 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEGO-Puzzles: How Good Are MLLMs at Multi-Step Spatial Reasoning?
Mar 25, 2025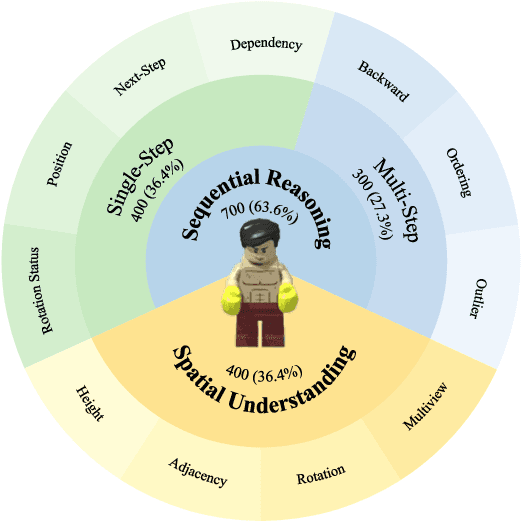
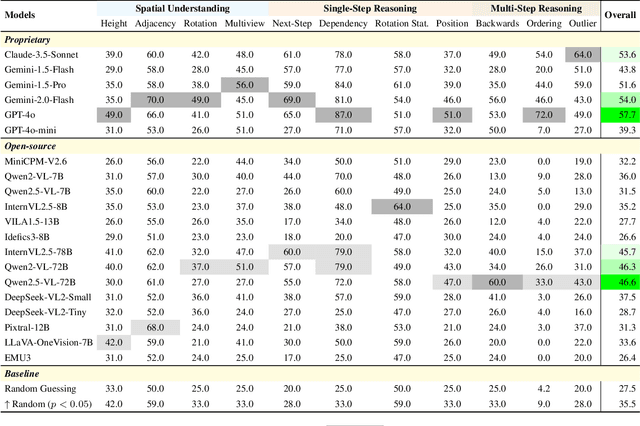
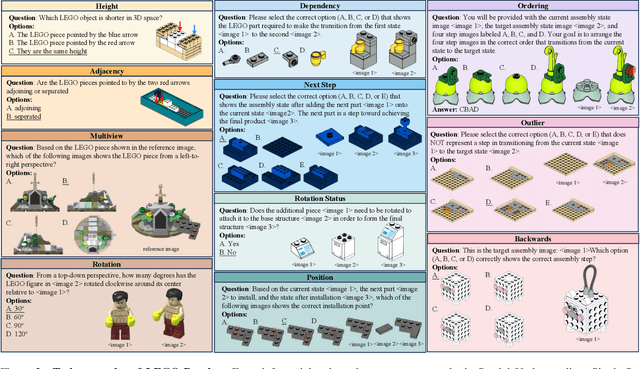
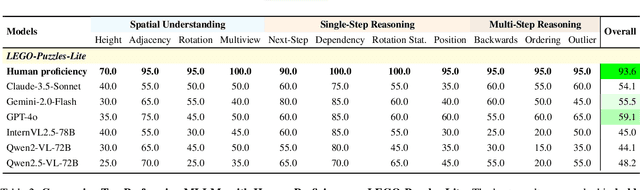
Multi-step spatial reasoning entails understanding and reasoning about spatial relationships across multiple sequential steps, which is crucial for tackling complex real-world applications, such as robotic manipulation, autonomous navigation, and automated assembly. To assess how well current Multimodal Large Language Models (MLLMs) have acquired this fundamental capability, we introduce \textbf{LEGO-Puzzles}, a scalable benchmark designed to evaluate both \textbf{spatial understanding} and \textbf{sequential reasoning} in MLLMs through LEGO-based tasks. LEGO-Puzzles consists of 1,100 carefully curated visual question-answering (VQA) samples spanning 11 distinct tasks, ranging from basic spatial understanding to complex multi-step reasoning. Based on LEGO-Puzzles, we conduct a comprehensive evaluation of state-of-the-art MLLMs and uncover significant limitations in their spatial reasoning capabilities: even the most powerful MLLMs can answer only about half of the test cases, whereas human participants achieve over 90\% accuracy. In addition to VQA tasks, we evaluate MLLMs' abilities to generate LEGO images following assembly illustrations. Our experiments show that only Gemini-2.0-Flash and GPT-4o exhibit a limited ability to follow these instructions, while other MLLMs either replicate the input image or generate completely irrelevant outputs. Overall, LEGO-Puzzles exposes critical deficiencies in existing MLLMs' spatial understanding and sequential reasoning capabilities, and underscores the need for further advancements in multimodal spatial reasoning.
Live2Diff: Live Stream Translation via Uni-directional Attention in Video Diffusion Models
Jul 11, 2024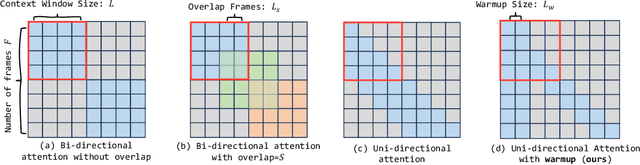
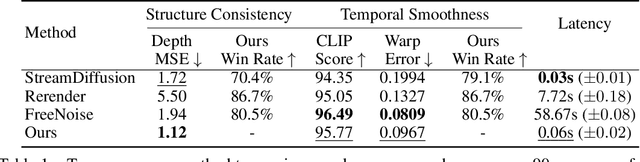
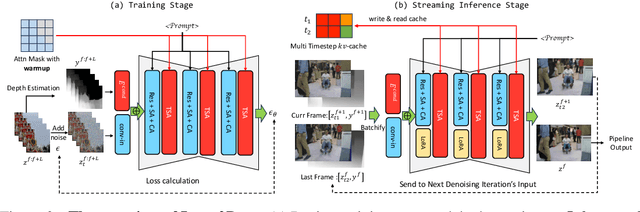
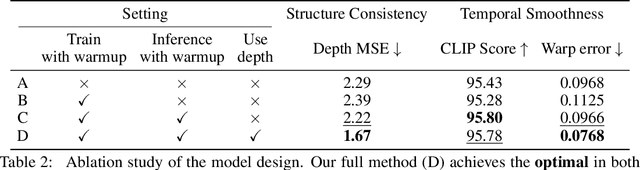
Large Language Models have shown remarkable efficacy in generating streaming data such as text and audio, thanks to their temporally uni-directional attention mechanism, which models correlations between the current token and previous tokens. However, video streaming remains much less explored, despite a growing need for live video processing. State-of-the-art video diffusion models leverage bi-directional temporal attention to model the correlations between the current frame and all the surrounding (i.e. including future) frames, which hinders them from processing streaming videos. To address this problem, we present Live2Diff, the first attempt at designing a video diffusion model with uni-directional temporal attention, specifically targeting live streaming video translation. Compared to previous works, our approach ensures temporal consistency and smoothness by correlating the current frame with its predecessors and a few initial warmup frames, without any future frames. Additionally, we use a highly efficient denoising scheme featuring a KV-cache mechanism and pipelining, to facilitate streaming video translation at interactive framerates. Extensive experiments demonstrate the effectiveness of the proposed attention mechanism and pipeline, outperforming previous methods in terms of temporal smoothness and/or efficiency.
FoleyCrafter: Bring Silent Videos to Life with Lifelike and Synchronized Sounds
Jul 01, 2024
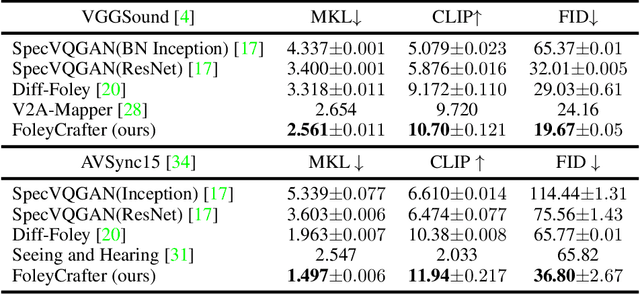
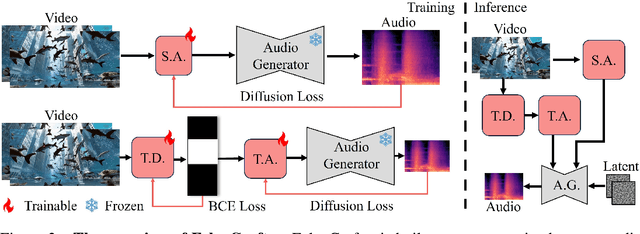

We study Neural Foley, the automatic generation of high-quality sound effects synchronizing with videos, enabling an immersive audio-visual experience. Despite its wide range of applications, existing approaches encounter limitations when it comes to simultaneously synthesizing high-quality and video-aligned (i.e.,, semantic relevant and temporal synchronized) sounds. To overcome these limitations, we propose FoleyCrafter, a novel framework that leverages a pre-trained text-to-audio model to ensure high-quality audio generation. FoleyCrafter comprises two key components: the semantic adapter for semantic alignment and the temporal controller for precise audio-video synchronization. The semantic adapter utilizes parallel cross-attention layers to condition audio generation on video features, producing realistic sound effects that are semantically relevant to the visual content. Meanwhile, the temporal controller incorporates an onset detector and a timestampbased adapter to achieve precise audio-video alignment. One notable advantage of FoleyCrafter is its compatibility with text prompts, enabling the use of text descriptions to achieve controllable and diverse video-to-audio generation according to user intents. We conduct extensive quantitative and qualitative experiments on standard benchmarks to verify the effectiveness of FoleyCrafter. Models and codes are available at https://github.com/open-mmlab/FoleyCrafter.
PIA: Your Personalized Image Animator via Plug-and-Play Modules in Text-to-Image Models
Dec 21, 2023Recent advancements in personalized text-to-image (T2I) models have revolutionized content creation, empowering non-experts to generate stunning images with unique styles. While promising, adding realistic motions into these personalized images by text poses significant challenges in preserving distinct styles, high-fidelity details, and achieving motion controllability by text. In this paper, we present PIA, a Personalized Image Animator that excels in aligning with condition images, achieving motion controllability by text, and the compatibility with various personalized T2I models without specific tuning. To achieve these goals, PIA builds upon a base T2I model with well-trained temporal alignment layers, allowing for the seamless transformation of any personalized T2I model into an image animation model. A key component of PIA is the introduction of the condition module, which utilizes the condition frame and inter-frame affinity as input to transfer appearance information guided by the affinity hint for individual frame synthesis in the latent space. This design mitigates the challenges of appearance-related image alignment within and allows for a stronger focus on aligning with motion-related guidance.