 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcho-Memory: A Controlled Study of Memory in Action World Models
Jun 08, 2026We present \textbf{Echo-Memory}, a controlled study of memory mechanisms in action-conditioned world models. These models generate multi-segment videos from a first frame, text prompt, and camera-action sequence, but their central failure is often memory rather than local image synthesis: after the camera leaves and returns, the scene or salient object may silently change. Existing memory designs are hard to compare because gains are entangled with backbone, training, retrieval, and evaluation differences. Echo-Memory fixes the action-to-video interface and varies only how history is stored and read by the generator. Under a shared video diffusion backbone, optimizer, camera-action representation, sampler, and evaluation pipeline, we compare raw context, compression-based memory, spatial summaries with different read-out paths, and state-space recurrence. This matched matrix separates four otherwise conflated axes: \emph{capacity}, \emph{compression}, \emph{read-out}, and \emph{recurrence}. We also evaluate memory through a three-branch protocol: replay quality, in-domain loop revisit, and open-domain return probes. The branches routinely disagree, showing that replay fidelity is not a sufficient proxy for remembering a world. Three findings follow. Raw context is a strong capacity baseline and improves open-domain return far more than it improves replay metrics. Compactness is not a free substitute for capacity: aggressive spatial and hybrid-compression memories lose the salient evidence needed for return. Finally, block-wise state-space recurrence is the strongest open-domain return mechanism in our matrix, showing that the structure of implicit memory matters as much as the decision to use it. These results provide a compact protocol for studying memory in action world models beyond isolated replay metrics.
Echo-Infinity: Learning Evolving Memory for Real-Time Infinite Video Generation
Jun 03, 2026We present Echo Infinity, an autoregressive (AR) framework towards real-time infinite video generation that employs a learnable evolving memory to dynamically filter, abstract, and compress any-length history at constant cost. Existing methods mainly curate memory with predefined KV-cache schedules, fixed-ratio heuristic compression, or inference-time RoPE adaptation. These designs inevitably lose historical information and amplify compounding errors due to their limited cache window and ignorance of autoregressive generation noise. Inspired by human memory consolidation, Echo-Infinity replaces handcrafted memory curation with learnable Memory Query, which are updated by attention and a gating mechanism when past frames are evicted from the local window. The queries are optimized end-to-end with the video diffusion transformers (DiTs), forming an evolving memory that supports arbitrary compression ratios with constant computation independent of video length. They also act as a generalizable generation prior, improving quality even when only the optimized initial state is used. We further introduce Unified Relative RoPE Recipe, which anchors the sink frames to start from id 0 and lets the newest frame id grow at most to the DiTs' pretrained maximum temporal RoPE id throughout training and inference, freeing the model from the finite RoPE constraint and closing the train-test RoPE extrapolation gap. In long and short video generation, Echo-Infinity achieves state-of-the-art performance, and, to our knowledge, demonstrates promising 24-hour (>1.3 M frames) real-time rollouts for the first time, suggesting a practical path toward infinite video generation.
ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling
Mar 26, 2026Multi-shot video generation is crucial for long narrative storytelling, yet current bidirectional architectures suffer from limited interactivity and high latency. We propose ShotStream, a novel causal multi-shot architecture that enables interactive storytelling and efficient on-the-fly frame generation. By reformulating the task as next-shot generation conditioned on historical context, ShotStream allows users to dynamically instruct ongoing narratives via streaming prompts. We achieve this by first fine-tuning a text-to-video model into a bidirectional next-shot generator, which is then distilled into a causal student via Distribution Matching Distillation. To overcome the challenges of inter-shot consistency and error accumulation inherent in autoregressive generation, we introduce two key innovations. First, a dual-cache memory mechanism preserves visual coherence: a global context cache retains conditional frames for inter-shot consistency, while a local context cache holds generated frames within the current shot for intra-shot consistency. And a RoPE discontinuity indicator is employed to explicitly distinguish the two caches to eliminate ambiguity. Second, to mitigate error accumulation, we propose a two-stage distillation strategy. This begins with intra-shot self-forcing conditioned on ground-truth historical shots and progressively extends to inter-shot self-forcing using self-generated histories, effectively bridging the train-test gap. Extensive experiments demonstrate that ShotStream generates coherent multi-shot videos with sub-second latency, achieving 16 FPS on a single GPU. It matches or exceeds the quality of slower bidirectional models, paving the way for real-time interactive storytelling. Training and inference code, as well as the models, are available on our
LongVie 2: Multimodal Controllable Ultra-Long Video World Model
Dec 15, 2025Building video world models upon pretrained video generation systems represents an important yet challenging step toward general spatiotemporal intelligence. A world model should possess three essential properties: controllability, long-term visual quality, and temporal consistency. To this end, we take a progressive approach-first enhancing controllability and then extending toward long-term, high-quality generation. We present LongVie 2, an end-to-end autoregressive framework trained in three stages: (1) Multi-modal guidance, which integrates dense and sparse control signals to provide implicit world-level supervision and improve controllability; (2) Degradation-aware training on the input frame, bridging the gap between training and long-term inference to maintain high visual quality; and (3) History-context guidance, which aligns contextual information across adjacent clips to ensure temporal consistency. We further introduce LongVGenBench, a comprehensive benchmark comprising 100 high-resolution one-minute videos covering diverse real-world and synthetic environments. Extensive experiments demonstrate that LongVie 2 achieves state-of-the-art performance in long-range controllability, temporal coherence, and visual fidelity, and supports continuous video generation lasting up to five minutes, marking a significant step toward unified video world modeling.
FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution
Oct 14, 2025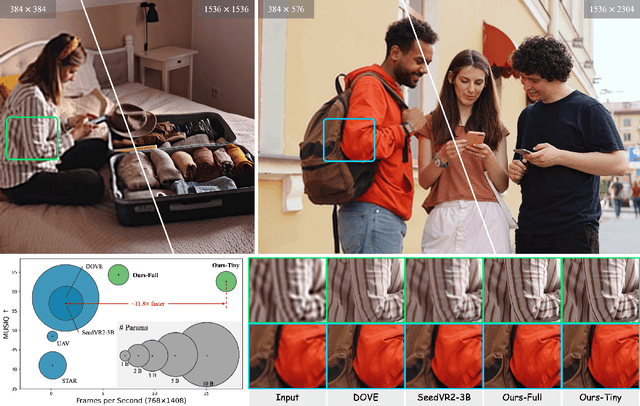
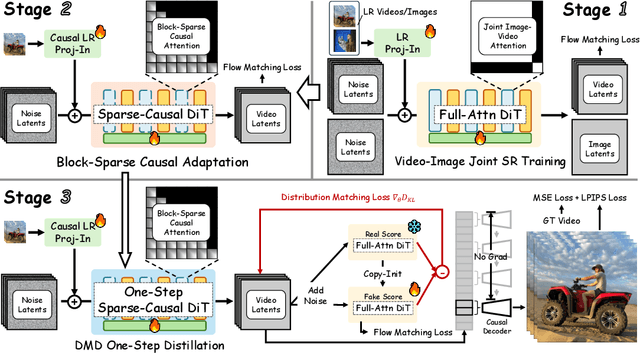
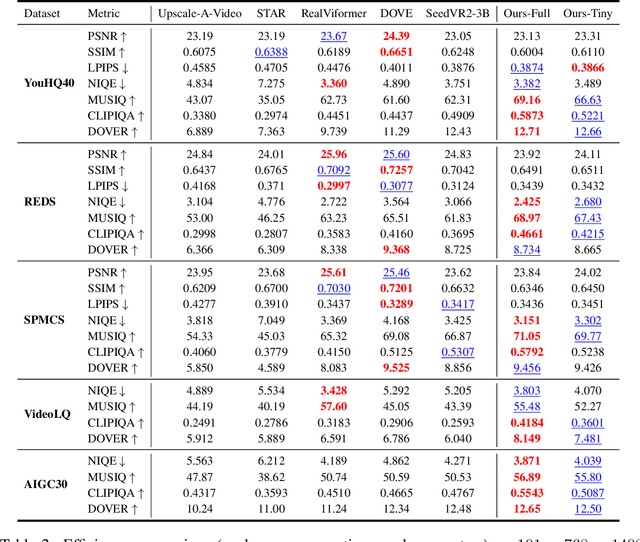
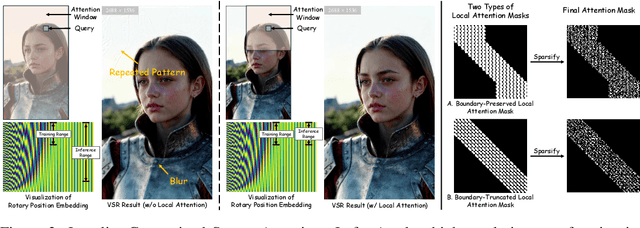
Diffusion models have recently advanced video restoration, but applying them to real-world video super-resolution (VSR) remains challenging due to high latency, prohibitive computation, and poor generalization to ultra-high resolutions. Our goal in this work is to make diffusion-based VSR practical by achieving efficiency, scalability, and real-time performance. To this end, we propose FlashVSR, the first diffusion-based one-step streaming framework towards real-time VSR. FlashVSR runs at approximately 17 FPS for 768x1408 videos on a single A100 GPU by combining three complementary innovations: (i) a train-friendly three-stage distillation pipeline that enables streaming super-resolution, (ii) locality-constrained sparse attention that cuts redundant computation while bridging the train-test resolution gap, and (iii) a tiny conditional decoder that accelerates reconstruction without sacrificing quality. To support large-scale training, we also construct VSR-120K, a new dataset with 120k videos and 180k images. Extensive experiments show that FlashVSR scales reliably to ultra-high resolutions and achieves state-of-the-art performance with up to 12x speedup over prior one-step diffusion VSR models. We will release the code, pretrained models, and dataset to foster future research in efficient diffusion-based VSR.
Safe-Sora: Safe Text-to-Video Generation via Graphical Watermarking
May 19, 2025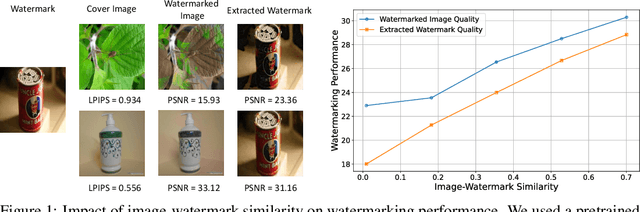
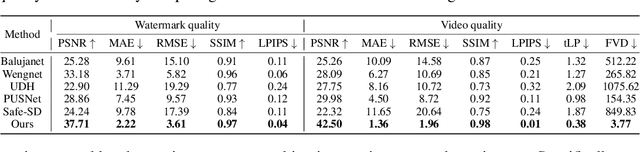
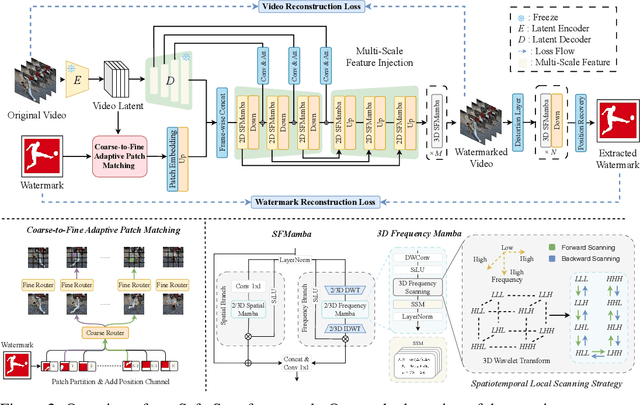

The explosive growth of generative video models has amplified the demand for reliable copyright preservation of AI-generated content. Despite its popularity in image synthesis, invisible generative watermarking remains largely underexplored in video generation. To address this gap, we propose Safe-Sora, the first framework to embed graphical watermarks directly into the video generation process. Motivated by the observation that watermarking performance is closely tied to the visual similarity between the watermark and cover content, we introduce a hierarchical coarse-to-fine adaptive matching mechanism. Specifically, the watermark image is divided into patches, each assigned to the most visually similar video frame, and further localized to the optimal spatial region for seamless embedding. To enable spatiotemporal fusion of watermark patches across video frames, we develop a 3D wavelet transform-enhanced Mamba architecture with a novel spatiotemporal local scanning strategy, effectively modeling long-range dependencies during watermark embedding and retrieval. To the best of our knowledge, this is the first attempt to apply state space models to watermarking, opening new avenues for efficient and robust watermark protection. Extensive experiments demonstrate that Safe-Sora achieves state-of-the-art performance in terms of video quality, watermark fidelity, and robustness, which is largely attributed to our proposals. We will release our code upon publication.
FlexiAct: Towards Flexible Action Control in Heterogeneous Scenarios
May 06, 2025Action customization involves generating videos where the subject performs actions dictated by input control signals. Current methods use pose-guided or global motion customization but are limited by strict constraints on spatial structure, such as layout, skeleton, and viewpoint consistency, reducing adaptability across diverse subjects and scenarios. To overcome these limitations, we propose FlexiAct, which transfers actions from a reference video to an arbitrary target image. Unlike existing methods, FlexiAct allows for variations in layout, viewpoint, and skeletal structure between the subject of the reference video and the target image, while maintaining identity consistency. Achieving this requires precise action control, spatial structure adaptation, and consistency preservation. To this end, we introduce RefAdapter, a lightweight image-conditioned adapter that excels in spatial adaptation and consistency preservation, surpassing existing methods in balancing appearance consistency and structural flexibility. Additionally, based on our observations, the denoising process exhibits varying levels of attention to motion (low frequency) and appearance details (high frequency) at different timesteps. So we propose FAE (Frequency-aware Action Extraction), which, unlike existing methods that rely on separate spatial-temporal architectures, directly achieves action extraction during the denoising process. Experiments demonstrate that our method effectively transfers actions to subjects with diverse layouts, skeletons, and viewpoints. We release our code and model weights to support further research at https://shiyi-zh0408.github.io/projectpages/FlexiAct/
Cobra: Efficient Line Art COlorization with BRoAder References
Apr 16, 2025The comic production industry requires reference-based line art colorization with high accuracy, efficiency, contextual consistency, and flexible control. A comic page often involves diverse characters, objects, and backgrounds, which complicates the coloring process. Despite advancements in diffusion models for image generation, their application in line art colorization remains limited, facing challenges related to handling extensive reference images, time-consuming inference, and flexible control. We investigate the necessity of extensive contextual image guidance on the quality of line art colorization. To address these challenges, we introduce Cobra, an efficient and versatile method that supports color hints and utilizes over 200 reference images while maintaining low latency. Central to Cobra is a Causal Sparse DiT architecture, which leverages specially designed positional encodings, causal sparse attention, and Key-Value Cache to effectively manage long-context references and ensure color identity consistency. Results demonstrate that Cobra achieves accurate line art colorization through extensive contextual reference, significantly enhancing inference speed and interactivity, thereby meeting critical industrial demands. We release our codes and models on our project page: https://zhuang2002.github.io/Cobra/.
ColorFlow: Retrieval-Augmented Image Sequence Colorization
Dec 16, 2024Automatic black-and-white image sequence colorization while preserving character and object identity (ID) is a complex task with significant market demand, such as in cartoon or comic series colorization. Despite advancements in visual colorization using large-scale generative models like diffusion models, challenges with controllability and identity consistency persist, making current solutions unsuitable for industrial application.To address this, we propose ColorFlow, a three-stage diffusion-based framework tailored for image sequence colorization in industrial applications. Unlike existing methods that require per-ID finetuning or explicit ID embedding extraction, we propose a novel robust and generalizable Retrieval Augmented Colorization pipeline for colorizing images with relevant color references. Our pipeline also features a dual-branch design: one branch for color identity extraction and the other for colorization, leveraging the strengths of diffusion models. We utilize the self-attention mechanism in diffusion models for strong in-context learning and color identity matching. To evaluate our model, we introduce ColorFlow-Bench, a comprehensive benchmark for reference-based colorization. Results show that ColorFlow outperforms existing models across multiple metrics, setting a new standard in sequential image colorization and potentially benefiting the art industry. We release our codes and models on our project page: https://zhuang2002.github.io/ColorFlow/.
TextureDiffusion: Target Prompt Disentangled Editing for Various Texture Transfer
Sep 15, 2024Recently, text-guided image editing has achieved significant success. However, existing methods can only apply simple textures like wood or gold when changing the texture of an object. Complex textures such as cloud or fire pose a challenge. This limitation stems from that the target prompt needs to contain both the input image content and <texture>, restricting the texture representation. In this paper, we propose TextureDiffusion, a tuning-free image editing method applied to various texture transfer. Initially, the target prompt is directly set to "<texture>", making the texture disentangled from the input image content to enhance texture representation. Subsequently, query features in self-attention and features in residual blocks are utilized to preserve the structure of the input image. Finally, to maintain the background, we introduce an edit localization technique which blends the self-attention results and the intermediate latents. Comprehensive experiments demonstrate that TextureDiffusion can harmoniously transfer various textures with excellent structure and background preservation.