 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Score-Based Quickest Change Detection
Jul 15, 2024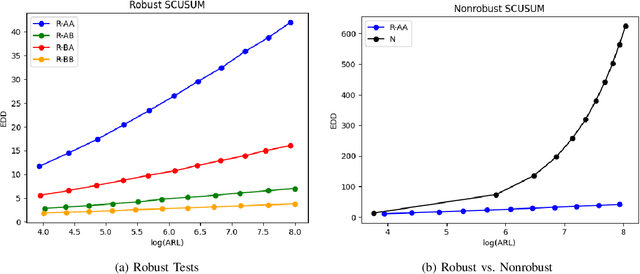
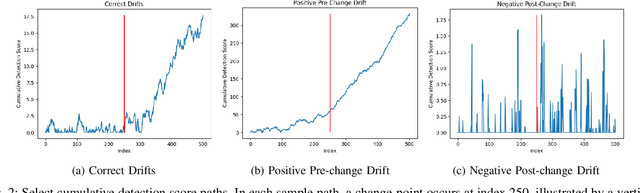
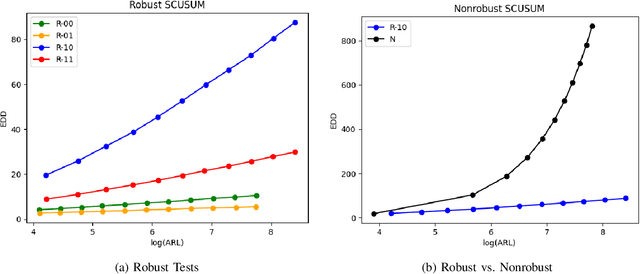
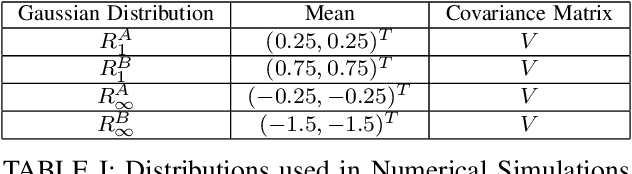
Methods in the field of quickest change detection rapidly detect in real-time a change in the data-generating distribution of an online data stream. Existing methods have been able to detect this change point when the densities of the pre- and post-change distributions are known. Recent work has extended these results to the case where the pre- and post-change distributions are known only by their score functions. This work considers the case where the pre- and post-change score functions are known only to correspond to distributions in two disjoint sets. This work employs a pair of "least-favorable" distributions to robustify the existing score-based quickest change detection algorithm, the properties of which are studied. This paper calculates the least-favorable distributions for specific model classes and provides methods of estimating the least-favorable distributions for common constructions. Simulation results are provided demonstrating the performance of our robust change detection algorithm.
ColA: Collaborative Adaptation with Gradient Learning
Apr 22, 2024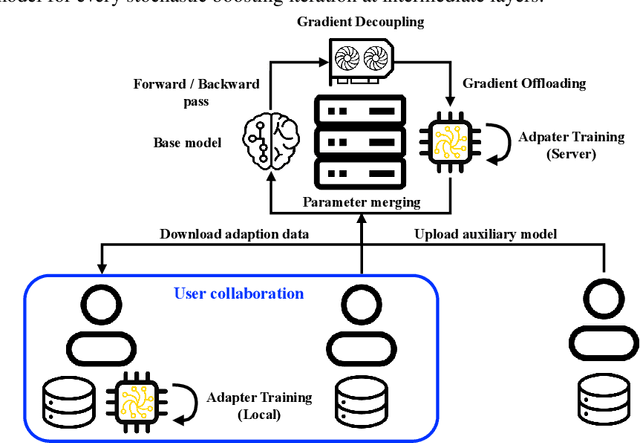
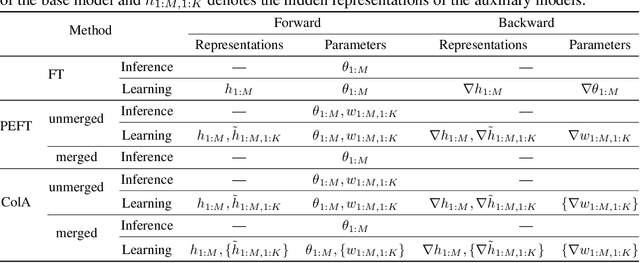
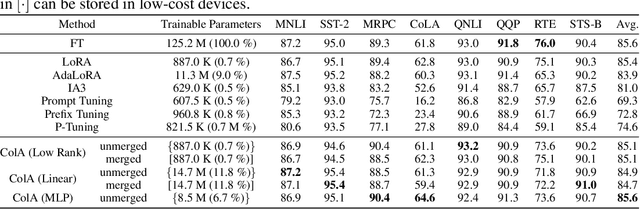
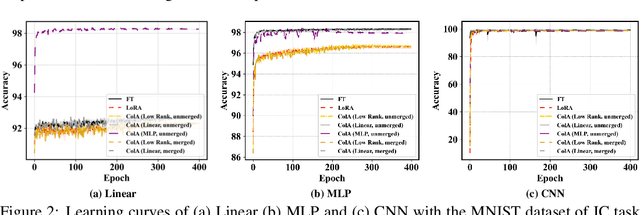
A primary function of back-propagation is to compute both the gradient of hidden representations and parameters for optimization with gradient descent. Training large models requires high computational costs due to their vast parameter sizes. While Parameter-Efficient Fine-Tuning (PEFT) methods aim to train smaller auxiliary models to save computational space, they still present computational overheads, especially in Fine-Tuning as a Service (FTaaS) for numerous users. We introduce Collaborative Adaptation (ColA) with Gradient Learning (GL), a parameter-free, model-agnostic fine-tuning approach that decouples the computation of the gradient of hidden representations and parameters. In comparison to PEFT methods, ColA facilitates more cost-effective FTaaS by offloading the computation of the gradient to low-cost devices. We also provide a theoretical analysis of ColA and experimentally demonstrate that ColA can perform on par or better than existing PEFT methods on various benchmarks.
Robust Quickest Change Detection for Unnormalized Models
Jun 08, 2023



Detecting an abrupt and persistent change in the underlying distribution of online data streams is an important problem in many applications. This paper proposes a new robust score-based algorithm called RSCUSUM, which can be applied to unnormalized models and addresses the issue of unknown post-change distributions. RSCUSUM replaces the Kullback-Leibler divergence with the Fisher divergence between pre- and post-change distributions for computational efficiency in unnormalized statistical models and introduces a notion of the ``least favorable'' distribution for robust change detection. The algorithm and its theoretical analysis are demonstrated through simulation studies.
Quickest Change Detection for Unnormalized Statistical Models
Feb 01, 2023



Classical quickest change detection algorithms require modeling pre-change and post-change distributions. Such an approach may not be feasible for various machine learning models because of the complexity of computing the explicit distributions. Additionally, these methods may suffer from a lack of robustness to model mismatch and noise. This paper develops a new variant of the classical Cumulative Sum (CUSUM) algorithm for the quickest change detection. This variant is based on Fisher divergence and the Hyv\"arinen score and is called the Score-based CUSUM (SCUSUM) algorithm. The SCUSUM algorithm allows the applications of change detection for unnormalized statistical models, i.e., models for which the probability density function contains an unknown normalization constant. The asymptotic optimality of the proposed algorithm is investigated by deriving expressions for average detection delay and the mean running time to a false alarm. Numerical results are provided to demonstrate the performance of the proposed algorithm.
Minimax Concave Penalty Regularized Adaptive System Identification
Nov 07, 2022



We develop a recursive least square (RLS) type algorithm with a minimax concave penalty (MCP) for adaptive identification of a sparse tap-weight vector that represents a communication channel. The proposed algorithm recursively yields its estimate of the tap-vector, from noisy streaming observations of a received signal, using expectation-maximization (EM) update. We prove the convergence of our algorithm to a local optimum and provide bounds for the steady state error. Using simulation studies of Rayleigh fading channel, Volterra system and multivariate time series model, we demonstrate that our algorithm outperforms, in the mean-squared error (MSE) sense, the standard RLS and the $\ell_1$-regularized RLS.
Multi-Agent Adversarial Attacks for Multi-Channel Communications
Jan 27, 2022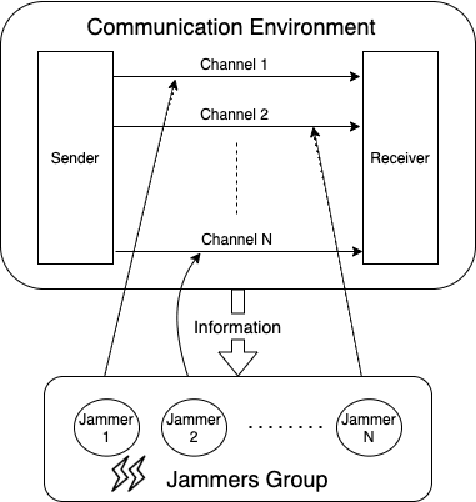
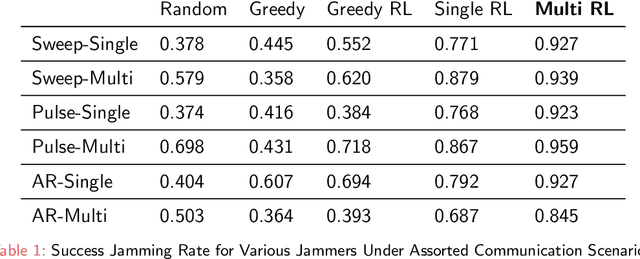
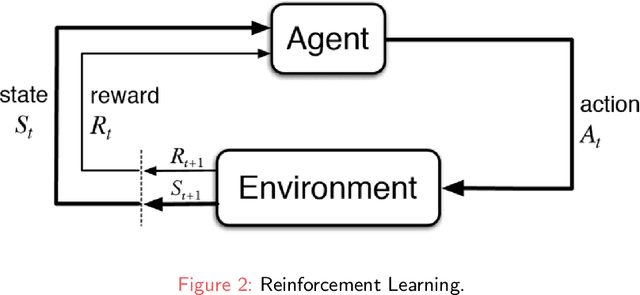
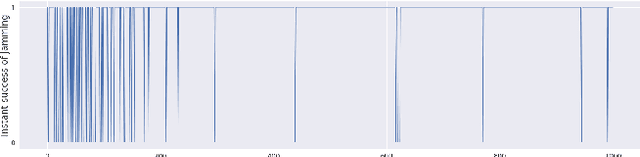
Recently Reinforcement Learning (RL) has been applied as an anti-adversarial remedy in wireless communication networks. However, studying the RL-based approaches from the adversary's perspective has received little attention. Additionally, RL-based approaches in an anti-adversary or adversarial paradigm mostly consider single-channel communication (either channel selection or single channel power control), while multi-channel communication is more common in practice. In this paper, we propose a multi-agent adversary system (MAAS) for modeling and analyzing adversaries in a wireless communication scenario by careful design of the reward function under realistic communication scenarios. In particular, by modeling the adversaries as learning agents, we show that the proposed MAAS is able to successfully choose the transmitted channel(s) and their respective allocated power(s) without any prior knowledge of the sender strategy. Compared to the single-agent adversary (SAA), multi-agents in MAAS can achieve significant reduction in signal-to-noise ratio (SINR) under the same power constraints and partial observability, while providing improved stability and a more efficient learning process. Moreover, through empirical studies we show that the results in simulation are close to the ones in communication in reality, a conclusion that is pivotal to the validity of performance of agents evaluated in simulations.
On The Energy Statistics of Feature Maps in Pruning of Neural Networks with Skip-Connections
Jan 26, 2022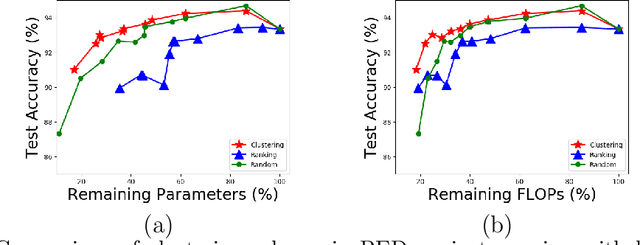
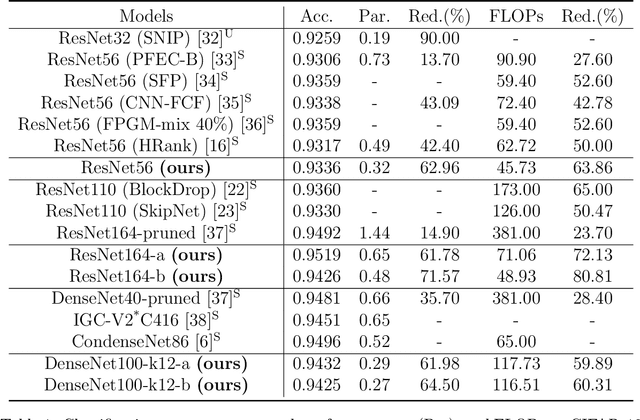
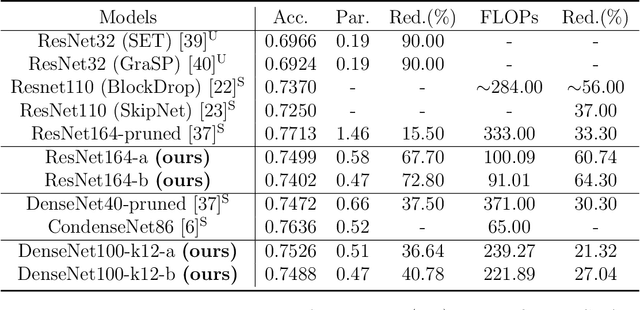
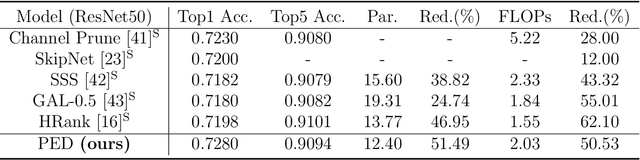
We propose a new structured pruning framework for compressing Deep Neural Networks (DNNs) with skip connections, based on measuring the statistical dependency of hidden layers and predicted outputs. The dependence measure defined by the energy statistics of hidden layers serves as a model-free measure of information between the feature maps and the output of the network. The estimated dependence measure is subsequently used to prune a collection of redundant and uninformative layers. Model-freeness of our measure guarantees that no parametric assumptions on the feature map distribution are required, making it computationally appealing for very high dimensional feature space in DNNs. Extensive numerical experiments on various architectures show the efficacy of the proposed pruning approach with competitive performance to state-of-the-art methods.
Deep Clustering of Compressed Variational Embeddings
Oct 23, 2019
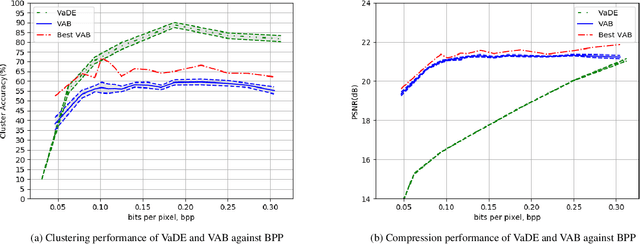
Motivated by the ever-increasing demands for limited communication bandwidth and low-power consumption, we propose a new methodology, named joint Variational Autoencoders with Bernoulli mixture models (VAB), for performing clustering in the compressed data domain. The idea is to reduce the data dimension by Variational Autoencoders (VAEs) and group data representations by Bernoulli mixture models (BMMs). Once jointly trained for compression and clustering, the model can be decomposed into two parts: a data vendor that encodes the raw data into compressed data, and a data consumer that classifies the received (compressed) data. In this way, the data vendor benefits from data security and communication bandwidth, while the data consumer benefits from low computational complexity. To enable training using the gradient descent algorithm, we propose to use the Gumbel-Softmax distribution to resolve the infeasibility of the back-propagation algorithm when assessing categorical samples.