 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffoRA: Enabling Parameter-Efficient LLM Fine-Tuning via Differential Low-Rank Matrix Adaptation
Feb 13, 2025



The Parameter-Efficient Fine-Tuning (PEFT) methods have been extensively researched for large language models in the downstream tasks. Among all the existing approaches, the Low-Rank Adaptation (LoRA) has gained popularity for its streamlined design by incorporating low-rank matrices into existing pre-trained models. Though effective, LoRA allocates every module an identical low-rank matrix, which ignores the varying properties and contributions across different components. Moreover, the existing adaptive LoRA solutions rely highly on intuitive importance scoring indicators to adjust the interior rank of the decomposition matrices. In this paper, we propose a new PEFT scheme called DiffoRA, which is theoretically grounded and enables module-wise adoption of LoRA. At the core of our DiffoRA lies a Differential Adaptation Matrix (DAM) to determine which module is the most suitable and essential for fine-tuning. We explain how the designed matrix impacts the convergence rate and generalization capability of a pre-trained model. Furthermore, we construct the DAM via continuous relaxation and discretization with weight-sharing optimizations. We fully implement our DiffoRA and design comprehensive experiments to evaluate its performance. The experimental results demonstrate that our approach achieves the best model accuracy over all the state-of-the-art baselines across various benchmarks.
GReDP: A More Robust Approach for Differential Privacy Training with Gradient-Preserving Noise Reduction
Sep 18, 2024



Deep learning models have been extensively adopted in various regions due to their ability to represent hierarchical features, which highly rely on the training set and procedures. Thus, protecting the training process and deep learning algorithms is paramount in privacy preservation. Although Differential Privacy (DP) as a powerful cryptographic primitive has achieved satisfying results in deep learning training, the existing schemes still fall short in preserving model utility, i.e., they either invoke a high noise scale or inevitably harm the original gradients. To address the above issues, in this paper, we present a more robust approach for DP training called GReDP. Specifically, we compute the model gradients in the frequency domain and adopt a new approach to reduce the noise level. Unlike the previous work, our GReDP only requires half of the noise scale compared to DPSGD [1] while keeping all the gradient information intact. We present a detailed analysis of our method both theoretically and empirically. The experimental results show that our GReDP works consistently better than the baselines on all models and training settings.
ezDPS: An Efficient and Zero-Knowledge Machine Learning Inference Pipeline
Dec 11, 2022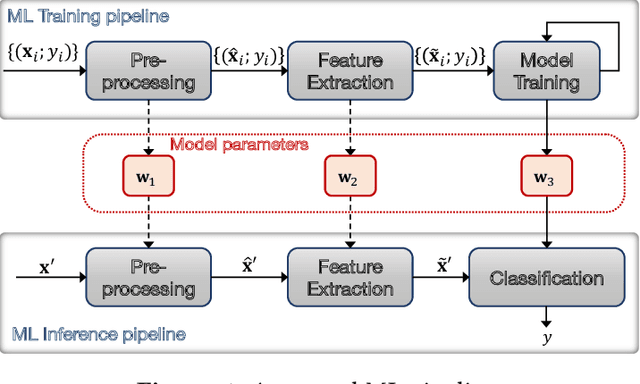



Machine Learning as a service (MLaaS) permits resource-limited clients to access powerful data analytics services ubiquitously. Despite its merits, MLaaS poses significant concerns regarding the integrity of delegated computation and the privacy of the server's model parameters. To address this issue, Zhang et al. (CCS'20) initiated the study of zero-knowledge Machine Learning (zkML). Few zkML schemes have been proposed afterward; however, they focus on sole ML classification algorithms that may not offer satisfactory accuracy or require large-scale training data and model parameters, which may not be desirable for some applications. We propose ezDPS, a new efficient and zero-knowledge ML inference scheme. Unlike prior works, ezDPS is a zkML pipeline in which the data is processed in multiple stages for high accuracy. Each stage of ezDPS is harnessed with an established ML algorithm that is shown to be effective in various applications, including Discrete Wavelet Transformation, Principal Components Analysis, and Support Vector Machine. We design new gadgets to prove ML operations effectively. We fully implemented ezDPS and assessed its performance on real datasets. Experimental results showed that ezDPS achieves one-to-three orders of magnitude more efficient than the generic circuit-based approach in all metrics while maintaining more desirable accuracy than single ML classification approaches.