 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIVEE: Privacy-Preserving Vertical Federated Learning Against Feature Inference Attacks
Dec 14, 2025Vertical Federated Learning (VFL) enables collaborative model training across organizations that share common user samples but hold disjoint feature spaces. Despite its potential, VFL is susceptible to feature inference attacks, in which adversarial parties exploit shared confidence scores (i.e., prediction probabilities) during inference to reconstruct private input features of other participants. To counter this threat, we propose PRIVEE (PRIvacy-preserving Vertical fEderated lEarning), a novel defense mechanism named after the French word privée, meaning "private." PRIVEE obfuscates confidence scores while preserving critical properties such as relative ranking and inter-score distances. Rather than exposing raw scores, PRIVEE shares only the transformed representations, mitigating the risk of reconstruction attacks without degrading model prediction accuracy. Extensive experiments show that PRIVEE achieves a threefold improvement in privacy protection compared to state-of-the-art defenses, while preserving full predictive performance against advanced feature inference attacks.
Sem-DPO: Mitigating Semantic Inconsistency in Preference Optimization for Prompt Engineering
Jul 27, 2025Generative AI can now synthesize strikingly realistic images from text, yet output quality remains highly sensitive to how prompts are phrased. Direct Preference Optimization (DPO) offers a lightweight, off-policy alternative to RL for automatic prompt engineering, but its token-level regularization leaves semantic inconsistency unchecked as prompts that win higher preference scores can still drift away from the user's intended meaning. We introduce Sem-DPO, a variant of DPO that preserves semantic consistency yet retains its simplicity and efficiency. Sem-DPO scales the DPO loss by an exponential weight proportional to the cosine distance between the original prompt and winning candidate in embedding space, softly down-weighting training signals that would otherwise reward semantically mismatched prompts. We provide the first analytical bound on semantic drift for preference-tuned prompt generators, showing that Sem-DPO keeps learned prompts within a provably bounded neighborhood of the original text. On three standard text-to-image prompt-optimization benchmarks and two language models, Sem-DPO achieves 8-12% higher CLIP similarity and 5-9% higher human-preference scores (HPSv2.1, PickScore) than DPO, while also outperforming state-of-the-art baselines. These findings suggest that strong flat baselines augmented with semantic weighting should become the new standard for prompt-optimization studies and lay the groundwork for broader, semantics-aware preference optimization in language models.
OPUS-VFL: Incentivizing Optimal Privacy-Utility Tradeoffs in Vertical Federated Learning
Apr 22, 2025
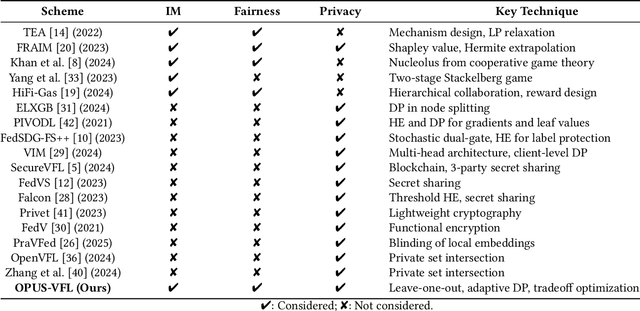
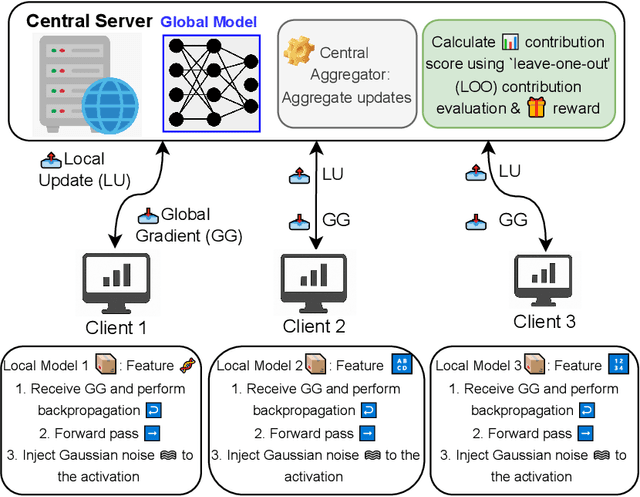

Vertical Federated Learning (VFL) enables organizations with disjoint feature spaces but shared user bases to collaboratively train models without sharing raw data. However, existing VFL systems face critical limitations: they often lack effective incentive mechanisms, struggle to balance privacy-utility tradeoffs, and fail to accommodate clients with heterogeneous resource capabilities. These challenges hinder meaningful participation, degrade model performance, and limit practical deployment. To address these issues, we propose OPUS-VFL, an Optimal Privacy-Utility tradeoff Strategy for VFL. OPUS-VFL introduces a novel, privacy-aware incentive mechanism that rewards clients based on a principled combination of model contribution, privacy preservation, and resource investment. It employs a lightweight leave-one-out (LOO) strategy to quantify feature importance per client, and integrates an adaptive differential privacy mechanism that enables clients to dynamically calibrate noise levels to optimize their individual utility. Our framework is designed to be scalable, budget-balanced, and robust to inference and poisoning attacks. Extensive experiments on benchmark datasets (MNIST, CIFAR-10, and CIFAR-100) demonstrate that OPUS-VFL significantly outperforms state-of-the-art VFL baselines in both efficiency and robustness. It reduces label inference attack success rates by up to 20%, increases feature inference reconstruction error (MSE) by over 30%, and achieves up to 25% higher incentives for clients that contribute meaningfully while respecting privacy and cost constraints. These results highlight the practicality and innovation of OPUS-VFL as a secure, fair, and performance-driven solution for real-world VFL.
How Accurately Do Large Language Models Understand Code?
Apr 09, 2025
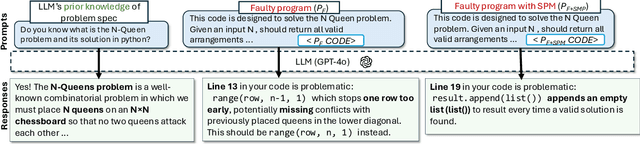


Large Language Models (LLMs) are increasingly used in post-development tasks such as code repair and testing. A key factor in these tasks' success is the model's deep understanding of code. However, the extent to which LLMs truly understand code remains largely unevaluated. Quantifying code comprehension is challenging due to its abstract nature and the lack of a standardized metric. Previously, this was assessed through developer surveys, which are not feasible for evaluating LLMs. Existing LLM benchmarks focus primarily on code generation, fundamentally different from code comprehension. Additionally, fixed benchmarks quickly become obsolete as they become part of the training data. This paper presents the first large-scale empirical investigation into LLMs' ability to understand code. Inspired by mutation testing, we use an LLM's fault-finding ability as a proxy for its deep code understanding. This approach is based on the insight that a model capable of identifying subtle functional discrepancies must understand the code well. We inject faults in real-world programs and ask the LLM to localize them, ensuring the specifications suffice for fault localization. Next, we apply semantic-preserving code mutations (SPMs) to the faulty programs and test whether the LLMs still locate the faults, verifying their confidence in code understanding. We evaluate nine popular LLMs on 600,010 debugging tasks from 670 Java and 637 Python programs. We find that LLMs lose the ability to debug the same bug in 78% of faulty programs when SPMs are applied, indicating a shallow understanding of code and reliance on features irrelevant to semantics. We also find that LLMs understand code earlier in the program better than later. This suggests that LLMs' code comprehension remains tied to lexical and syntactic features due to tokenization designed for natural languages, which overlooks code semantics.
LADs: Leveraging LLMs for AI-Driven DevOps
Feb 28, 2025
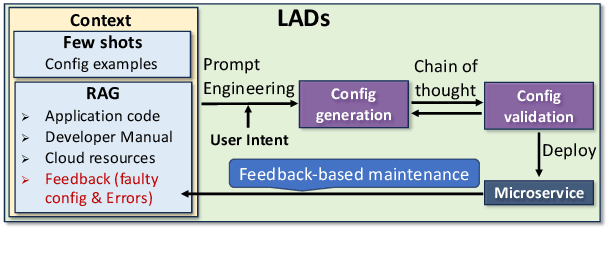

Automating cloud configuration and deployment remains a critical challenge due to evolving infrastructures, heterogeneous hardware, and fluctuating workloads. Existing solutions lack adaptability and require extensive manual tuning, leading to inefficiencies and misconfigurations. We introduce LADs, the first LLM-driven framework designed to tackle these challenges by ensuring robustness, adaptability, and efficiency in automated cloud management. Instead of merely applying existing techniques, LADs provides a principled approach to configuration optimization through in-depth analysis of what optimization works under which conditions. By leveraging Retrieval-Augmented Generation, Few-Shot Learning, Chain-of-Thought, and Feedback-Based Prompt Chaining, LADs generates accurate configurations and learns from deployment failures to iteratively refine system settings. Our findings reveal key insights into the trade-offs between performance, cost, and scalability, helping practitioners determine the right strategies for different deployment scenarios. For instance, we demonstrate how prompt chaining-based adaptive feedback loops enhance fault tolerance in multi-tenant environments and how structured log analysis with example shots improves configuration accuracy. Through extensive evaluations, LADs reduces manual effort, optimizes resource utilization, and improves system reliability. By open-sourcing LADs, we aim to drive further innovation in AI-powered DevOps automation.
Personalized Federated Learning Techniques: Empirical Analysis
Sep 10, 2024



Personalized Federated Learning (pFL) holds immense promise for tailoring machine learning models to individual users while preserving data privacy. However, achieving optimal performance in pFL often requires a careful balancing act between memory overhead costs and model accuracy. This paper delves into the trade-offs inherent in pFL, offering valuable insights for selecting the right algorithms for diverse real-world scenarios. We empirically evaluate ten prominent pFL techniques across various datasets and data splits, uncovering significant differences in their performance. Our study reveals interesting insights into how pFL methods that utilize personalized (local) aggregation exhibit the fastest convergence due to their efficiency in communication and computation. Conversely, fine-tuning methods face limitations in handling data heterogeneity and potential adversarial attacks while multi-objective learning methods achieve higher accuracy at the cost of additional training and resource consumption. Our study emphasizes the critical role of communication efficiency in scaling pFL, demonstrating how it can significantly affect resource usage in real-world deployments.
A Framework for Incentivized Collaborative Learning
May 26, 2023Collaborations among various entities, such as companies, research labs, AI agents, and edge devices, have become increasingly crucial for achieving machine learning tasks that cannot be accomplished by a single entity alone. This is likely due to factors such as security constraints, privacy concerns, and limitations in computation resources. As a result, collaborative learning (CL) research has been gaining momentum. However, a significant challenge in practical applications of CL is how to effectively incentivize multiple entities to collaborate before any collaboration occurs. In this study, we propose ICL, a general framework for incentivized collaborative learning, and provide insights into the critical issue of when and why incentives can improve collaboration performance. Furthermore, we show the broad applicability of ICL to specific cases in federated learning, assisted learning, and multi-armed bandit with both theory and experimental results.
PI-FL: Personalized and Incentivized Federated Learning
Apr 27, 2023
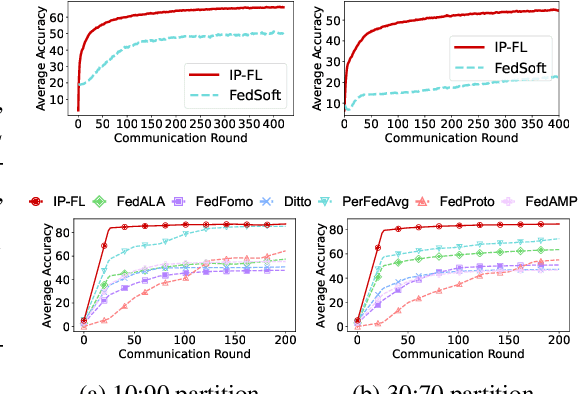

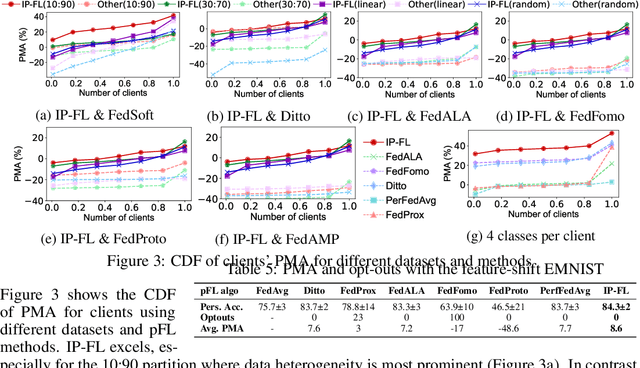
Personalized FL has been widely used to cater to heterogeneity challenges with non-IID data. A primary obstacle is considering the personalization process from the client's perspective to preserve their autonomy. Allowing the clients to participate in personalized FL decisions becomes significant due to privacy and security concerns, where the clients may not be at liberty to share private information necessary for producing good quality personalized models. Moreover, clients with high-quality data and resources are reluctant to participate in the FL process without reasonable incentive. In this paper, we propose PI-FL, a one-shot personalization solution complemented by a token-based incentive mechanism that rewards personalized training. PI-FL outperforms other state-of-the-art approaches and can generate good-quality personalized models while respecting clients' privacy.