 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCoSplat: Autoregressive Feed-Forward Gaussian Splatting Using Render-and-Compare
Mar 10, 2026Online novel view synthesis remains challenging, requiring robust scene reconstruction from sequential, often unposed, observations. We present ReCoSplat, an autoregressive feed-forward Gaussian Splatting model supporting posed or unposed inputs, with or without camera intrinsics. While assembling local Gaussians using camera poses scales better than canonical-space prediction, it creates a dilemma during training: using ground-truth poses ensures stability but causes a distribution mismatch when predicted poses are used at inference. To address this, we introduce a Render-and-Compare (ReCo) module. ReCo renders the current reconstruction from the predicted viewpoint and compares it with the incoming observation, providing a stable conditioning signal that compensates for pose errors. To support long sequences, we propose a hybrid KV cache compression strategy combining early-layer truncation with chunk-level selective retention, reducing the KV cache size by over 90% for 100+ frames. ReCoSplat achieves state-of-the-art performance across different input settings on both in- and out-of-distribution benchmarks. Code and pretrained models will be released. Our project page is at https://freemancheng.com/ReCoSplat .
Flow Equivariant World Models: Memory for Partially Observed Dynamic Environments
Jan 03, 2026Embodied systems experience the world as 'a symphony of flows': a combination of many continuous streams of sensory input coupled to self-motion, interwoven with the dynamics of external objects. These streams obey smooth, time-parameterized symmetries, which combine through a precisely structured algebra; yet most neural network world models ignore this structure and instead repeatedly re-learn the same transformations from data. In this work, we introduce 'Flow Equivariant World Models', a framework in which both self-motion and external object motion are unified as one-parameter Lie group 'flows'. We leverage this unification to implement group equivariance with respect to these transformations, thereby providing a stable latent world representation over hundreds of timesteps. On both 2D and 3D partially observed video world modeling benchmarks, we demonstrate that Flow Equivariant World Models significantly outperform comparable state-of-the-art diffusion-based and memory-augmented world modeling architectures -- particularly when there are predictable world dynamics outside the agent's current field of view. We show that flow equivariance is particularly beneficial for long rollouts, generalizing far beyond the training horizon. By structuring world model representations with respect to internal and external motion, flow equivariance charts a scalable route to data efficient, symmetry-guided, embodied intelligence. Project link: https://flowequivariantworldmodels.github.io.
GeCo: A Differentiable Geometric Consistency Metric for Video Generation
Dec 25, 2025We introduce GeCo, a geometry-grounded metric for jointly detecting geometric deformation and occlusion-inconsistency artifacts in static scenes. By fusing residual motion and depth priors, GeCo produces interpretable, dense consistency maps that reveal these artifacts. We use GeCo to systematically benchmark recent video generation models, uncovering common failure modes, and further employ it as a training-free guidance loss to reduce deformation artifacts during video generation.
Abstract 3D Perception for Spatial Intelligence in Vision-Language Models
Nov 14, 2025Vision-language models (VLMs) struggle with 3D-related tasks such as spatial cognition and physical understanding, which are crucial for real-world applications like robotics and embodied agents. We attribute this to a modality gap between the 3D tasks and the 2D training of VLM, which led to inefficient retrieval of 3D information from 2D input. To bridge this gap, we introduce SandboxVLM, a simple yet effective framework that leverages abstract bounding boxes to encode geometric structure and physical kinematics for VLM. Specifically, we design a 3D Sandbox reconstruction and perception pipeline comprising four stages: generating multi-view priors with abstract control, proxy elevation, multi-view voting and clustering, and 3D-aware reasoning. Evaluated in zero-shot settings across multiple benchmarks and VLM backbones, our approach consistently improves spatial intelligence, achieving an 8.3\% gain on SAT Real compared with baseline methods for instance. These results demonstrate that equipping VLMs with a 3D abstraction substantially enhances their 3D reasoning ability without additional training, suggesting new possibilities for general-purpose embodied intelligence.
RoboTAG: End-to-end Robot Configuration Estimation via Topological Alignment Graph
Nov 11, 2025Estimating robot pose from a monocular RGB image is a challenge in robotics and computer vision. Existing methods typically build networks on top of 2D visual backbones and depend heavily on labeled data for training, which is often scarce in real-world scenarios, causing a sim-to-real gap. Moreover, these approaches reduce the 3D-based problem to 2D domain, neglecting the 3D priors. To address these, we propose Robot Topological Alignment Graph (RoboTAG), which incorporates a 3D branch to inject 3D priors while enabling co-evolution of the 2D and 3D representations, alleviating the reliance on labels. Specifically, the RoboTAG consists of a 3D branch and a 2D branch, where nodes represent the states of the camera and robot system, and edges capture the dependencies between these variables or denote alignments between them. Closed loops are then defined in the graph, on which a consistency supervision across branches can be applied. This design allows us to utilize in-the-wild images as training data without annotations. Experimental results demonstrate that our method is effective across robot types, highlighting its potential to alleviate the data bottleneck in robotics.
Visual Acoustic Fields
Apr 01, 2025Objects produce different sounds when hit, and humans can intuitively infer how an object might sound based on its appearance and material properties. Inspired by this intuition, we propose Visual Acoustic Fields, a framework that bridges hitting sounds and visual signals within a 3D space using 3D Gaussian Splatting (3DGS). Our approach features two key modules: sound generation and sound localization. The sound generation module leverages a conditional diffusion model, which takes multiscale features rendered from a feature-augmented 3DGS to generate realistic hitting sounds. Meanwhile, the sound localization module enables querying the 3D scene, represented by the feature-augmented 3DGS, to localize hitting positions based on the sound sources. To support this framework, we introduce a novel pipeline for collecting scene-level visual-sound sample pairs, achieving alignment between captured images, impact locations, and corresponding sounds. To the best of our knowledge, this is the first dataset to connect visual and acoustic signals in a 3D context. Extensive experiments on our dataset demonstrate the effectiveness of Visual Acoustic Fields in generating plausible impact sounds and accurately localizing impact sources. Our project page is at https://yuelei0428.github.io/projects/Visual-Acoustic-Fields/.
SOGS: Second-Order Anchor for Advanced 3D Gaussian Splatting
Mar 10, 2025
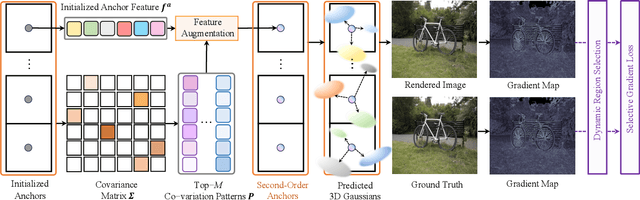


Anchor-based 3D Gaussian splatting (3D-GS) exploits anchor features in 3D Gaussian prediction, which has achieved impressive 3D rendering quality with reduced Gaussian redundancy. On the other hand, it often encounters the dilemma among anchor features, model size, and rendering quality - large anchor features lead to large 3D models and high-quality rendering whereas reducing anchor features degrades Gaussian attribute prediction which leads to clear artifacts in the rendered textures and geometries. We design SOGS, an anchor-based 3D-GS technique that introduces second-order anchors to achieve superior rendering quality and reduced anchor features and model size simultaneously. Specifically, SOGS incorporates covariance-based second-order statistics and correlation across feature dimensions to augment features within each anchor, compensating for the reduced feature size and improving rendering quality effectively. In addition, it introduces a selective gradient loss to enhance the optimization of scene textures and scene geometries, leading to high-quality rendering with small anchor features. Extensive experiments over multiple widely adopted benchmarks show that SOGS achieves superior rendering quality in novel view synthesis with clearly reduced model size.
DiffAge3D: Diffusion-based 3D-aware Face Aging
Aug 28, 2024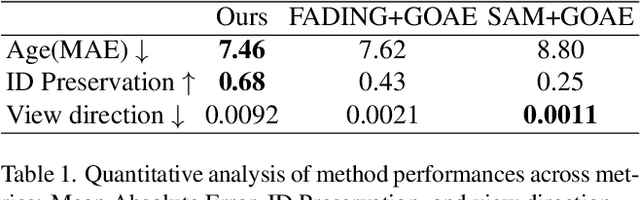
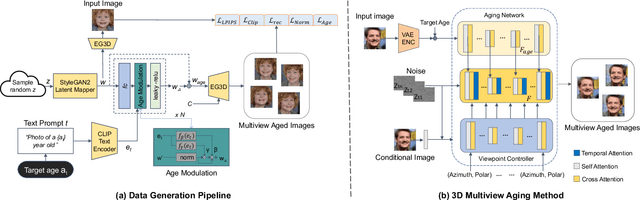
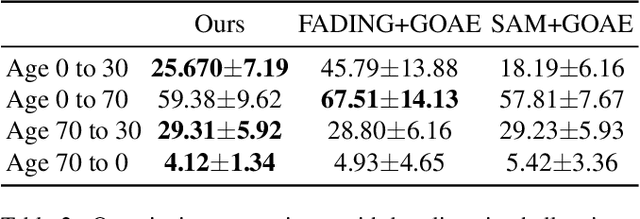

Face aging is the process of converting an individual's appearance to a younger or older version of themselves. Existing face aging techniques have been limited to 2D settings, which often weaken their applications as there is a growing demand for 3D face modeling. Moreover, existing aging methods struggle to perform faithful aging, maintain identity, and retain the fine details of the input images. Given these limitations and the need for a 3D-aware aging method, we propose DiffAge3D, the first 3D-aware aging framework that not only performs faithful aging and identity preservation but also operates in a 3D setting. Our aging framework allows to model the aging and camera pose separately by only taking a single image with a target age. Our framework includes a robust 3D-aware aging dataset generation pipeline by utilizing a pre-trained 3D GAN and the rich text embedding capabilities within CLIP model. Notably, we do not employ any inversion bottleneck in dataset generation. Instead, we randomly generate training samples from the latent space of 3D GAN, allowing us to manipulate the rich latent space of GAN to generate ages even with large gaps. With the generated dataset, we train a viewpoint-aware diffusion-based aging model to control the camera pose and facial age. Through quantitative and qualitative evaluations, we demonstrate that DiffAge3D outperforms existing methods, particularly in multiview-consistent aging and fine details preservation.
Lite2Relight: 3D-aware Single Image Portrait Relighting
Jul 15, 2024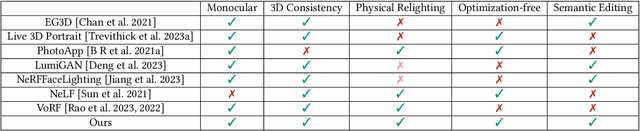
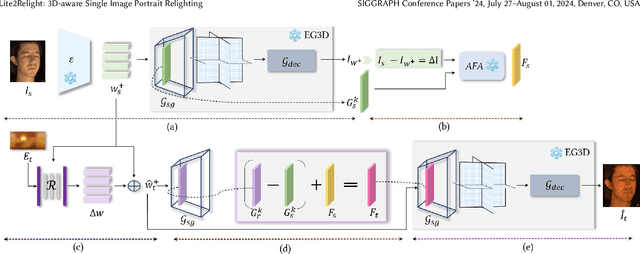
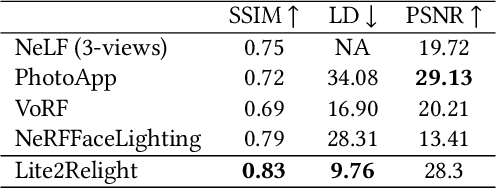

Achieving photorealistic 3D view synthesis and relighting of human portraits is pivotal for advancing AR/VR applications. Existing methodologies in portrait relighting demonstrate substantial limitations in terms of generalization and 3D consistency, coupled with inaccuracies in physically realistic lighting and identity preservation. Furthermore, personalization from a single view is difficult to achieve and often requires multiview images during the testing phase or involves slow optimization processes. This paper introduces Lite2Relight, a novel technique that can predict 3D consistent head poses of portraits while performing physically plausible light editing at interactive speed. Our method uniquely extends the generative capabilities and efficient volumetric representation of EG3D, leveraging a lightstage dataset to implicitly disentangle face reflectance and perform relighting under target HDRI environment maps. By utilizing a pre-trained geometry-aware encoder and a feature alignment module, we map input images into a relightable 3D space, enhancing them with a strong face geometry and reflectance prior. Through extensive quantitative and qualitative evaluations, we show that our method outperforms the state-of-the-art methods in terms of efficacy, photorealism, and practical application. This includes producing 3D-consistent results of the full head, including hair, eyes, and expressions. Lite2Relight paves the way for large-scale adoption of photorealistic portrait editing in various domains, offering a robust, interactive solution to a previously constrained problem. Project page: https://vcai.mpi-inf.mpg.de/projects/Lite2Relight/
Zero-Shot Video Semantic Segmentation based on Pre-Trained Diffusion Models
May 27, 2024We introduce the first zero-shot approach for Video Semantic Segmentation (VSS) based on pre-trained diffusion models. A growing research direction attempts to employ diffusion models to perform downstream vision tasks by exploiting their deep understanding of image semantics. Yet, the majority of these approaches have focused on image-related tasks like semantic correspondence and segmentation, with less emphasis on video tasks such as VSS. Ideally, diffusion-based image semantic segmentation approaches can be applied to videos in a frame-by-frame manner. However, we find their performance on videos to be subpar due to the absence of any modeling of temporal information inherent in the video data. To this end, we tackle this problem and introduce a framework tailored for VSS based on pre-trained image and video diffusion models. We propose building a scene context model based on the diffusion features, where the model is autoregressively updated to adapt to scene changes. This context model predicts per-frame coarse segmentation maps that are temporally consistent. To refine these maps further, we propose a correspondence-based refinement strategy that aggregates predictions temporally, resulting in more confident predictions. Finally, we introduce a masked modulation approach to upsample the coarse maps to the full resolution at a high quality. Experiments show that our proposed approach outperforms existing zero-shot image semantic segmentation approaches significantly on various VSS benchmarks without any training or fine-tuning. Moreover, it rivals supervised VSS approaches on the VSPW dataset despite not being explicitly trained for VSS.