 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikingBrain2.0: Brain-Inspired Foundation Models for Efficient Long-Context and Cross-Platform Inference
Apr 24, 2026Scaling context length is reshaping large-model development, yet full-attention Transformers suffer from prohibitive computation and inference bottlenecks at long sequences. A key challenge is to design foundation models that maintain performance and long-context efficiency with minimal training overhead. We introduce SpikingBrain2.0 (SpB2.0), a 5B model that advances both architecture and training efficiency of its predecessor. Our contributions are two-fold. (1) Architectural Innovation: We propose Dual-Space Sparse Attention (DSSA), an inter-layer hybrid of Sparse Softmax Attention (MoBA) and Sparse Linear Attention (SSE), achieving an improved performance-efficiency trade-off for long-context modeling. SpB2.0 further supports dual quantization paths: INT8-Spiking coding enables sparse event-driven computation, while FP8 coding accelerates inference on modern GPUs. (2) Enhanced Training Strategy: We develop an optimized Transformer-to-Hybrid (T2H) pipeline with dual conversion paths for LLMs and VLMs using curated open-source data. Empirically, SpB2.0-5B and SpB2.0-VL-5B recover most of the base Transformer (Qwen3-4B) capability with under 7k A100 GPU hours. SpB2.0 achieves a 10.13x TTFT speedup at 4M context and supports over 10M tokens on 8 A100 GPUs under vLLM, where full-attention models exceed memory limits. It also demonstrates strong cross-platform compatibility, enabling FP8 GPU inference (2.52x speedup at 250k) and efficient neuromorphic execution (64.31% sparsity, with 70.6% and 46.5% area and power reduction at 500MHz). Overall, SpikingBrain2.0 provides a practical pathway for lightweight, multimodal, spiking foundation models, highlighting the potential of combining brain-inspired mechanisms with efficient architectures for resource-constrained and edge scenarios.
HYDRA: Unifying Multi-modal Generation and Understanding via Representation-Harmonized Tokenization
Mar 17, 2026Unified Multimodal Models struggle to bridge the fundamental gap between the abstract representations needed for visual understanding and the detailed primitives required for generation. Existing approaches typically compromise by employing decoupled encoders, stacking representation encoder atop VAEs, or utilizing discrete quantization. However, these methods often disrupt information coherence and lead to optimization conflicts. To this end, we introduce HYDRA-TOK, a representation-harmonized pure ViT in the insight that visual modeling should evolve from generation to understanding. HYDRA-TOK reformulates the standard backbone into a progressive learner that transitions from a Gen-ViT, which captures structure-preserving primitives, to a Sem-ViT for semantic encoding. Crucially, this transition is mediated by a Generation-Semantic Bottleneck (GSB), which compresses features into a low-dimensional space to filter noise for robust synthesis, then restores dimensionality to empower complex semantic comprehension. Built upon this foundation, we present HYDRA, a native unified framework integrating perception and generation within a single parameter space. Extensive experiments establish HYDRA as a new state-of-the-art. It sets a benchmark in visual reconstruction (rFID 0.08) and achieves top-tier generation performance on GenEval (0.86), DPG-Bench (86.4), and WISE (0.53), while simultaneously outperforming previous native UMMs by an average of 10.0 points across eight challenging understanding benchmarks.
4DPC$^2$hat: Towards Dynamic Point Cloud Understanding with Failure-Aware Bootstrapping
Feb 03, 2026Point clouds provide a compact and expressive representation of 3D objects, and have recently been integrated into multimodal large language models (MLLMs). However, existing methods primarily focus on static objects, while understanding dynamic point cloud sequences remains largely unexplored. This limitation is mainly caused by the lack of large-scale cross-modal datasets and the difficulty of modeling motions in spatio-temporal contexts. To bridge this gap, we present 4DPC$^2$hat, the first MLLM tailored for dynamic point cloud understanding. To this end, we construct a large-scale cross-modal dataset 4DPC$^2$hat-200K via a meticulous two-stage pipeline consisting of topology-consistent 4D point construction and two-level captioning. The dataset contains over 44K dynamic object sequences, 700K point cloud frames, and 200K curated question-answer (QA) pairs, supporting inquiries about counting, temporal relationship, action, spatial relationship, and appearance. At the core of the framework, we introduce a Mamba-enhanced temporal reasoning MLLM to capture long-range dependencies and dynamic patterns among a point cloud sequence. Furthermore, we propose a failure-aware bootstrapping learning strategy that iteratively identifies model deficiencies and generates targeted QA supervision to continuously strengthen corresponding reasoning capabilities. Extensive experiments demonstrate that our 4DPC$^2$hat significantly improves action understanding and temporal reasoning compared with existing models, establishing a strong foundation for 4D dynamic point cloud understanding.
LoopViT: Scaling Visual ARC with Looped Transformers
Feb 02, 2026Recent advances in visual reasoning have leveraged vision transformers to tackle the ARC-AGI benchmark. However, we argue that the feed-forward architecture, where computational depth is strictly bound to parameter size, falls short of capturing the iterative, algorithmic nature of human induction. In this work, we propose a recursive architecture called Loop-ViT, which decouples reasoning depth from model capacity through weight-tied recurrence. Loop-ViT iterates a weight-tied Hybrid Block, combining local convolutions and global attention, to form a latent chain of thought. Crucially, we introduce a parameter-free Dynamic Exit mechanism based on predictive entropy: the model halts inference when its internal state ``crystallizes" into a low-uncertainty attractor. Empirical results on the ARC-AGI-1 benchmark validate this perspective: our 18M model achieves 65.8% accuracy, outperforming massive 73M-parameter ensembles. These findings demonstrate that adaptive iterative computation offers a far more efficient scaling axis for visual reasoning than simply increasing network width. The code is available at https://github.com/WenjieShu/LoopViT.
Omni-View: Unlocking How Generation Facilitates Understanding in Unified 3D Model based on Multiview images
Nov 10, 2025This paper presents Omni-View, which extends the unified multimodal understanding and generation to 3D scenes based on multiview images, exploring the principle that "generation facilitates understanding". Consisting of understanding model, texture module, and geometry module, Omni-View jointly models scene understanding, novel view synthesis, and geometry estimation, enabling synergistic interaction between 3D scene understanding and generation tasks. By design, it leverages the spatiotemporal modeling capabilities of its texture module responsible for appearance synthesis, alongside the explicit geometric constraints provided by its dedicated geometry module, thereby enriching the model's holistic understanding of 3D scenes. Trained with a two-stage strategy, Omni-View achieves a state-of-the-art score of 55.4 on the VSI-Bench benchmark, outperforming existing specialized 3D understanding models, while simultaneously delivering strong performance in both novel view synthesis and 3D scene generation.
SpikingBrain Technical Report: Spiking Brain-inspired Large Models
Sep 05, 2025Mainstream Transformer-based large language models face major efficiency bottlenecks: training computation scales quadratically with sequence length, and inference memory grows linearly, limiting long-context processing. Building large models on non-NVIDIA platforms also poses challenges for stable and efficient training. To address this, we introduce SpikingBrain, a family of brain-inspired models designed for efficient long-context training and inference. SpikingBrain leverages the MetaX GPU cluster and focuses on three aspects: (1) Model Architecture: linear and hybrid-linear attention architectures with adaptive spiking neurons; (2) Algorithmic Optimizations: an efficient, conversion-based training pipeline and a dedicated spike coding framework; (3) System Engineering: customized training frameworks, operator libraries, and parallelism strategies tailored to MetaX hardware. Using these techniques, we develop two models: SpikingBrain-7B, a linear LLM, and SpikingBrain-76B, a hybrid-linear MoE LLM. These models demonstrate the feasibility of large-scale LLM development on non-NVIDIA platforms. SpikingBrain achieves performance comparable to open-source Transformer baselines while using only about 150B tokens for continual pre-training. Our models significantly improve long-sequence training efficiency and deliver inference with (partially) constant memory and event-driven spiking behavior. For example, SpikingBrain-7B attains over 100x speedup in Time to First Token for 4M-token sequences. Training remains stable for weeks on hundreds of MetaX C550 GPUs, with the 7B model reaching a Model FLOPs Utilization of 23.4 percent. The proposed spiking scheme achieves 69.15 percent sparsity, enabling low-power operation. Overall, this work demonstrates the potential of brain-inspired mechanisms to drive the next generation of efficient and scalable large model design.
SVL: Spike-based Vision-language Pretraining for Efficient 3D Open-world Understanding
May 23, 2025Spiking Neural Networks (SNNs) provide an energy-efficient way to extract 3D spatio-temporal features. However, existing SNNs still exhibit a significant performance gap compared to Artificial Neural Networks (ANNs) due to inadequate pre-training strategies. These limitations manifest as restricted generalization ability, task specificity, and a lack of multimodal understanding, particularly in challenging tasks such as multimodal question answering and zero-shot 3D classification. To overcome these challenges, we propose a Spike-based Vision-Language (SVL) pretraining framework that empowers SNNs with open-world 3D understanding while maintaining spike-driven efficiency. SVL introduces two key components: (i) Multi-scale Triple Alignment (MTA) for label-free triplet-based contrastive learning across 3D, image, and text modalities, and (ii) Re-parameterizable Vision-Language Integration (Rep-VLI) to enable lightweight inference without relying on large text encoders. Extensive experiments show that SVL achieves a top-1 accuracy of 85.4% in zero-shot 3D classification, surpassing advanced ANN models, and consistently outperforms prior SNNs on downstream tasks, including 3D classification (+6.1%), DVS action recognition (+2.1%), 3D detection (+1.1%), and 3D segmentation (+2.1%) with remarkable efficiency. Moreover, SVL enables SNNs to perform open-world 3D question answering, sometimes outperforming ANNs. To the best of our knowledge, SVL represents the first scalable, generalizable, and hardware-friendly paradigm for 3D open-world understanding, effectively bridging the gap between SNNs and ANNs in complex open-world understanding tasks. Code is available https://github.com/bollossom/SVL.
Safe-Sora: Safe Text-to-Video Generation via Graphical Watermarking
May 19, 2025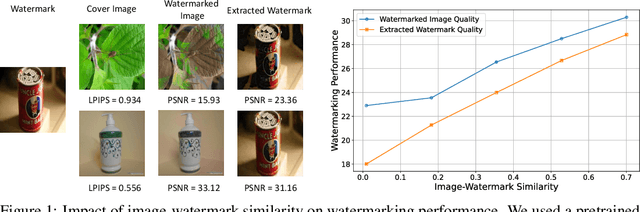
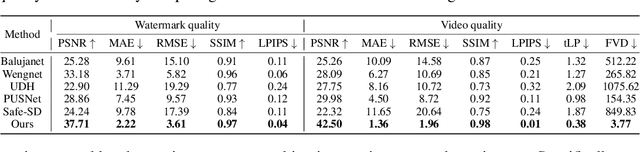
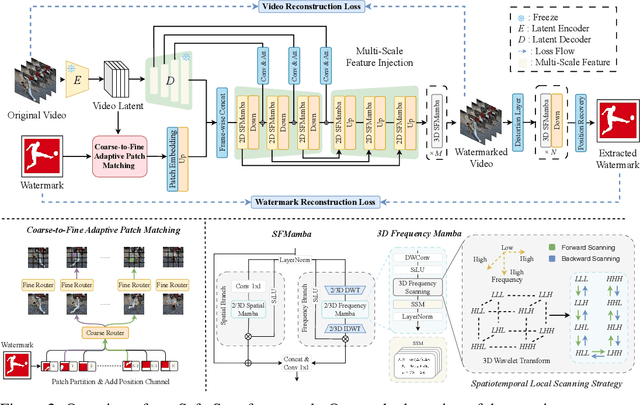

The explosive growth of generative video models has amplified the demand for reliable copyright preservation of AI-generated content. Despite its popularity in image synthesis, invisible generative watermarking remains largely underexplored in video generation. To address this gap, we propose Safe-Sora, the first framework to embed graphical watermarks directly into the video generation process. Motivated by the observation that watermarking performance is closely tied to the visual similarity between the watermark and cover content, we introduce a hierarchical coarse-to-fine adaptive matching mechanism. Specifically, the watermark image is divided into patches, each assigned to the most visually similar video frame, and further localized to the optimal spatial region for seamless embedding. To enable spatiotemporal fusion of watermark patches across video frames, we develop a 3D wavelet transform-enhanced Mamba architecture with a novel spatiotemporal local scanning strategy, effectively modeling long-range dependencies during watermark embedding and retrieval. To the best of our knowledge, this is the first attempt to apply state space models to watermarking, opening new avenues for efficient and robust watermark protection. Extensive experiments demonstrate that Safe-Sora achieves state-of-the-art performance in terms of video quality, watermark fidelity, and robustness, which is largely attributed to our proposals. We will release our code upon publication.
Safe-VAR: Safe Visual Autoregressive Model for Text-to-Image Generative Watermarking
Mar 14, 2025With the success of autoregressive learning in large language models, it has become a dominant approach for text-to-image generation, offering high efficiency and visual quality. However, invisible watermarking for visual autoregressive (VAR) models remains underexplored, despite its importance in misuse prevention. Existing watermarking methods, designed for diffusion models, often struggle to adapt to the sequential nature of VAR models. To bridge this gap, we propose Safe-VAR, the first watermarking framework specifically designed for autoregressive text-to-image generation. Our study reveals that the timing of watermark injection significantly impacts generation quality, and watermarks of different complexities exhibit varying optimal injection times. Motivated by this observation, we propose an Adaptive Scale Interaction Module, which dynamically determines the optimal watermark embedding strategy based on the watermark information and the visual characteristics of the generated image. This ensures watermark robustness while minimizing its impact on image quality. Furthermore, we introduce a Cross-Scale Fusion mechanism, which integrates mixture of both heads and experts to effectively fuse multi-resolution features and handle complex interactions between image content and watermark patterns. Experimental results demonstrate that Safe-VAR achieves state-of-the-art performance, significantly surpassing existing counterparts regarding image quality, watermarking fidelity, and robustness against perturbations. Moreover, our method exhibits strong generalization to an out-of-domain watermark dataset QR Codes.
Uni$\textbf{F}^2$ace: Fine-grained Face Understanding and Generation with Unified Multimodal Models
Mar 11, 2025


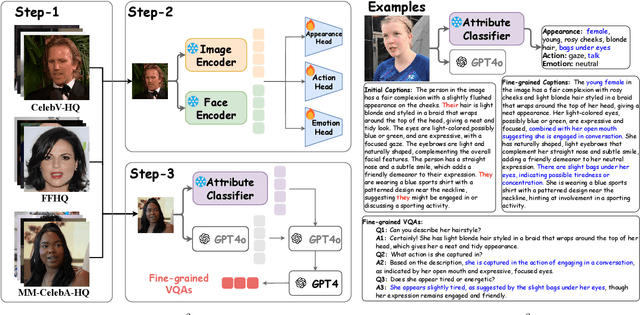
Unified multimodal models (UMMs) have emerged as a powerful paradigm in foundational computer vision research, demonstrating significant potential in both image understanding and generation. However, existing research in the face domain primarily focuses on $\textbf{coarse}$ facial attribute understanding, with limited capacity to handle $\textbf{fine-grained}$ facial attributes and without addressing generation capabilities. To overcome these limitations, we propose Uni$\textbf{F}^2$ace, the first UMM tailored specifically for fine-grained face understanding and generation. In general, we train Uni$\textbf{F}^2$ace on a self-constructed, specialized dataset utilizing two mutually beneficial diffusion techniques and a two-level mixture-of-experts architecture. Specifically, we first build a large-scale facial dataset, Uni$\textbf{F}^2$ace-130K, which contains 130K image-text pairs with one million question-answering pairs that span a wide range of facial attributes. Second, we establish a theoretical connection between discrete diffusion score matching and masked generative models, optimizing both evidence lower bounds simultaneously, which significantly improves the model's ability to synthesize facial details. Finally, we introduce both token-level and sequence-level mixture-of-experts, enabling efficient fine-grained representation learning for both understanding and generation tasks. Extensive experiments on Uni$\textbf{F}^2$ace-130K demonstrate that Uni$\textbf{F}^2$ace outperforms existing UMMs and generative models, achieving superior performance across both understanding and generation tasks.