 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic EventNeRF: Reconstructing General Dynamic Scenes from Multi-view Event Cameras
Dec 09, 2024



Volumetric reconstruction of dynamic scenes is an important problem in computer vision. It is especially challenging in poor lighting and with fast motion. It is partly due to the limitations of RGB cameras: To capture fast motion without much blur, the framerate must be increased, which in turn requires more lighting. In contrast, event cameras, which record changes in pixel brightness asynchronously, are much less dependent on lighting, making them more suitable for recording fast motion. We hence propose the first method to spatiotemporally reconstruct a scene from sparse multi-view event streams and sparse RGB frames. We train a sequence of cross-faded time-conditioned NeRF models, one per short recording segment. The individual segments are supervised with a set of event- and RGB-based losses and sparse-view regularisation. We assemble a real-world multi-view camera rig with six static event cameras around the object and record a benchmark multi-view event stream dataset of challenging motions. Our work outperforms RGB-based baselines, producing state-of-the-art results, and opens up the topic of multi-view event-based reconstruction as a new path for fast scene capture beyond RGB cameras. The code and the data will be released soon at https://4dqv.mpi-inf.mpg.de/DynEventNeRF/
Lite2Relight: 3D-aware Single Image Portrait Relighting
Jul 15, 2024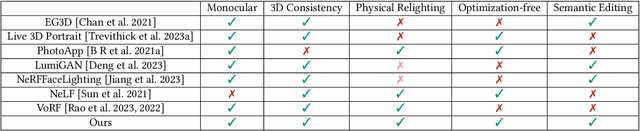
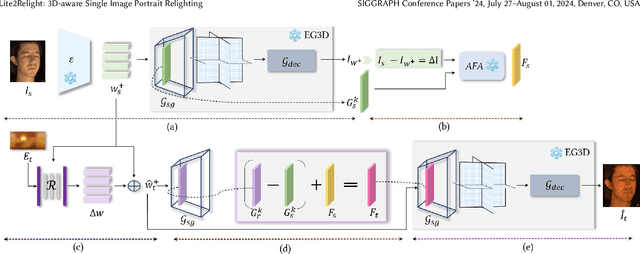
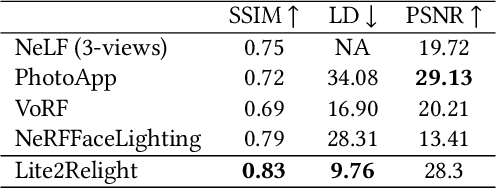

Achieving photorealistic 3D view synthesis and relighting of human portraits is pivotal for advancing AR/VR applications. Existing methodologies in portrait relighting demonstrate substantial limitations in terms of generalization and 3D consistency, coupled with inaccuracies in physically realistic lighting and identity preservation. Furthermore, personalization from a single view is difficult to achieve and often requires multiview images during the testing phase or involves slow optimization processes. This paper introduces Lite2Relight, a novel technique that can predict 3D consistent head poses of portraits while performing physically plausible light editing at interactive speed. Our method uniquely extends the generative capabilities and efficient volumetric representation of EG3D, leveraging a lightstage dataset to implicitly disentangle face reflectance and perform relighting under target HDRI environment maps. By utilizing a pre-trained geometry-aware encoder and a feature alignment module, we map input images into a relightable 3D space, enhancing them with a strong face geometry and reflectance prior. Through extensive quantitative and qualitative evaluations, we show that our method outperforms the state-of-the-art methods in terms of efficacy, photorealism, and practical application. This includes producing 3D-consistent results of the full head, including hair, eyes, and expressions. Lite2Relight paves the way for large-scale adoption of photorealistic portrait editing in various domains, offering a robust, interactive solution to a previously constrained problem. Project page: https://vcai.mpi-inf.mpg.de/projects/Lite2Relight/
Live2Diff: Live Stream Translation via Uni-directional Attention in Video Diffusion Models
Jul 11, 2024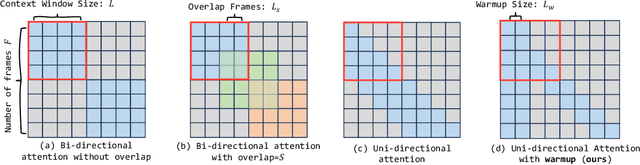
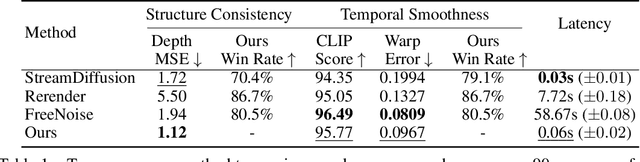
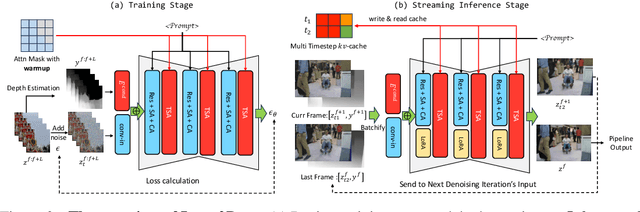
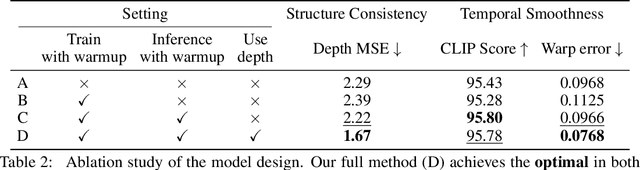
Large Language Models have shown remarkable efficacy in generating streaming data such as text and audio, thanks to their temporally uni-directional attention mechanism, which models correlations between the current token and previous tokens. However, video streaming remains much less explored, despite a growing need for live video processing. State-of-the-art video diffusion models leverage bi-directional temporal attention to model the correlations between the current frame and all the surrounding (i.e. including future) frames, which hinders them from processing streaming videos. To address this problem, we present Live2Diff, the first attempt at designing a video diffusion model with uni-directional temporal attention, specifically targeting live streaming video translation. Compared to previous works, our approach ensures temporal consistency and smoothness by correlating the current frame with its predecessors and a few initial warmup frames, without any future frames. Additionally, we use a highly efficient denoising scheme featuring a KV-cache mechanism and pipelining, to facilitate streaming video translation at interactive framerates. Extensive experiments demonstrate the effectiveness of the proposed attention mechanism and pipeline, outperforming previous methods in terms of temporal smoothness and/or efficiency.
An Implicit Parametric Morphable Dental Model
Nov 21, 2022



3D Morphable models of the human body capture variations among subjects and are useful in reconstruction and editing applications. Current dental models use an explicit mesh scene representation and model only the teeth, ignoring the gum. In this work, we present the first parametric 3D morphable dental model for both teeth and gum. Our model uses an implicit scene representation and is learned from rigidly aligned scans. It is based on a component-wise representation for each tooth and the gum, together with a learnable latent code for each of such components. It also learns a template shape thus enabling several applications such as segmentation, interpolation, and tooth replacement. Our reconstruction quality is on par with the most advanced global implicit representations while enabling novel applications. Project page: https://vcai.mpi-inf.mpg.de/projects/DMM/
StyleVideoGAN: A Temporal Generative Model using a Pretrained StyleGAN
Jul 15, 2021

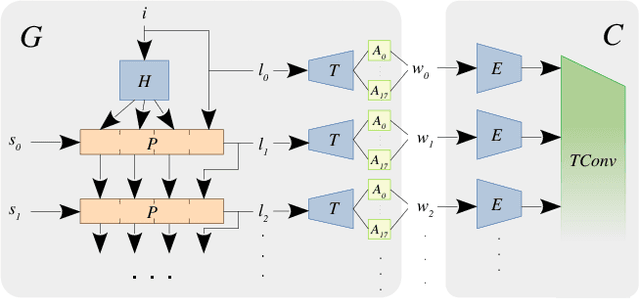
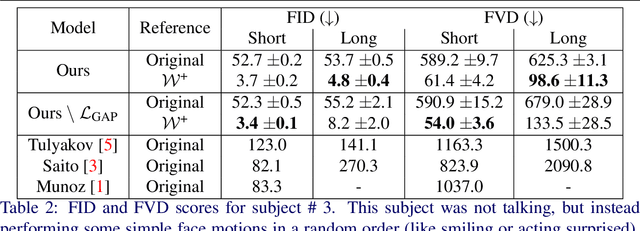
Generative adversarial models (GANs) continue to produce advances in terms of the visual quality of still images, as well as the learning of temporal correlations. However, few works manage to combine these two interesting capabilities for the synthesis of video content: Most methods require an extensive training dataset in order to learn temporal correlations, while being rather limited in the resolution and visual quality of their output frames. In this paper, we present a novel approach to the video synthesis problem that helps to greatly improve visual quality and drastically reduce the amount of training data and resources necessary for generating video content. Our formulation separates the spatial domain, in which individual frames are synthesized, from the temporal domain, in which motion is generated. For the spatial domain we make use of a pre-trained StyleGAN network, the latent space of which allows control over the appearance of the objects it was trained for. The expressive power of this model allows us to embed our training videos in the StyleGAN latent space. Our temporal architecture is then trained not on sequences of RGB frames, but on sequences of StyleGAN latent codes. The advantageous properties of the StyleGAN space simplify the discovery of temporal correlations. We demonstrate that it suffices to train our temporal architecture on only 10 minutes of footage of 1 subject for about 6 hours. After training, our model can not only generate new portrait videos for the training subject, but also for any random subject which can be embedded in the StyleGAN space.
VideoForensicsHQ: Detecting High-quality Manipulated Face Videos
May 20, 2020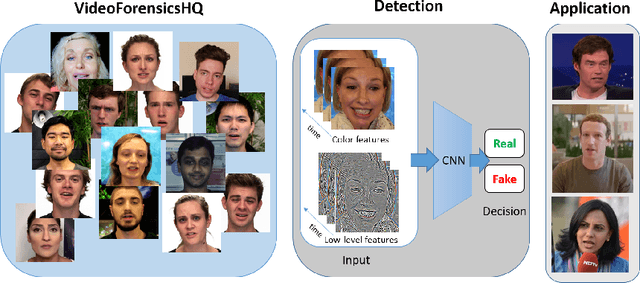

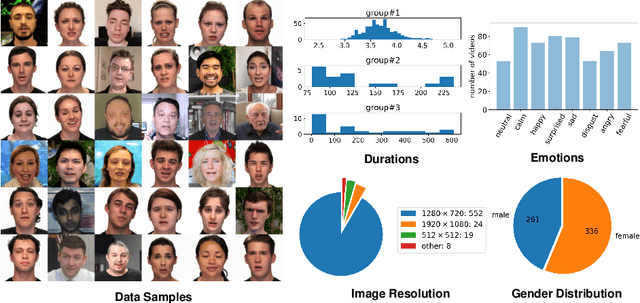

New approaches to synthesize and manipulate face videos at very high quality have paved the way for new applications in computer animation, virtual and augmented reality, or face video analysis. However, there are concerns that they may be used in a malicious way, e.g. to manipulate videos of public figures, politicians or reporters, to spread false information. The research community therefore developed techniques for automated detection of modified imagery, and assembled benchmark datasets showing manipulatons by state-of-the-art techniques. In this paper, we contribute to this initiative in two ways: First, we present a new audio-visual benchmark dataset. It shows some of the highest quality visual manipulations available today. Human observers find them significantly harder to identify as forged than videos from other benchmarks. Furthermore we propose new family of deep-learning-based fake detectors, demonstrating that existing detectors are not well-suited for detecting fakes of a quality as high as presented in our dataset. Our detectors examine spatial and temporal features. This allows them to outperform existing approaches both in terms of high detection accuracy and generalization to unseen fake generation methods and unseen identities.