 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
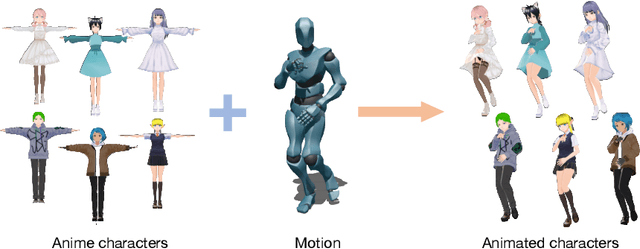
CharacterShot: Controllable and Consistent 4D Character Animation
Aug 10, 2025In this paper, we propose \textbf{CharacterShot}, a controllable and consistent 4D character animation framework that enables any individual designer to create dynamic 3D characters (i.e., 4D character animation) from a single reference character image and a 2D pose sequence. We begin by pretraining a powerful 2D character animation model based on a cutting-edge DiT-based image-to-video model, which allows for any 2D pose sequnce as controllable signal. We then lift the animation model from 2D to 3D through introducing dual-attention module together with camera prior to generate multi-view videos with spatial-temporal and spatial-view consistency. Finally, we employ a novel neighbor-constrained 4D gaussian splatting optimization on these multi-view videos, resulting in continuous and stable 4D character representations. Moreover, to improve character-centric performance, we construct a large-scale dataset Character4D, containing 13,115 unique characters with diverse appearances and motions, rendered from multiple viewpoints. Extensive experiments on our newly constructed benchmark, CharacterBench, demonstrate that our approach outperforms current state-of-the-art methods. Code, models, and datasets will be publicly available at https://github.com/Jeoyal/CharacterShot.
LEGO-Puzzles: How Good Are MLLMs at Multi-Step Spatial Reasoning?
Mar 25, 2025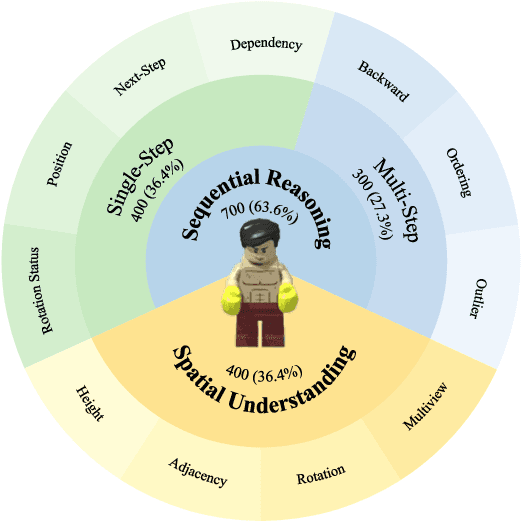
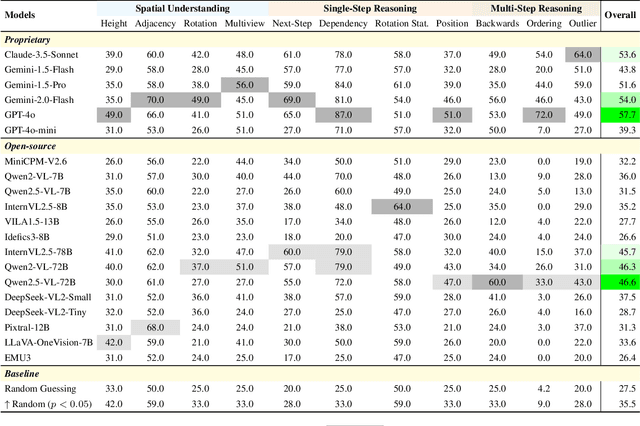
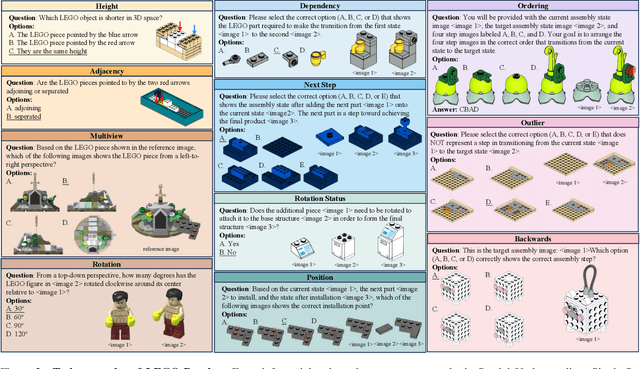
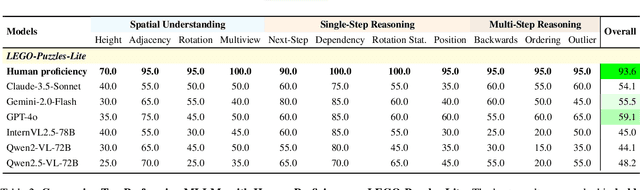
Multi-step spatial reasoning entails understanding and reasoning about spatial relationships across multiple sequential steps, which is crucial for tackling complex real-world applications, such as robotic manipulation, autonomous navigation, and automated assembly. To assess how well current Multimodal Large Language Models (MLLMs) have acquired this fundamental capability, we introduce \textbf{LEGO-Puzzles}, a scalable benchmark designed to evaluate both \textbf{spatial understanding} and \textbf{sequential reasoning} in MLLMs through LEGO-based tasks. LEGO-Puzzles consists of 1,100 carefully curated visual question-answering (VQA) samples spanning 11 distinct tasks, ranging from basic spatial understanding to complex multi-step reasoning. Based on LEGO-Puzzles, we conduct a comprehensive evaluation of state-of-the-art MLLMs and uncover significant limitations in their spatial reasoning capabilities: even the most powerful MLLMs can answer only about half of the test cases, whereas human participants achieve over 90\% accuracy. In addition to VQA tasks, we evaluate MLLMs' abilities to generate LEGO images following assembly illustrations. Our experiments show that only Gemini-2.0-Flash and GPT-4o exhibit a limited ability to follow these instructions, while other MLLMs either replicate the input image or generate completely irrelevant outputs. Overall, LEGO-Puzzles exposes critical deficiencies in existing MLLMs' spatial understanding and sequential reasoning capabilities, and underscores the need for further advancements in multimodal spatial reasoning.
HumanVid: Demystifying Training Data for Camera-controllable Human Image Animation
Jul 28, 2024

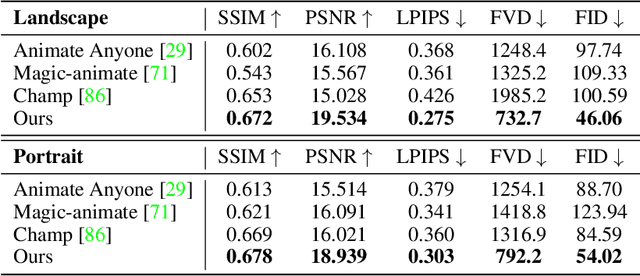
Human image animation involves generating videos from a character photo, allowing user control and unlocking potential for video and movie production. While recent approaches yield impressive results using high-quality training data, the inaccessibility of these datasets hampers fair and transparent benchmarking. Moreover, these approaches prioritize 2D human motion and overlook the significance of camera motions in videos, leading to limited control and unstable video generation. To demystify the training data, we present HumanVid, the first large-scale high-quality dataset tailored for human image animation, which combines crafted real-world and synthetic data. For the real-world data, we compile a vast collection of copyright-free real-world videos from the internet. Through a carefully designed rule-based filtering strategy, we ensure the inclusion of high-quality videos, resulting in a collection of 20K human-centric videos in 1080P resolution. Human and camera motion annotation is accomplished using a 2D pose estimator and a SLAM-based method. For the synthetic data, we gather 2,300 copyright-free 3D avatar assets to augment existing available 3D assets. Notably, we introduce a rule-based camera trajectory generation method, enabling the synthetic pipeline to incorporate diverse and precise camera motion annotation, which can rarely be found in real-world data. To verify the effectiveness of HumanVid, we establish a baseline model named CamAnimate, short for Camera-controllable Human Animation, that considers both human and camera motions as conditions. Through extensive experimentation, we demonstrate that such simple baseline training on our HumanVid achieves state-of-the-art performance in controlling both human pose and camera motions, setting a new benchmark. Code and data will be publicly available at https://github.com/zhenzhiwang/HumanVid/.
A Task is Worth One Word: Learning with Task Prompts for High-Quality Versatile Image Inpainting
Dec 12, 2023



Achieving high-quality versatile image inpainting, where user-specified regions are filled with plausible content according to user intent, presents a significant challenge. Existing methods face difficulties in simultaneously addressing context-aware image inpainting and text-guided object inpainting due to the distinct optimal training strategies required. To overcome this challenge, we introduce PowerPaint, the first high-quality and versatile inpainting model that excels in both tasks. First, we introduce learnable task prompts along with tailored fine-tuning strategies to guide the model's focus on different inpainting targets explicitly. This enables PowerPaint to accomplish various inpainting tasks by utilizing different task prompts, resulting in state-of-the-art performance. Second, we demonstrate the versatility of the task prompt in PowerPaint by showcasing its effectiveness as a negative prompt for object removal. Additionally, we leverage prompt interpolation techniques to enable controllable shape-guided object inpainting. Finally, we extensively evaluate PowerPaint on various inpainting benchmarks to demonstrate its superior performance for versatile image inpainting. We release our codes and models on our project page: https://powerpaint.github.io/.