 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIVEE: Privacy-Preserving Vertical Federated Learning Against Feature Inference Attacks
Dec 14, 2025Vertical Federated Learning (VFL) enables collaborative model training across organizations that share common user samples but hold disjoint feature spaces. Despite its potential, VFL is susceptible to feature inference attacks, in which adversarial parties exploit shared confidence scores (i.e., prediction probabilities) during inference to reconstruct private input features of other participants. To counter this threat, we propose PRIVEE (PRIvacy-preserving Vertical fEderated lEarning), a novel defense mechanism named after the French word privée, meaning "private." PRIVEE obfuscates confidence scores while preserving critical properties such as relative ranking and inter-score distances. Rather than exposing raw scores, PRIVEE shares only the transformed representations, mitigating the risk of reconstruction attacks without degrading model prediction accuracy. Extensive experiments show that PRIVEE achieves a threefold improvement in privacy protection compared to state-of-the-art defenses, while preserving full predictive performance against advanced feature inference attacks.
OPUS-VFL: Incentivizing Optimal Privacy-Utility Tradeoffs in Vertical Federated Learning
Apr 22, 2025
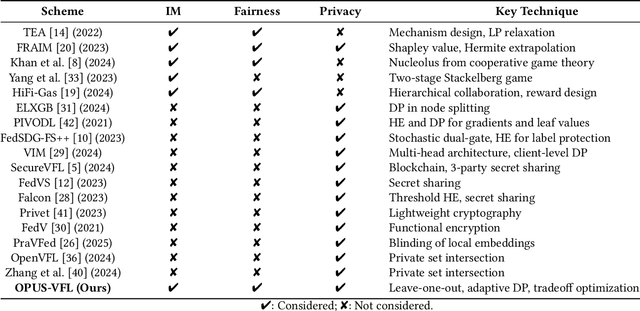
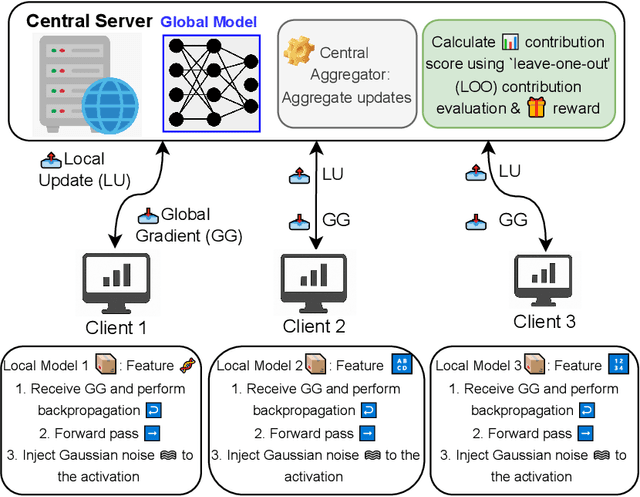

Vertical Federated Learning (VFL) enables organizations with disjoint feature spaces but shared user bases to collaboratively train models without sharing raw data. However, existing VFL systems face critical limitations: they often lack effective incentive mechanisms, struggle to balance privacy-utility tradeoffs, and fail to accommodate clients with heterogeneous resource capabilities. These challenges hinder meaningful participation, degrade model performance, and limit practical deployment. To address these issues, we propose OPUS-VFL, an Optimal Privacy-Utility tradeoff Strategy for VFL. OPUS-VFL introduces a novel, privacy-aware incentive mechanism that rewards clients based on a principled combination of model contribution, privacy preservation, and resource investment. It employs a lightweight leave-one-out (LOO) strategy to quantify feature importance per client, and integrates an adaptive differential privacy mechanism that enables clients to dynamically calibrate noise levels to optimize their individual utility. Our framework is designed to be scalable, budget-balanced, and robust to inference and poisoning attacks. Extensive experiments on benchmark datasets (MNIST, CIFAR-10, and CIFAR-100) demonstrate that OPUS-VFL significantly outperforms state-of-the-art VFL baselines in both efficiency and robustness. It reduces label inference attack success rates by up to 20%, increases feature inference reconstruction error (MSE) by over 30%, and achieves up to 25% higher incentives for clients that contribute meaningfully while respecting privacy and cost constraints. These results highlight the practicality and innovation of OPUS-VFL as a secure, fair, and performance-driven solution for real-world VFL.
LADs: Leveraging LLMs for AI-Driven DevOps
Feb 28, 2025
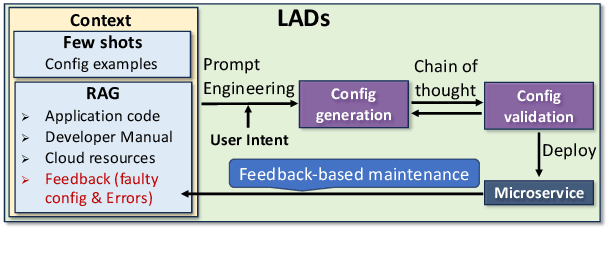

Automating cloud configuration and deployment remains a critical challenge due to evolving infrastructures, heterogeneous hardware, and fluctuating workloads. Existing solutions lack adaptability and require extensive manual tuning, leading to inefficiencies and misconfigurations. We introduce LADs, the first LLM-driven framework designed to tackle these challenges by ensuring robustness, adaptability, and efficiency in automated cloud management. Instead of merely applying existing techniques, LADs provides a principled approach to configuration optimization through in-depth analysis of what optimization works under which conditions. By leveraging Retrieval-Augmented Generation, Few-Shot Learning, Chain-of-Thought, and Feedback-Based Prompt Chaining, LADs generates accurate configurations and learns from deployment failures to iteratively refine system settings. Our findings reveal key insights into the trade-offs between performance, cost, and scalability, helping practitioners determine the right strategies for different deployment scenarios. For instance, we demonstrate how prompt chaining-based adaptive feedback loops enhance fault tolerance in multi-tenant environments and how structured log analysis with example shots improves configuration accuracy. Through extensive evaluations, LADs reduces manual effort, optimizes resource utilization, and improves system reliability. By open-sourcing LADs, we aim to drive further innovation in AI-powered DevOps automation.
Variational U-Net with Local Alignment for Joint Tumor Extraction and Registration (VALOR-Net) of Breast MRI Data Acquired at Two Different Field Strengths
Jan 23, 2025



Background: Multiparametric breast MRI data might improve tumor diagnostics, characterization, and treatment planning. Accurate alignment and delineation of images acquired at different field strengths such as 3T and 7T, remain challenging research tasks. Purpose: To address alignment challenges and enable consistent tumor segmentation across different MRI field strengths. Study type: Retrospective. Subjects: Nine female subjects with breast tumors were involved: six histologically proven invasive ductal carcinomas (IDC) and three fibroadenomas. Field strength/sequence: Imaging was performed at 3T and 7T scanners using post-contrast T1-weighted three-dimensional time-resolved angiography with stochastic trajectories (TWIST) sequence. Assessments: The method's performance for joint image registration and tumor segmentation was evaluated using several quantitative metrics, including signal-to-noise ratio (PSNR), structural similarity index (SSIM), normalized cross-correlation (NCC), Dice coefficient, F1 score, and relative sum of squared differences (rel SSD). Statistical tests: The Pearson correlation coefficient was used to test the relationship between the registration and segmentation metrics. Results: When calculated for each subject individually, the PSNR was in a range from 27.5 to 34.5 dB, and the SSIM was from 82.6 to 92.8%. The model achieved an NCC from 96.4 to 99.3% and a Dice coefficient of 62.9 to 95.3%. The F1 score was between 55.4 and 93.2% and the rel SSD was in the range of 2.0 and 7.5%. The segmentation metrics Dice and F1 Score are highly correlated (0.995), while a moderate correlation between NCC and SSIM (0.681) was found for registration. Data conclusion: Initial results demonstrate that the proposed method may be feasible in providing joint tumor segmentation and registration of MRI data acquired at different field strengths.
KatzBot: Revolutionizing Academic Chatbot for Enhanced Communication
Oct 21, 2024



Effective communication within universities is crucial for addressing the diverse information needs of students, alumni, and external stakeholders. However, existing chatbot systems often fail to deliver accurate, context-specific responses, resulting in poor user experiences. In this paper, we present KatzBot, an innovative chatbot powered by KatzGPT, a custom Large Language Model (LLM) fine-tuned on domain-specific academic data. KatzGPT is trained on two university-specific datasets: 6,280 sentence-completion pairs and 7,330 question-answer pairs. KatzBot outperforms established existing open source LLMs, achieving higher accuracy and domain relevance. KatzBot offers a user-friendly interface, significantly enhancing user satisfaction in real-world applications. The source code is publicly available at \url{https://github.com/AiAI-99/katzbot}.
Personalized Federated Learning Techniques: Empirical Analysis
Sep 10, 2024



Personalized Federated Learning (pFL) holds immense promise for tailoring machine learning models to individual users while preserving data privacy. However, achieving optimal performance in pFL often requires a careful balancing act between memory overhead costs and model accuracy. This paper delves into the trade-offs inherent in pFL, offering valuable insights for selecting the right algorithms for diverse real-world scenarios. We empirically evaluate ten prominent pFL techniques across various datasets and data splits, uncovering significant differences in their performance. Our study reveals interesting insights into how pFL methods that utilize personalized (local) aggregation exhibit the fastest convergence due to their efficiency in communication and computation. Conversely, fine-tuning methods face limitations in handling data heterogeneity and potential adversarial attacks while multi-objective learning methods achieve higher accuracy at the cost of additional training and resource consumption. Our study emphasizes the critical role of communication efficiency in scaling pFL, demonstrating how it can significantly affect resource usage in real-world deployments.
PI-FL: Personalized and Incentivized Federated Learning
Apr 27, 2023
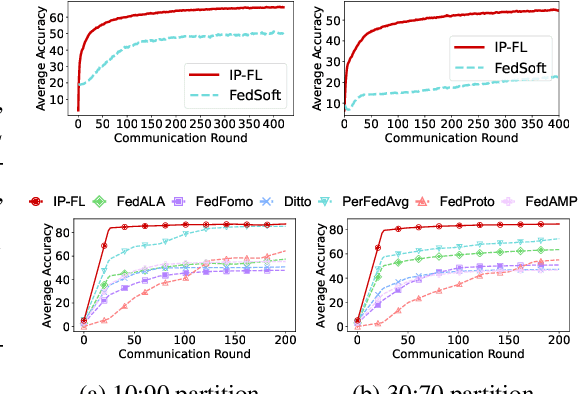

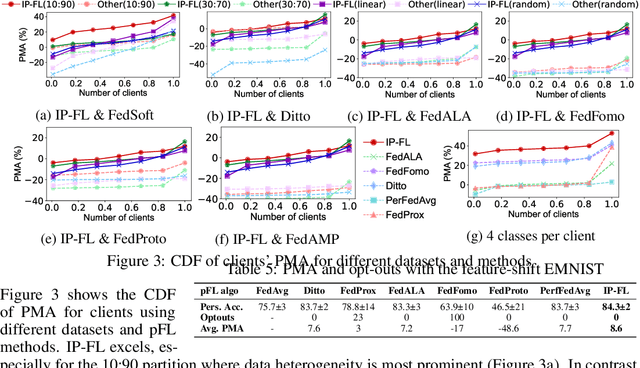
Personalized FL has been widely used to cater to heterogeneity challenges with non-IID data. A primary obstacle is considering the personalization process from the client's perspective to preserve their autonomy. Allowing the clients to participate in personalized FL decisions becomes significant due to privacy and security concerns, where the clients may not be at liberty to share private information necessary for producing good quality personalized models. Moreover, clients with high-quality data and resources are reluctant to participate in the FL process without reasonable incentive. In this paper, we propose PI-FL, a one-shot personalization solution complemented by a token-based incentive mechanism that rewards personalized training. PI-FL outperforms other state-of-the-art approaches and can generate good-quality personalized models while respecting clients' privacy.
A New Amharic Speech Emotion Dataset and Classification Benchmark
Jan 07, 2022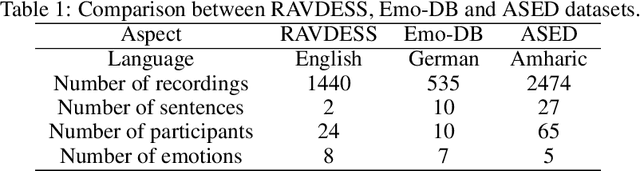
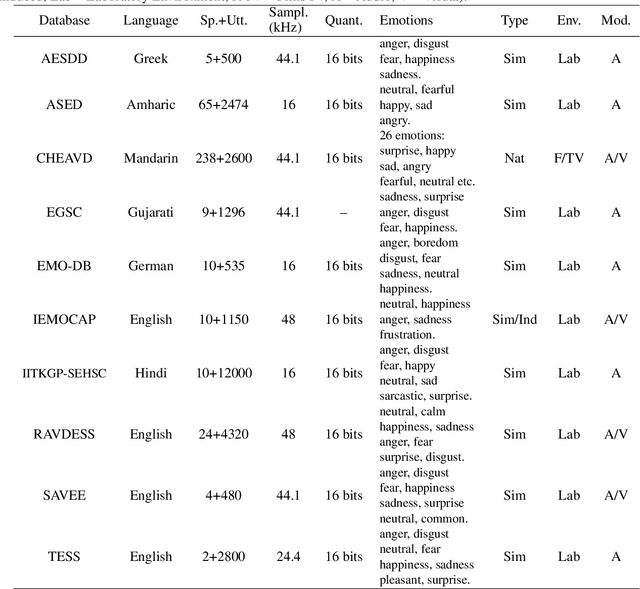


In this paper we present the Amharic Speech Emotion Dataset (ASED), which covers four dialects (Gojjam, Wollo, Shewa and Gonder) and five different emotions (neutral, fearful, happy, sad and angry). We believe it is the first Speech Emotion Recognition (SER) dataset for the Amharic language. 65 volunteer participants, all native speakers, recorded 2,474 sound samples, two to four seconds in length. Eight judges assigned emotions to the samples with high agreement level (Fleiss kappa = 0.8). The resulting dataset is freely available for download. Next, we developed a four-layer variant of the well-known VGG model which we call VGGb. Three experiments were then carried out using VGGb for SER, using ASED. First, we investigated whether Mel-spectrogram features or Mel-frequency Cepstral coefficient (MFCC) features work best for Amharic. This was done by training two VGGb SER models on ASED, one using Mel-spectrograms and the other using MFCC. Four forms of training were tried, standard cross-validation, and three variants based on sentences, dialects and speaker groups. Thus, a sentence used for training would not be used for testing, and the same for a dialect and speaker group. The conclusion was that MFCC features are superior under all four training schemes. MFCC was therefore adopted for Experiment 2, where VGGb and three other existing models were compared on ASED: RESNet50, Alex-Net and LSTM. VGGb was found to have very good accuracy (90.73%) as well as the fastest training time. In Experiment 3, the performance of VGGb was compared when trained on two existing SER datasets, RAVDESS (English) and EMO-DB (German) as well as on ASED (Amharic). Results are comparable across these languages, with ASED being the highest. This suggests that VGGb can be successfully applied to other languages. We hope that ASED will encourage researchers to experiment with other models for Amharic SER.
Two-Stream RNN/CNN for Action Recognition in 3D Videos
Oct 02, 2018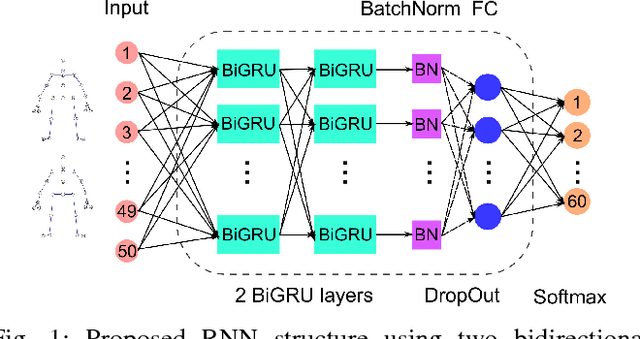


The recognition of actions from video sequences has many applications in health monitoring, assisted living, surveillance, and smart homes. Despite advances in sensing, in particular related to 3D video, the methodologies to process the data are still subject to research. We demonstrate superior results by a system which combines recurrent neural networks with convolutional neural networks in a voting approach. The gated-recurrent-unit-based neural networks are particularly well-suited to distinguish actions based on long-term information from optical tracking data; the 3D-CNNs focus more on detailed, recent information from video data. The resulting features are merged in an SVM which then classifies the movement. In this architecture, our method improves recognition rates of state-of-the-art methods by 14% on standard data sets.
Convolutional Networks for Object Category and 3D Pose Estimation from 2D Images
Jul 20, 2018
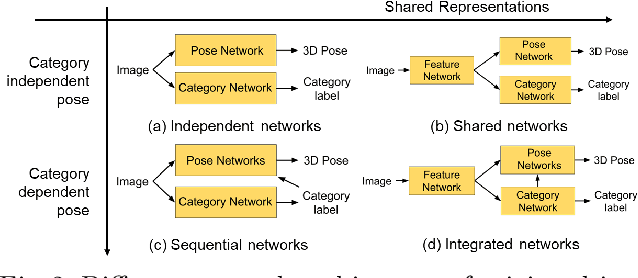
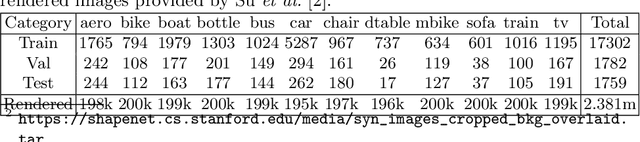
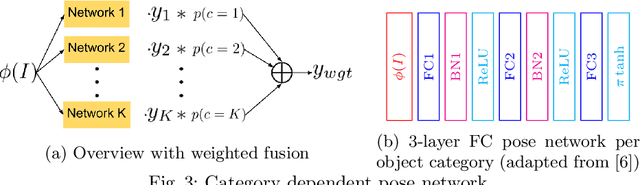
Current CNN-based algorithms for recovering the 3D pose of an object in an image assume knowledge about both the object category and its 2D localization in the image. In this paper, we relax one of these constraints and propose to solve the task of joint object category and 3D pose estimation from an image assuming known 2D localization. We design a new architecture for this task composed of a feature network that is shared between subtasks, an object categorization network built on top of the feature network, and a collection of category dependent pose regression networks. We also introduce suitable loss functions and a training method for the new architecture. Experiments on the challenging PASCAL3D+ dataset show state-of-the-art performance in the joint categorization and pose estimation task. Moreover, our performance on the joint task is comparable to the performance of state-of-the-art methods on the simpler 3D pose estimation with known object category task.