 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePI-FL: Personalized and Incentivized Federated Learning
Apr 27, 2023
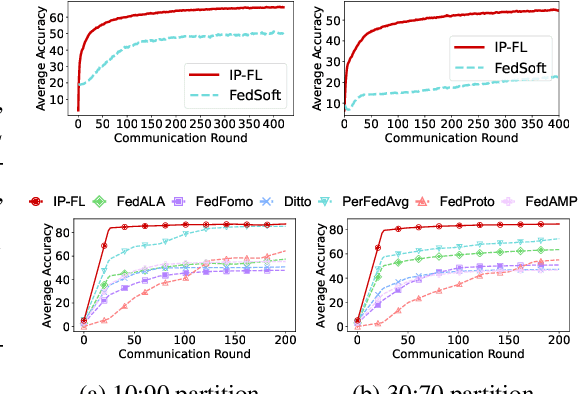

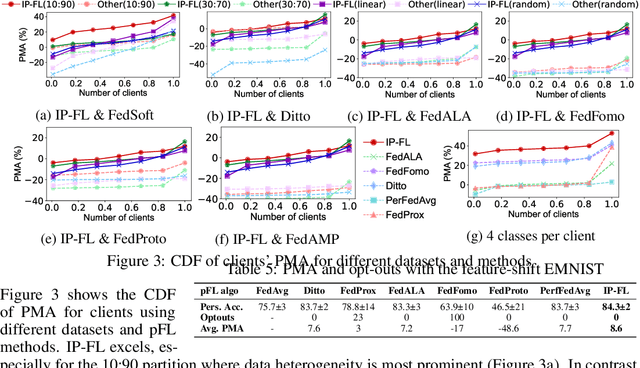
Personalized FL has been widely used to cater to heterogeneity challenges with non-IID data. A primary obstacle is considering the personalization process from the client's perspective to preserve their autonomy. Allowing the clients to participate in personalized FL decisions becomes significant due to privacy and security concerns, where the clients may not be at liberty to share private information necessary for producing good quality personalized models. Moreover, clients with high-quality data and resources are reluctant to participate in the FL process without reasonable incentive. In this paper, we propose PI-FL, a one-shot personalization solution complemented by a token-based incentive mechanism that rewards personalized training. PI-FL outperforms other state-of-the-art approaches and can generate good-quality personalized models while respecting clients' privacy.
A Distributed and Elastic Aggregation Service for Scalable Federated Learning Systems
Apr 16, 2022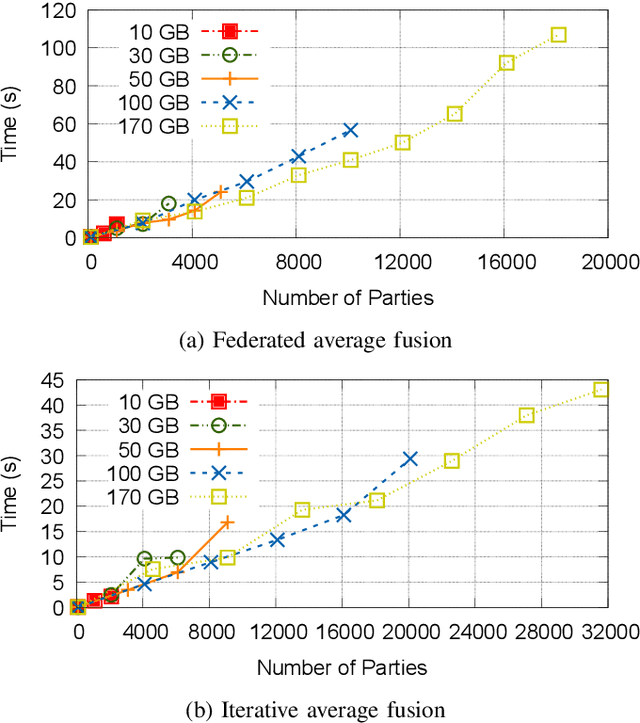
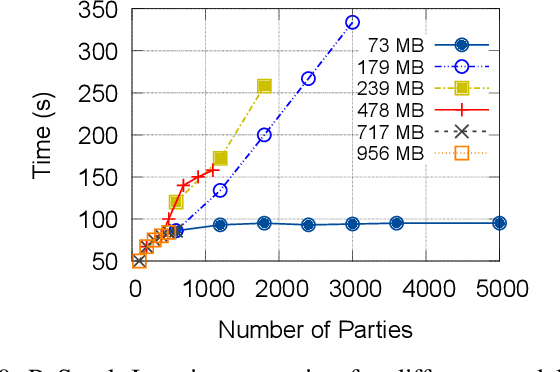
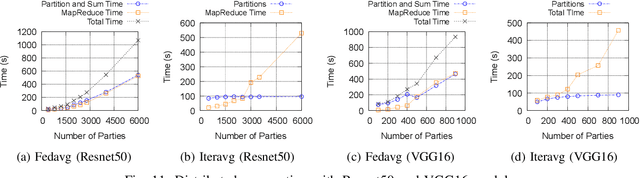
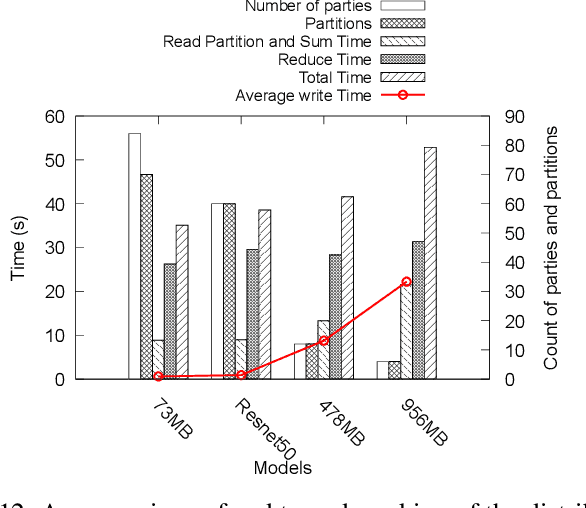
Federated Learning has promised a new approach to resolve the challenges in machine learning by bringing computation to the data. The popularity of the approach has led to rapid progress in the algorithmic aspects and the emergence of systems capable of simulating Federated Learning. State of art systems in Federated Learning support a single node aggregator that is insufficient to train a large corpus of devices or train larger-sized models. As the model size or the number of devices increase the single node aggregator incurs memory and computation burden while performing fusion tasks. It also faces communication bottlenecks when a large number of model updates are sent to a single node. We classify the workload for the aggregator into categories and propose a new aggregation service for handling each load. Our aggregation service is based on a holistic approach that chooses the best solution depending on the model update size and the number of clients. Our system provides a fault-tolerant, robust and efficient aggregation solution utilizing existing parallel and distributed frameworks. Through evaluation, we show the shortcomings of the state of art approaches and how a single solution is not suitable for all aggregation requirements. We also provide a comparison of current frameworks with our system through extensive experiments.