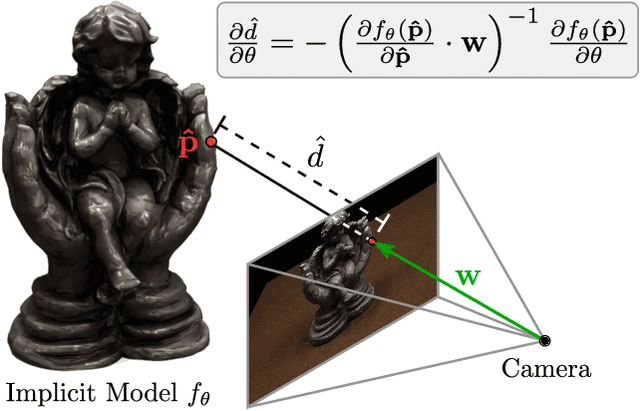
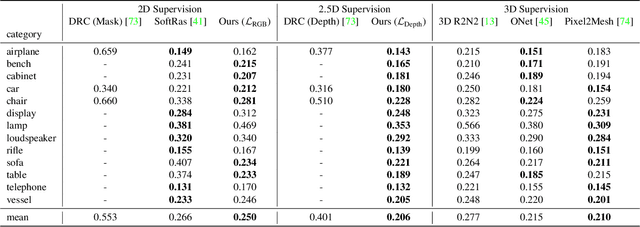
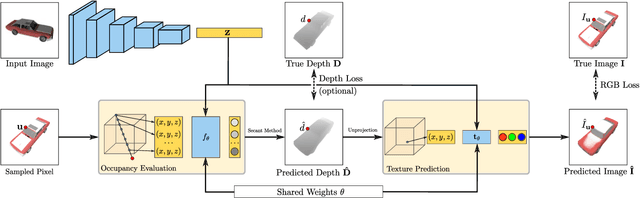
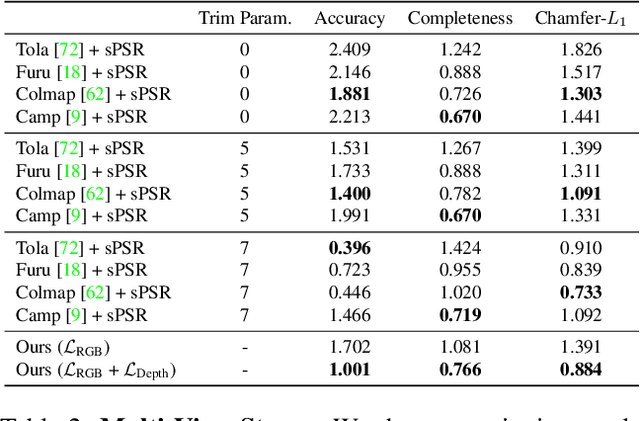
Learning-based 3D reconstruction methods have shown impressive results. However, most methods require 3D supervision which is often hard to obtain for real world datasets. Recently, several works have proposed differentiable rendering techniques to train reconstruction models from RGB images. Unfortunately, these approaches are currently restricted to voxel- and mesh-based representations, suffering from discretization or low resolution. In this work, we propose a differentiable rendering formulation for implicit shape and texture representations. Implicit representations have recently gained popularity as they are able to represent shape and texture continuously. Our key insight is that depth gradients can be derived analytically using the concept of implicit differentiation. This allows us to learn implicit shape and texture representations directly from RGB images. We experimentally show that our single-view reconstructions rival those learned with full 3D supervision. Moreover, we find that our method can be used for multi-view 3D reconstruction, directly resulting in watertight meshes.