 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Verifiable Neural Network Inference Service
Nov 13, 2024



Machine learning has revolutionized data analysis and pattern recognition, but its resource-intensive training has limited accessibility. Machine Learning as a Service (MLaaS) simplifies this by enabling users to delegate their data samples to an MLaaS provider and obtain the inference result using a pre-trained model. Despite its convenience, leveraging MLaaS poses significant privacy and reliability concerns to the client. Specifically, sensitive information from the client inquiry data can be leaked to an adversarial MLaaS provider. Meanwhile, the lack of a verifiability guarantee can potentially result in biased inference results or even unfair payment issues. While existing trustworthy machine learning techniques, such as those relying on verifiable computation or secure computation, offer solutions to privacy and reliability concerns, they fall short of simultaneously protecting the privacy of client data and providing provable inference verifiability. In this paper, we propose vPIN, a privacy-preserving and verifiable CNN inference scheme that preserves privacy for client data samples while ensuring verifiability for the inference. vPIN makes use of partial homomorphic encryption and commit-and-prove succinct non-interactive argument of knowledge techniques to achieve desirable security properties. In vPIN, we develop various optimization techniques to minimize the proving circuit for homomorphic inference evaluation thereby, improving the efficiency and performance of our technique. We fully implemented and evaluated our vPIN scheme on standard datasets (e.g., MNIST, CIFAR-10). Our experimental results show that vPIN achieves high efficiency in terms of proving time, verification time, and proof size, while providing client data privacy guarantees and provable verifiability.
ezDPS: An Efficient and Zero-Knowledge Machine Learning Inference Pipeline
Dec 11, 2022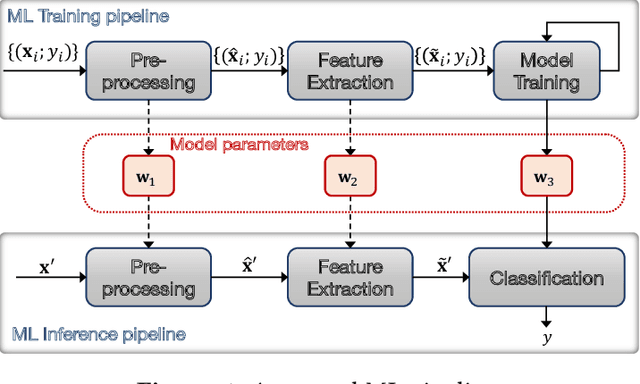



Machine Learning as a service (MLaaS) permits resource-limited clients to access powerful data analytics services ubiquitously. Despite its merits, MLaaS poses significant concerns regarding the integrity of delegated computation and the privacy of the server's model parameters. To address this issue, Zhang et al. (CCS'20) initiated the study of zero-knowledge Machine Learning (zkML). Few zkML schemes have been proposed afterward; however, they focus on sole ML classification algorithms that may not offer satisfactory accuracy or require large-scale training data and model parameters, which may not be desirable for some applications. We propose ezDPS, a new efficient and zero-knowledge ML inference scheme. Unlike prior works, ezDPS is a zkML pipeline in which the data is processed in multiple stages for high accuracy. Each stage of ezDPS is harnessed with an established ML algorithm that is shown to be effective in various applications, including Discrete Wavelet Transformation, Principal Components Analysis, and Support Vector Machine. We design new gadgets to prove ML operations effectively. We fully implemented ezDPS and assessed its performance on real datasets. Experimental results showed that ezDPS achieves one-to-three orders of magnitude more efficient than the generic circuit-based approach in all metrics while maintaining more desirable accuracy than single ML classification approaches.
A Distributed and Elastic Aggregation Service for Scalable Federated Learning Systems
Apr 16, 2022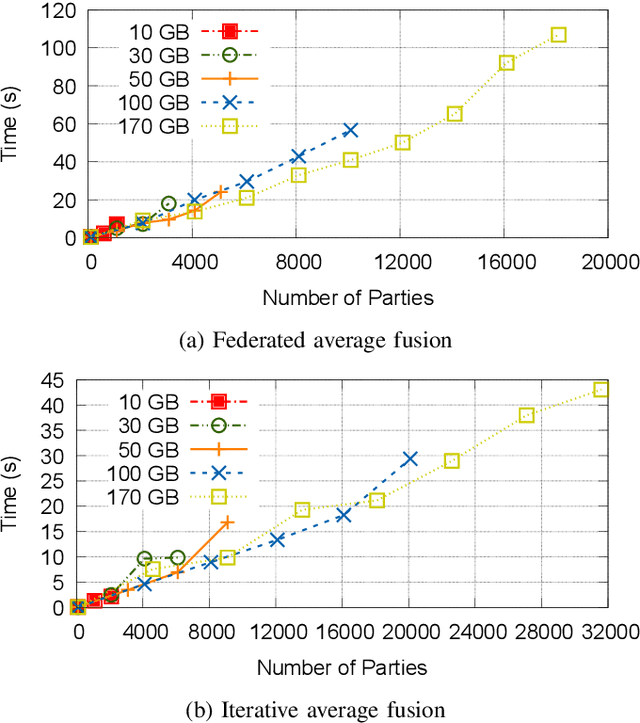
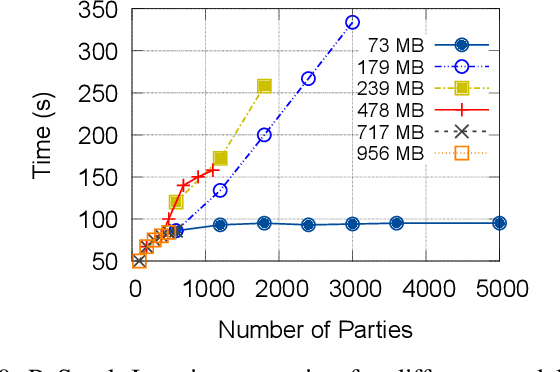
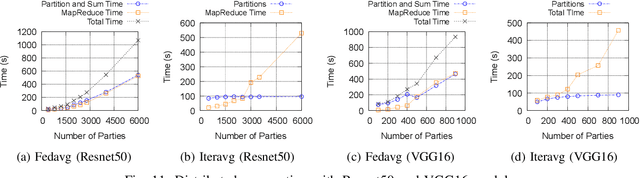
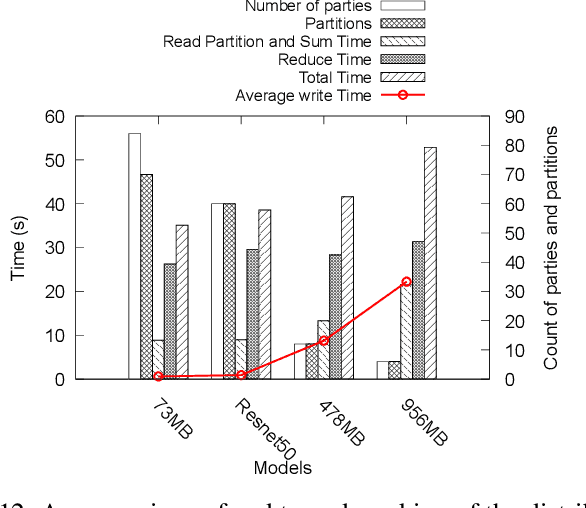
Federated Learning has promised a new approach to resolve the challenges in machine learning by bringing computation to the data. The popularity of the approach has led to rapid progress in the algorithmic aspects and the emergence of systems capable of simulating Federated Learning. State of art systems in Federated Learning support a single node aggregator that is insufficient to train a large corpus of devices or train larger-sized models. As the model size or the number of devices increase the single node aggregator incurs memory and computation burden while performing fusion tasks. It also faces communication bottlenecks when a large number of model updates are sent to a single node. We classify the workload for the aggregator into categories and propose a new aggregation service for handling each load. Our aggregation service is based on a holistic approach that chooses the best solution depending on the model update size and the number of clients. Our system provides a fault-tolerant, robust and efficient aggregation solution utilizing existing parallel and distributed frameworks. Through evaluation, we show the shortcomings of the state of art approaches and how a single solution is not suitable for all aggregation requirements. We also provide a comparison of current frameworks with our system through extensive experiments.