 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Sem-DPO: Mitigating Semantic Inconsistency in Preference Optimization for Prompt Engineering
Jul 27, 2025Generative AI can now synthesize strikingly realistic images from text, yet output quality remains highly sensitive to how prompts are phrased. Direct Preference Optimization (DPO) offers a lightweight, off-policy alternative to RL for automatic prompt engineering, but its token-level regularization leaves semantic inconsistency unchecked as prompts that win higher preference scores can still drift away from the user's intended meaning. We introduce Sem-DPO, a variant of DPO that preserves semantic consistency yet retains its simplicity and efficiency. Sem-DPO scales the DPO loss by an exponential weight proportional to the cosine distance between the original prompt and winning candidate in embedding space, softly down-weighting training signals that would otherwise reward semantically mismatched prompts. We provide the first analytical bound on semantic drift for preference-tuned prompt generators, showing that Sem-DPO keeps learned prompts within a provably bounded neighborhood of the original text. On three standard text-to-image prompt-optimization benchmarks and two language models, Sem-DPO achieves 8-12% higher CLIP similarity and 5-9% higher human-preference scores (HPSv2.1, PickScore) than DPO, while also outperforming state-of-the-art baselines. These findings suggest that strong flat baselines augmented with semantic weighting should become the new standard for prompt-optimization studies and lay the groundwork for broader, semantics-aware preference optimization in language models.
Harnessing Caption Detailness for Data-Efficient Text-to-Image Generation
May 21, 2025Training text-to-image (T2I) models with detailed captions can significantly improve their generation quality. Existing methods often rely on simplistic metrics like caption length to represent the detailness of the caption in the T2I training set. In this paper, we propose a new metric to estimate caption detailness based on two aspects: image coverage rate (ICR), which evaluates whether the caption covers all regions/objects in the image, and average object detailness (AOD), which quantifies the detailness of each object's description. Through experiments on the COCO dataset using ShareGPT4V captions, we demonstrate that T2I models trained on high-ICR and -AOD captions achieve superior performance on DPG and other benchmarks. Notably, our metric enables more effective data selection-training on only 20% of full data surpasses both full-dataset training and length-based selection method, improving alignment and reconstruction ability. These findings highlight the critical role of detail-aware metrics over length-based heuristics in caption selection for T2I tasks.
CineTechBench: A Benchmark for Cinematographic Technique Understanding and Generation
May 21, 2025



Cinematography is a cornerstone of film production and appreciation, shaping mood, emotion, and narrative through visual elements such as camera movement, shot composition, and lighting. Despite recent progress in multimodal large language models (MLLMs) and video generation models, the capacity of current models to grasp and reproduce cinematographic techniques remains largely uncharted, hindered by the scarcity of expert-annotated data. To bridge this gap, we present CineTechBench, a pioneering benchmark founded on precise, manual annotation by seasoned cinematography experts across key cinematography dimensions. Our benchmark covers seven essential aspects-shot scale, shot angle, composition, camera movement, lighting, color, and focal length-and includes over 600 annotated movie images and 120 movie clips with clear cinematographic techniques. For the understanding task, we design question answer pairs and annotated descriptions to assess MLLMs' ability to interpret and explain cinematographic techniques. For the generation task, we assess advanced video generation models on their capacity to reconstruct cinema-quality camera movements given conditions such as textual prompts or keyframes. We conduct a large-scale evaluation on 15+ MLLMs and 5+ video generation models. Our results offer insights into the limitations of current models and future directions for cinematography understanding and generation in automatically film production and appreciation. The code and benchmark can be accessed at https://github.com/PRIS-CV/CineTechBench.
Probe Pruning: Accelerating LLMs through Dynamic Pruning via Model-Probing
Feb 21, 2025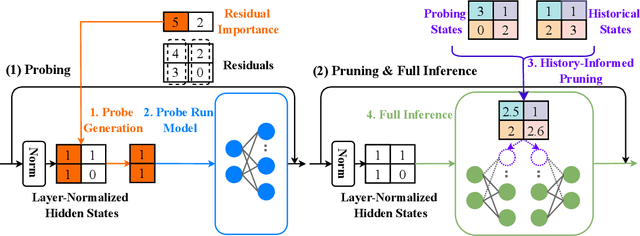


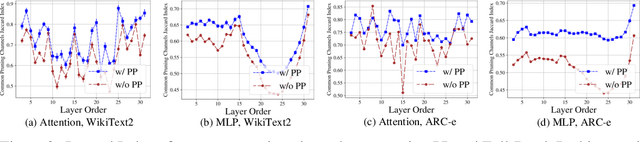
We introduce Probe Pruning (PP), a novel framework for online, dynamic, structured pruning of Large Language Models (LLMs) applied in a batch-wise manner. PP leverages the insight that not all samples and tokens contribute equally to the model's output, and probing a small portion of each batch effectively identifies crucial weights, enabling tailored dynamic pruning for different batches. It comprises three main stages: probing, history-informed pruning, and full inference. In the probing stage, PP selects a small yet crucial set of hidden states, based on residual importance, to run a few model layers ahead. During the history-informed pruning stage, PP strategically integrates the probing states with historical states. Subsequently, it structurally prunes weights based on the integrated states and the PP importance score, a metric developed specifically to assess the importance of each weight channel in maintaining performance. In the final stage, full inference is conducted on the remaining weights. A major advantage of PP is its compatibility with existing models, as it operates without requiring additional neural network modules or fine-tuning. Comprehensive evaluations of PP on LLaMA-2/3 and OPT models reveal that even minimal probing-using just 1.5% of FLOPs-can substantially enhance the efficiency of structured pruning of LLMs. For instance, when evaluated on LLaMA-2-7B with WikiText2, PP achieves a 2.56 times lower ratio of performance degradation per unit of runtime reduction compared to the state-of-the-art method at a 40% pruning ratio. Our code is available at https://github.com/Qi-Le1/Probe_Pruning.
Malleable Robots
Feb 06, 2025This chapter is about the fundamentals of fabrication, control, and human-robot interaction of a new type of collaborative robotic manipulators, called malleable robots, which are based on adjustable architectures of varying stiffness for achieving high dexterity with lower mobility arms. Collaborative robots, or cobots, commonly integrate six or more degrees of freedom (DOF) in a serial arm in order to allow positioning in constrained spaces and adaptability across tasks. Increasing the dexterity of robotic arms has been indeed traditionally accomplished by increasing the number of degrees of freedom of the system; however, once a robotic task has been established (e.g., a pick-and-place operation), the motion of the end-effector can be normally achieved using less than 6-DOF (i.e., lower mobility). The aim of malleable robots is to close the technological gap that separates current cobots from achieving flexible, accessible manufacturing automation with a reduced number of actuators.
* 37 pages, 22 figures, chapter 7 of "Handbook on Soft Robotics"
SegKAN: High-Resolution Medical Image Segmentation with Long-Distance Dependencies
Dec 28, 2024Hepatic vessels in computed tomography scans often suffer from image fragmentation and noise interference, making it difficult to maintain vessel integrity and posing significant challenges for vessel segmentation. To address this issue, we propose an innovative model: SegKAN. First, we improve the conventional embedding module by adopting a novel convolutional network structure for image embedding, which smooths out image noise and prevents issues such as gradient explosion in subsequent stages. Next, we transform the spatial relationships between Patch blocks into temporal relationships to solve the problem of capturing positional relationships between Patch blocks in traditional Vision Transformer models. We conducted experiments on a Hepatic vessel dataset, and compared to the existing state-of-the-art model, the Dice score improved by 1.78%. These results demonstrate that the proposed new structure effectively enhances the segmentation performance of high-resolution extended objects. Code will be available at https://github.com/goblin327/SegKAN
From Simple to Professional: A Combinatorial Controllable Image Captioning Agent
Dec 15, 2024



The Controllable Image Captioning Agent (CapAgent) is an innovative system designed to bridge the gap between user simplicity and professional-level outputs in image captioning tasks. CapAgent automatically transforms user-provided simple instructions into detailed, professional instructions, enabling precise and context-aware caption generation. By leveraging multimodal large language models (MLLMs) and external tools such as object detection tool and search engines, the system ensures that captions adhere to specified guidelines, including sentiment, keywords, focus, and formatting. CapAgent transparently controls each step of the captioning process, and showcases its reasoning and tool usage at every step, fostering user trust and engagement. The project code is available at https://github.com/xin-ran-w/CapAgent.
Detailed Object Description with Controllable Dimensions
Nov 28, 2024



Object description plays an important role for visually impaired individuals to understand and compare the differences between objects. Recent multimodal large language models (MLLMs) exhibit powerful perceptual abilities and demonstrate impressive potential for generating object-centric captions. However, the descriptions generated by such models may still usually contain a lot of content that is not relevant to the user intent. Under special scenarios, users may only need the details of certain dimensions of an object. In this paper, we propose a training-free captioning refinement pipeline, \textbf{Dimension Tailor}, designed to enhance user-specified details in object descriptions. This pipeline includes three steps: dimension extracting, erasing, and supplementing, which decompose the description into pre-defined dimensions and correspond to user intent. Therefore, it can not only improve the quality of object details but also offer flexibility in including or excluding specific dimensions based on user preferences. We conducted extensive experiments to demonstrate the effectiveness of Dimension Tailor on controllable object descriptions. Notably, the proposed pipeline can consistently improve the performance of the recent MLLMs. The code is currently accessible at the following anonymous link: \url{https://github.com/xin-ran-w/ControllableObjectDescription}.