 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbe Pruning: Accelerating LLMs through Dynamic Pruning via Model-Probing
Feb 21, 2025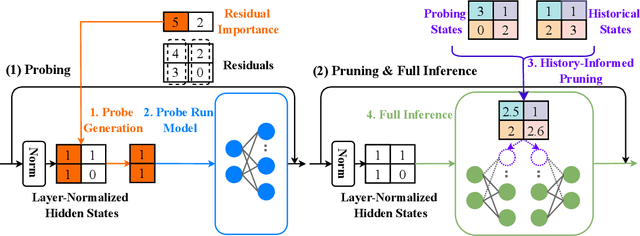


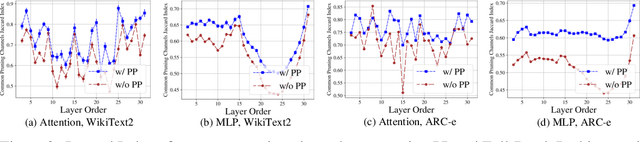
We introduce Probe Pruning (PP), a novel framework for online, dynamic, structured pruning of Large Language Models (LLMs) applied in a batch-wise manner. PP leverages the insight that not all samples and tokens contribute equally to the model's output, and probing a small portion of each batch effectively identifies crucial weights, enabling tailored dynamic pruning for different batches. It comprises three main stages: probing, history-informed pruning, and full inference. In the probing stage, PP selects a small yet crucial set of hidden states, based on residual importance, to run a few model layers ahead. During the history-informed pruning stage, PP strategically integrates the probing states with historical states. Subsequently, it structurally prunes weights based on the integrated states and the PP importance score, a metric developed specifically to assess the importance of each weight channel in maintaining performance. In the final stage, full inference is conducted on the remaining weights. A major advantage of PP is its compatibility with existing models, as it operates without requiring additional neural network modules or fine-tuning. Comprehensive evaluations of PP on LLaMA-2/3 and OPT models reveal that even minimal probing-using just 1.5% of FLOPs-can substantially enhance the efficiency of structured pruning of LLMs. For instance, when evaluated on LLaMA-2-7B with WikiText2, PP achieves a 2.56 times lower ratio of performance degradation per unit of runtime reduction compared to the state-of-the-art method at a 40% pruning ratio. Our code is available at https://github.com/Qi-Le1/Probe_Pruning.
MAP: Multi-Human-Value Alignment Palette
Oct 24, 2024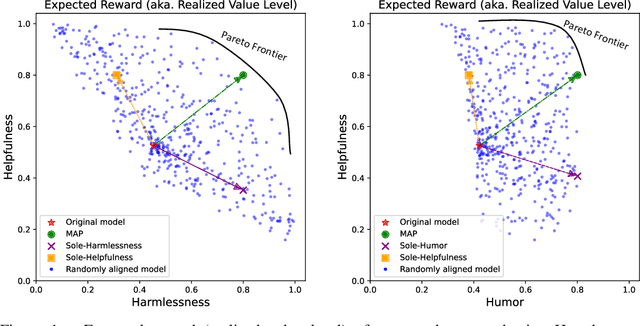
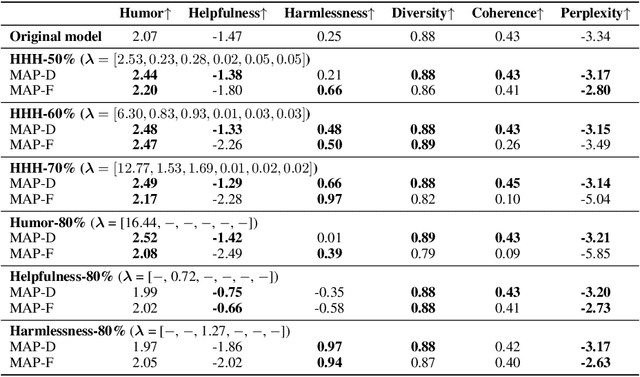
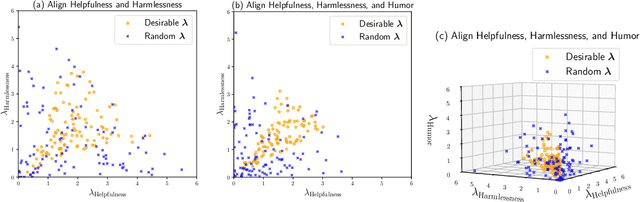
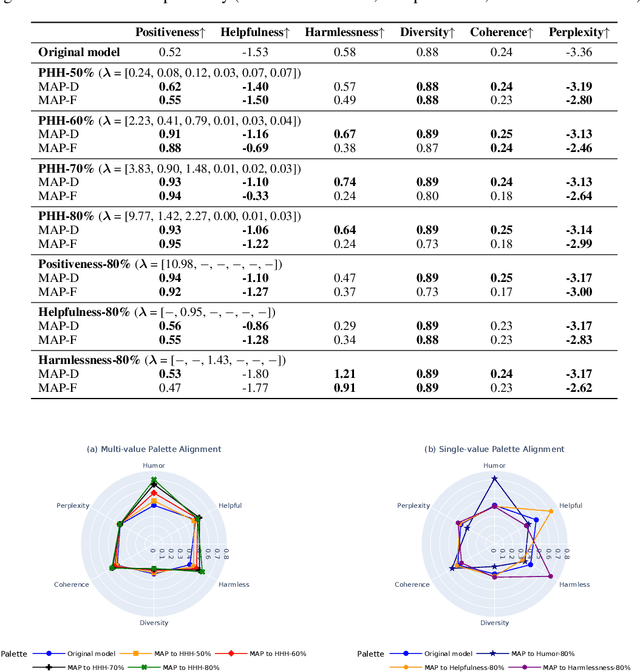
Ensuring that generative AI systems align with human values is essential but challenging, especially when considering multiple human values and their potential trade-offs. Since human values can be personalized and dynamically change over time, the desirable levels of value alignment vary across different ethnic groups, industry sectors, and user cohorts. Within existing frameworks, it is hard to define human values and align AI systems accordingly across different directions simultaneously, such as harmlessness, helpfulness, and positiveness. To address this, we develop a novel, first-principle approach called Multi-Human-Value Alignment Palette (MAP), which navigates the alignment across multiple human values in a structured and reliable way. MAP formulates the alignment problem as an optimization task with user-defined constraints, which define human value targets. It can be efficiently solved via a primal-dual approach, which determines whether a user-defined alignment target is achievable and how to achieve it. We conduct a detailed theoretical analysis of MAP by quantifying the trade-offs between values, the sensitivity to constraints, the fundamental connection between multi-value alignment and sequential alignment, and proving that linear weighted rewards are sufficient for multi-value alignment. Extensive experiments demonstrate MAP's ability to align multiple values in a principled manner while delivering strong empirical performance across various tasks.
DynamicFL: Federated Learning with Dynamic Communication Resource Allocation
Sep 08, 2024



Federated Learning (FL) is a collaborative machine learning framework that allows multiple users to train models utilizing their local data in a distributed manner. However, considerable statistical heterogeneity in local data across devices often leads to suboptimal model performance compared with independently and identically distributed (IID) data scenarios. In this paper, we introduce DynamicFL, a new FL framework that investigates the trade-offs between global model performance and communication costs for two widely adopted FL methods: Federated Stochastic Gradient Descent (FedSGD) and Federated Averaging (FedAvg). Our approach allocates diverse communication resources to clients based on their data statistical heterogeneity, considering communication resource constraints, and attains substantial performance enhancements compared to uniform communication resource allocation. Notably, our method bridges the gap between FedSGD and FedAvg, providing a flexible framework leveraging communication heterogeneity to address statistical heterogeneity in FL. Through extensive experiments, we demonstrate that DynamicFL surpasses current state-of-the-art methods with up to a 10% increase in model accuracy, demonstrating its adaptability and effectiveness in tackling data statistical heterogeneity challenges.
ColA: Collaborative Adaptation with Gradient Learning
Apr 22, 2024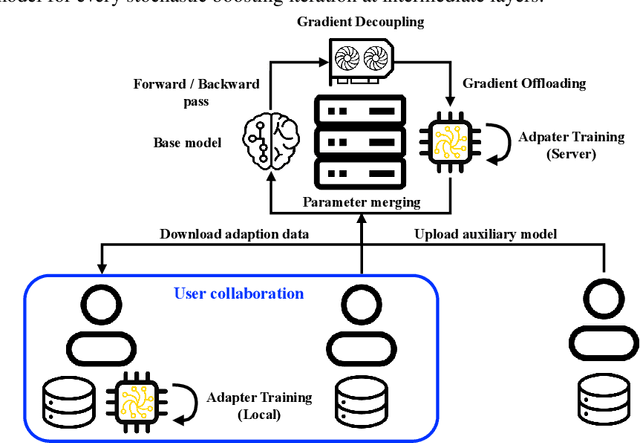
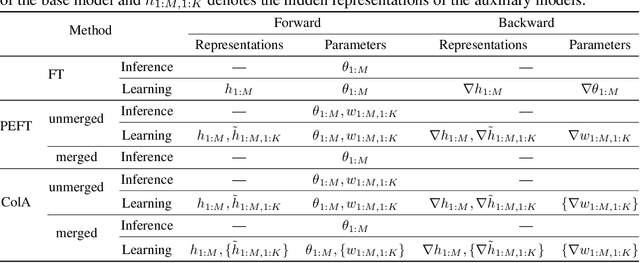
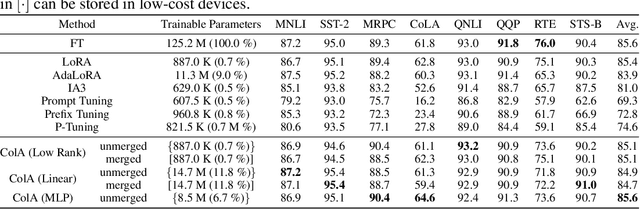
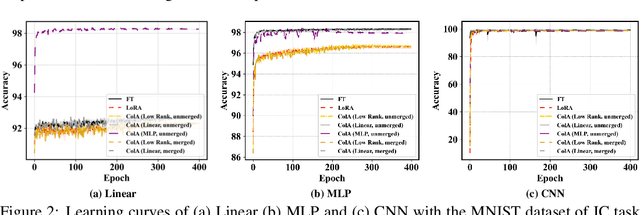
A primary function of back-propagation is to compute both the gradient of hidden representations and parameters for optimization with gradient descent. Training large models requires high computational costs due to their vast parameter sizes. While Parameter-Efficient Fine-Tuning (PEFT) methods aim to train smaller auxiliary models to save computational space, they still present computational overheads, especially in Fine-Tuning as a Service (FTaaS) for numerous users. We introduce Collaborative Adaptation (ColA) with Gradient Learning (GL), a parameter-free, model-agnostic fine-tuning approach that decouples the computation of the gradient of hidden representations and parameters. In comparison to PEFT methods, ColA facilitates more cost-effective FTaaS by offloading the computation of the gradient to low-cost devices. We also provide a theoretical analysis of ColA and experimentally demonstrate that ColA can perform on par or better than existing PEFT methods on various benchmarks.
A Framework for Incentivized Collaborative Learning
May 26, 2023Collaborations among various entities, such as companies, research labs, AI agents, and edge devices, have become increasingly crucial for achieving machine learning tasks that cannot be accomplished by a single entity alone. This is likely due to factors such as security constraints, privacy concerns, and limitations in computation resources. As a result, collaborative learning (CL) research has been gaining momentum. However, a significant challenge in practical applications of CL is how to effectively incentivize multiple entities to collaborate before any collaboration occurs. In this study, we propose ICL, a general framework for incentivized collaborative learning, and provide insights into the critical issue of when and why incentives can improve collaboration performance. Furthermore, we show the broad applicability of ICL to specific cases in federated learning, assisted learning, and multi-armed bandit with both theory and experimental results.
PI-FL: Personalized and Incentivized Federated Learning
Apr 27, 2023
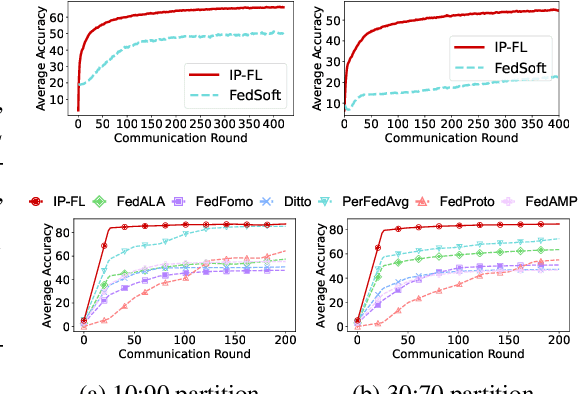

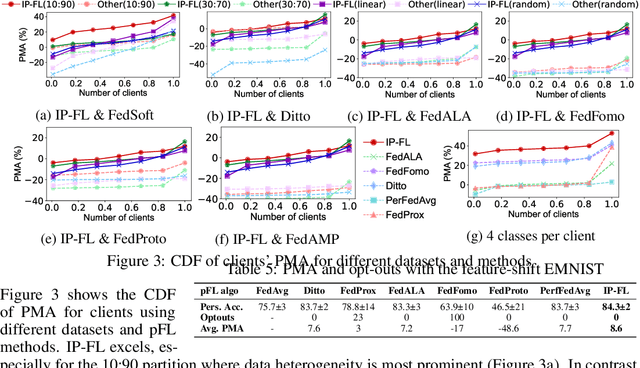
Personalized FL has been widely used to cater to heterogeneity challenges with non-IID data. A primary obstacle is considering the personalization process from the client's perspective to preserve their autonomy. Allowing the clients to participate in personalized FL decisions becomes significant due to privacy and security concerns, where the clients may not be at liberty to share private information necessary for producing good quality personalized models. Moreover, clients with high-quality data and resources are reluctant to participate in the FL process without reasonable incentive. In this paper, we propose PI-FL, a one-shot personalization solution complemented by a token-based incentive mechanism that rewards personalized training. PI-FL outperforms other state-of-the-art approaches and can generate good-quality personalized models while respecting clients' privacy.
Personalized Federated Recommender Systems with Private and Partially Federated AutoEncoders
Dec 17, 2022



Recommender Systems (RSs) have become increasingly important in many application domains, such as digital marketing. Conventional RSs often need to collect users' data, centralize them on the server-side, and form a global model to generate reliable recommendations. However, they suffer from two critical limitations: the personalization problem that the RSs trained traditionally may not be customized for individual users, and the privacy problem that directly sharing user data is not encouraged. We propose Personalized Federated Recommender Systems (PersonalFR), which introduces a personalized autoencoder-based recommendation model with Federated Learning (FL) to address these challenges. PersonalFR guarantees that each user can learn a personal model from the local dataset and other participating users' data without sharing local data, data embeddings, or models. PersonalFR consists of three main components, including AutoEncoder-based RSs (ARSs) that learn the user-item interactions, Partially Federated Learning (PFL) that updates the encoder locally and aggregates the decoder on the server-side, and Partial Compression (PC) that only computes and transmits active model parameters. Extensive experiments on two real-world datasets demonstrate that PersonalFR can achieve private and personalized performance comparable to that trained by centralizing all users' data. Moreover, PersonalFR requires significantly less computation and communication overhead than standard FL baselines.