 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe-Sora: Safe Text-to-Video Generation via Graphical Watermarking
May 19, 2025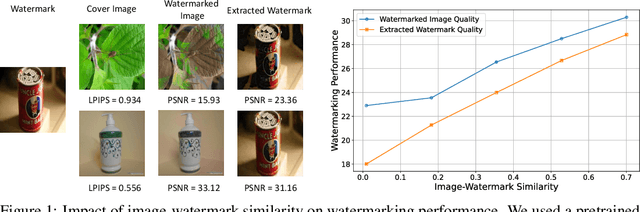
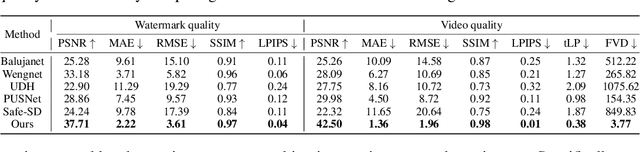
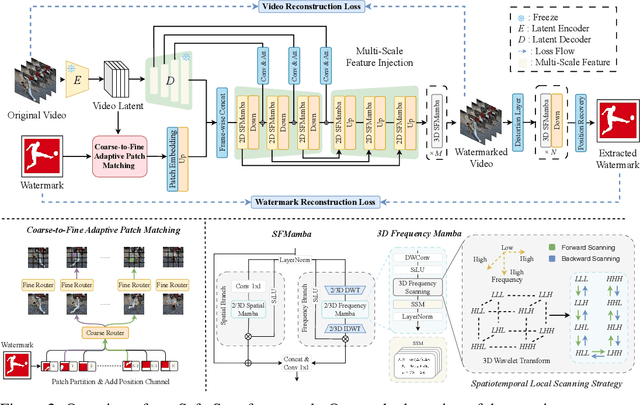

The explosive growth of generative video models has amplified the demand for reliable copyright preservation of AI-generated content. Despite its popularity in image synthesis, invisible generative watermarking remains largely underexplored in video generation. To address this gap, we propose Safe-Sora, the first framework to embed graphical watermarks directly into the video generation process. Motivated by the observation that watermarking performance is closely tied to the visual similarity between the watermark and cover content, we introduce a hierarchical coarse-to-fine adaptive matching mechanism. Specifically, the watermark image is divided into patches, each assigned to the most visually similar video frame, and further localized to the optimal spatial region for seamless embedding. To enable spatiotemporal fusion of watermark patches across video frames, we develop a 3D wavelet transform-enhanced Mamba architecture with a novel spatiotemporal local scanning strategy, effectively modeling long-range dependencies during watermark embedding and retrieval. To the best of our knowledge, this is the first attempt to apply state space models to watermarking, opening new avenues for efficient and robust watermark protection. Extensive experiments demonstrate that Safe-Sora achieves state-of-the-art performance in terms of video quality, watermark fidelity, and robustness, which is largely attributed to our proposals. We will release our code upon publication.
DiffoRA: Enabling Parameter-Efficient LLM Fine-Tuning via Differential Low-Rank Matrix Adaptation
Feb 13, 2025



The Parameter-Efficient Fine-Tuning (PEFT) methods have been extensively researched for large language models in the downstream tasks. Among all the existing approaches, the Low-Rank Adaptation (LoRA) has gained popularity for its streamlined design by incorporating low-rank matrices into existing pre-trained models. Though effective, LoRA allocates every module an identical low-rank matrix, which ignores the varying properties and contributions across different components. Moreover, the existing adaptive LoRA solutions rely highly on intuitive importance scoring indicators to adjust the interior rank of the decomposition matrices. In this paper, we propose a new PEFT scheme called DiffoRA, which is theoretically grounded and enables module-wise adoption of LoRA. At the core of our DiffoRA lies a Differential Adaptation Matrix (DAM) to determine which module is the most suitable and essential for fine-tuning. We explain how the designed matrix impacts the convergence rate and generalization capability of a pre-trained model. Furthermore, we construct the DAM via continuous relaxation and discretization with weight-sharing optimizations. We fully implement our DiffoRA and design comprehensive experiments to evaluate its performance. The experimental results demonstrate that our approach achieves the best model accuracy over all the state-of-the-art baselines across various benchmarks.
GReDP: A More Robust Approach for Differential Privacy Training with Gradient-Preserving Noise Reduction
Sep 18, 2024



Deep learning models have been extensively adopted in various regions due to their ability to represent hierarchical features, which highly rely on the training set and procedures. Thus, protecting the training process and deep learning algorithms is paramount in privacy preservation. Although Differential Privacy (DP) as a powerful cryptographic primitive has achieved satisfying results in deep learning training, the existing schemes still fall short in preserving model utility, i.e., they either invoke a high noise scale or inevitably harm the original gradients. To address the above issues, in this paper, we present a more robust approach for DP training called GReDP. Specifically, we compute the model gradients in the frequency domain and adopt a new approach to reduce the noise level. Unlike the previous work, our GReDP only requires half of the noise scale compared to DPSGD [1] while keeping all the gradient information intact. We present a detailed analysis of our method both theoretically and empirically. The experimental results show that our GReDP works consistently better than the baselines on all models and training settings.