 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Adversarial Attacks for Multi-Channel Communications
Paper and Code
Jan 27, 2022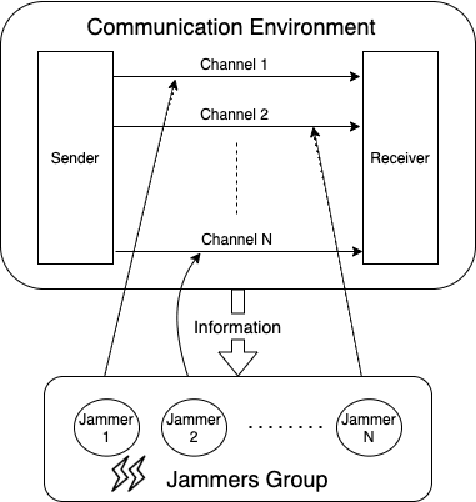
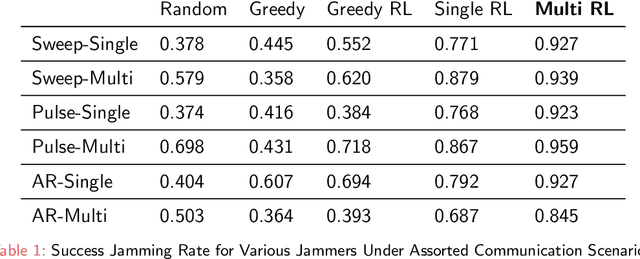
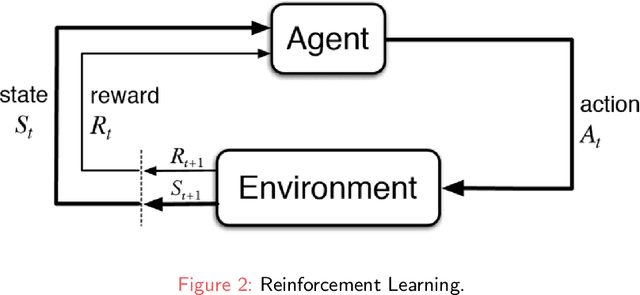
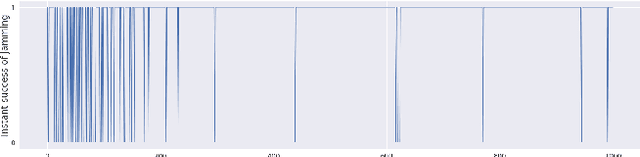
Recently Reinforcement Learning (RL) has been applied as an anti-adversarial remedy in wireless communication networks. However, studying the RL-based approaches from the adversary's perspective has received little attention. Additionally, RL-based approaches in an anti-adversary or adversarial paradigm mostly consider single-channel communication (either channel selection or single channel power control), while multi-channel communication is more common in practice. In this paper, we propose a multi-agent adversary system (MAAS) for modeling and analyzing adversaries in a wireless communication scenario by careful design of the reward function under realistic communication scenarios. In particular, by modeling the adversaries as learning agents, we show that the proposed MAAS is able to successfully choose the transmitted channel(s) and their respective allocated power(s) without any prior knowledge of the sender strategy. Compared to the single-agent adversary (SAA), multi-agents in MAAS can achieve significant reduction in signal-to-noise ratio (SINR) under the same power constraints and partial observability, while providing improved stability and a more efficient learning process. Moreover, through empirical studies we show that the results in simulation are close to the ones in communication in reality, a conclusion that is pivotal to the validity of performance of agents evaluated in simulations.