 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBig2Small: A Unifying Neural Network Framework for Model Compression
Mar 31, 2026With the development of foundational models, model compression has become a critical requirement. Various model compression approaches have been proposed such as low-rank decomposition, pruning, quantization, ergodic dynamic systems, and knowledge distillation, which are based on different heuristics. To elevate the field from fragmentation to a principled discipline, we construct a unifying mathematical framework for model compression grounded in measure theory. We further demonstrate that each model compression technique is mathematically equivalent to a neural network subject to a regularization. Building upon this mathematical and structural equivalence, we propose an experimentally-verified data-free model compression framework, termed \textit{Big2Small}, which translates Implicit Neural Representations (INRs) from data domain to the domain of network parameters. \textit{Big2Small} trains compact INRs to encode the weights of larger models and reconstruct the weights during inference. To enhance reconstruction fidelity, we introduce Outlier-Aware Preprocessing to handle extreme weight values and a Frequency-Aware Loss function to preserve high-frequency details. Experiments on image classification and segmentation demonstrate that \textit{Big2Small} achieves competitive accuracy and compression ratios compared to state-of-the-art baselines.
PrivTune: Efficient and Privacy-Preserving Fine-Tuning of Large Language Models via Device-Cloud Collaboration
Dec 09, 2025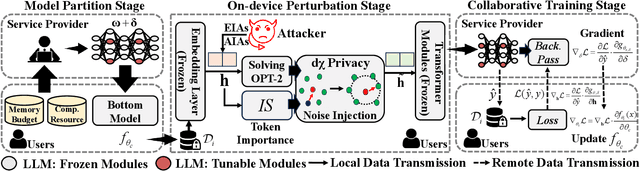
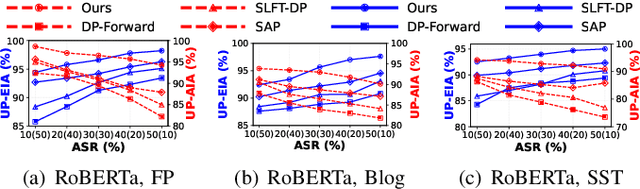


With the rise of large language models, service providers offer language models as a service, enabling users to fine-tune customized models via uploaded private datasets. However, this raises concerns about sensitive data leakage. Prior methods, relying on differential privacy within device-cloud collaboration frameworks, struggle to balance privacy and utility, exposing users to inference attacks or degrading fine-tuning performance. To address this, we propose PrivTune, an efficient and privacy-preserving fine-tuning framework via Split Learning (SL). The key idea of PrivTune is to inject crafted noise into token representations from the SL bottom model, making each token resemble the $n$-hop indirect neighbors. PrivTune formulates this as an optimization problem to compute the optimal noise vector, aligning with defense-utility goals. On this basis, it then adjusts the parameters (i.e., mean) of the $d_χ$-Privacy noise distribution to align with the optimization direction and scales the noise according to token importance to minimize distortion. Experiments on five datasets (covering both classification and generation tasks) against three embedding inversion and three attribute inference attacks show that, using RoBERTa on the Stanford Sentiment Treebank dataset, PrivTune reduces the attack success rate to 10% with only a 3.33% drop in utility performance, outperforming state-of-the-art baselines.
GReDP: A More Robust Approach for Differential Privacy Training with Gradient-Preserving Noise Reduction
Sep 18, 2024



Deep learning models have been extensively adopted in various regions due to their ability to represent hierarchical features, which highly rely on the training set and procedures. Thus, protecting the training process and deep learning algorithms is paramount in privacy preservation. Although Differential Privacy (DP) as a powerful cryptographic primitive has achieved satisfying results in deep learning training, the existing schemes still fall short in preserving model utility, i.e., they either invoke a high noise scale or inevitably harm the original gradients. To address the above issues, in this paper, we present a more robust approach for DP training called GReDP. Specifically, we compute the model gradients in the frequency domain and adopt a new approach to reduce the noise level. Unlike the previous work, our GReDP only requires half of the noise scale compared to DPSGD [1] while keeping all the gradient information intact. We present a detailed analysis of our method both theoretically and empirically. The experimental results show that our GReDP works consistently better than the baselines on all models and training settings.
Arondight: Red Teaming Large Vision Language Models with Auto-generated Multi-modal Jailbreak Prompts
Jul 21, 2024



Large Vision Language Models (VLMs) extend and enhance the perceptual abilities of Large Language Models (LLMs). Despite offering new possibilities for LLM applications, these advancements raise significant security and ethical concerns, particularly regarding the generation of harmful content. While LLMs have undergone extensive security evaluations with the aid of red teaming frameworks, VLMs currently lack a well-developed one. To fill this gap, we introduce Arondight, a standardized red team framework tailored specifically for VLMs. Arondight is dedicated to resolving issues related to the absence of visual modality and inadequate diversity encountered when transitioning existing red teaming methodologies from LLMs to VLMs. Our framework features an automated multi-modal jailbreak attack, wherein visual jailbreak prompts are produced by a red team VLM, and textual prompts are generated by a red team LLM guided by a reinforcement learning agent. To enhance the comprehensiveness of VLM security evaluation, we integrate entropy bonuses and novelty reward metrics. These elements incentivize the RL agent to guide the red team LLM in creating a wider array of diverse and previously unseen test cases. Our evaluation of ten cutting-edge VLMs exposes significant security vulnerabilities, particularly in generating toxic images and aligning multi-modal prompts. In particular, our Arondight achieves an average attack success rate of 84.5\% on GPT-4 in all fourteen prohibited scenarios defined by OpenAI in terms of generating toxic text. For a clearer comparison, we also categorize existing VLMs based on their safety levels and provide corresponding reinforcement recommendations. Our multimodal prompt dataset and red team code will be released after ethics committee approval. CONTENT WARNING: THIS PAPER CONTAINS HARMFUL MODEL RESPONSES.