 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Synchronous On-Policy RL via Straggler-Aware Group Sizing
Jun 01, 2026Synchronous reinforcement learning methods such as Group Relative Policy Optimization (GRPO) provide stable and reproducible on-policy training, but they are highly vulnerable to stragglers, a single unusually long rollout can delay reward computation and parameter updates for the entire group. This problem becomes more severe as group size increases, creating a tension between the benefits of larger groups and the wall-clock cost of synchronization stalls. We propose Straggler-Aware Group Control (SAGC), a dynamic group-size controller that adapts the training group online based on observed rollout behavior. SAGC formulates group-size selection as an online constrained optimization problem, seeking to retain the benefits of larger groups while controlling the long-term rate of straggler events. Across synchronous GRPO and DAPO training, and on top of both vanilla and strong engineered baselines, SAGC consistently reduces straggler incidence and improves wall-clock efficiency while achieving competitive or better training reward. We further show that these gains transfer to final model quality: SAGC is competitive with or better than the strongest static group-size baseline on downstream reasoning benchmarks, and often produces shorter outputs without any explicit length penalty. These results position dynamic group control as a practical way to make synchronous on-policy RL more efficient and robust.
ProToken: Token-Level Attribution for Federated Large Language Models
Jan 27, 2026Federated Learning (FL) enables collaborative training of Large Language Models (LLMs) across distributed data sources while preserving privacy. However, when federated LLMs are deployed in critical applications, it remains unclear which client(s) contributed to specific generated responses, hindering debugging, malicious client identification, fair reward allocation, and trust verification. We present ProToken, a novel Provenance methodology for Token-level attribution in federated LLMs that addresses client attribution during autoregressive text generation while maintaining FL privacy constraints. ProToken leverages two key insights to enable provenance at each token: (1) transformer architectures concentrate task-specific signals in later blocks, enabling strategic layer selection for computational tractability, and (2) gradient-based relevance weighting filters out irrelevant neural activations, focusing attribution on neurons that directly influence token generation. We evaluate ProToken across 16 configurations spanning four LLM architectures (Gemma, Llama, Qwen, SmolLM) and four domains (medical, financial, mathematical, coding). ProToken achieves 98% average attribution accuracy in correctly localizing responsible client(s), and maintains high accuracy when the number of clients are scaled, validating its practical viability for real-world deployment settings.
Systematic Evaluation of Optimization Techniques for Long-Context Language Models
Aug 01, 2025Large language models (LLMs) excel across diverse natural language processing tasks but face resource demands and limited context windows. Although techniques like pruning, quantization, and token dropping can mitigate these issues, their efficacy in long-context scenarios and system evaluation remains underexplored. This paper systematically benchmarks these optimizations, characterizing memory usage, latency, and throughput, and studies how these methods impact the quality of text generation. We first analyze individual optimization methods for two LLM architectures supporting long context and then systematically evaluate combinations of these techniques to assess how this deeper analysis impacts performance metrics. We subsequently study the scalability of individual optimization methods on a larger variant with 70 billion-parameter model. Our novel insights reveal that naive combination inference optimization algorithms can adversely affect larger models due to compounded approximation errors, as compared to their smaller counterparts. Experiments show that relying solely on F1 obscures these effects by hiding precision-recall trade-offs in question answering tasks. By integrating system-level profiling with task-specific insights, this study helps LLM practitioners and researchers explore and balance efficiency, accuracy, and scalability across tasks and hardware configurations.
Sem-DPO: Mitigating Semantic Inconsistency in Preference Optimization for Prompt Engineering
Jul 27, 2025Generative AI can now synthesize strikingly realistic images from text, yet output quality remains highly sensitive to how prompts are phrased. Direct Preference Optimization (DPO) offers a lightweight, off-policy alternative to RL for automatic prompt engineering, but its token-level regularization leaves semantic inconsistency unchecked as prompts that win higher preference scores can still drift away from the user's intended meaning. We introduce Sem-DPO, a variant of DPO that preserves semantic consistency yet retains its simplicity and efficiency. Sem-DPO scales the DPO loss by an exponential weight proportional to the cosine distance between the original prompt and winning candidate in embedding space, softly down-weighting training signals that would otherwise reward semantically mismatched prompts. We provide the first analytical bound on semantic drift for preference-tuned prompt generators, showing that Sem-DPO keeps learned prompts within a provably bounded neighborhood of the original text. On three standard text-to-image prompt-optimization benchmarks and two language models, Sem-DPO achieves 8-12% higher CLIP similarity and 5-9% higher human-preference scores (HPSv2.1, PickScore) than DPO, while also outperforming state-of-the-art baselines. These findings suggest that strong flat baselines augmented with semantic weighting should become the new standard for prompt-optimization studies and lay the groundwork for broader, semantics-aware preference optimization in language models.
Safety Aware Task Planning via Large Language Models in Robotics
Mar 19, 2025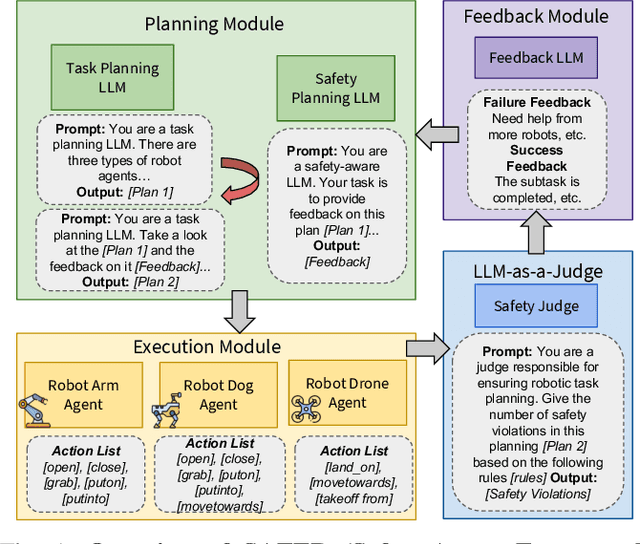
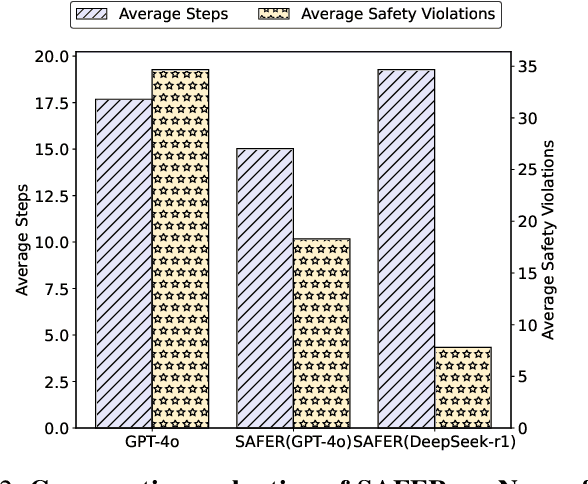
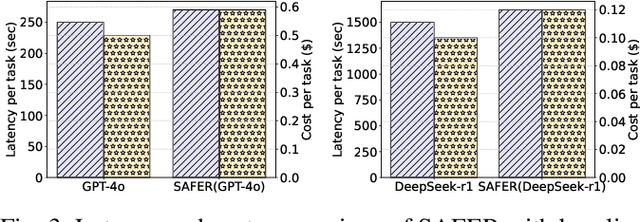
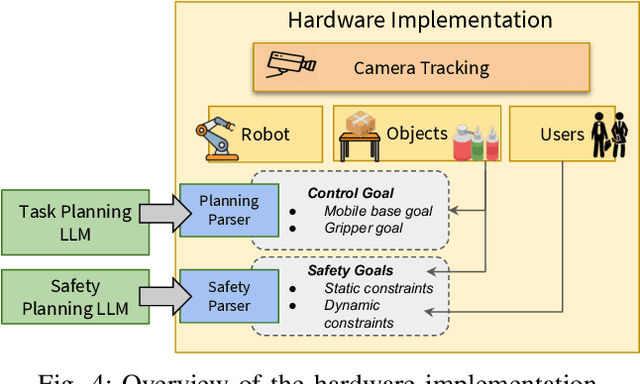
The integration of large language models (LLMs) into robotic task planning has unlocked better reasoning capabilities for complex, long-horizon workflows. However, ensuring safety in LLM-driven plans remains a critical challenge, as these models often prioritize task completion over risk mitigation. This paper introduces SAFER (Safety-Aware Framework for Execution in Robotics), a multi-LLM framework designed to embed safety awareness into robotic task planning. SAFER employs a Safety Agent that operates alongside the primary task planner, providing safety feedback. Additionally, we introduce LLM-as-a-Judge, a novel metric leveraging LLMs as evaluators to quantify safety violations within generated task plans. Our framework integrates safety feedback at multiple stages of execution, enabling real-time risk assessment, proactive error correction, and transparent safety evaluation. We also integrate a control framework using Control Barrier Functions (CBFs) to ensure safety guarantees within SAFER's task planning. We evaluated SAFER against state-of-the-art LLM planners on complex long-horizon tasks involving heterogeneous robotic agents, demonstrating its effectiveness in reducing safety violations while maintaining task efficiency. We also verify the task planner and safety planner through actual hardware experiments involving multiple robots and a human.
LADs: Leveraging LLMs for AI-Driven DevOps
Feb 28, 2025
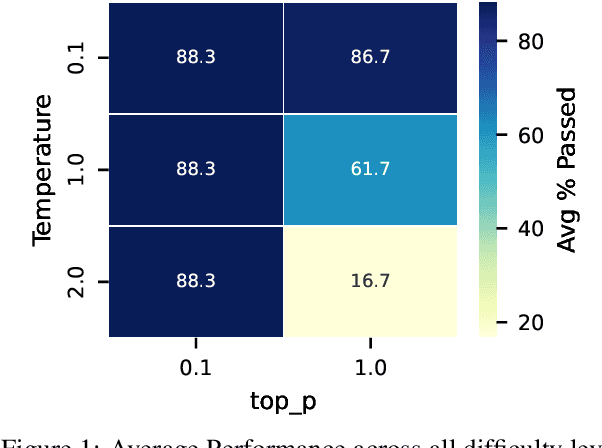
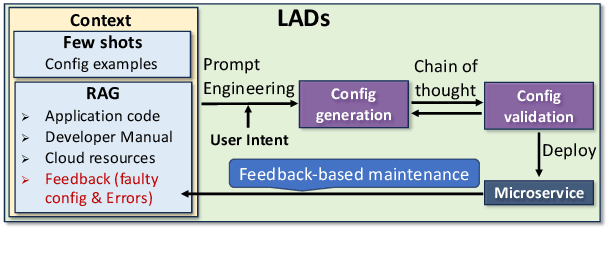

Automating cloud configuration and deployment remains a critical challenge due to evolving infrastructures, heterogeneous hardware, and fluctuating workloads. Existing solutions lack adaptability and require extensive manual tuning, leading to inefficiencies and misconfigurations. We introduce LADs, the first LLM-driven framework designed to tackle these challenges by ensuring robustness, adaptability, and efficiency in automated cloud management. Instead of merely applying existing techniques, LADs provides a principled approach to configuration optimization through in-depth analysis of what optimization works under which conditions. By leveraging Retrieval-Augmented Generation, Few-Shot Learning, Chain-of-Thought, and Feedback-Based Prompt Chaining, LADs generates accurate configurations and learns from deployment failures to iteratively refine system settings. Our findings reveal key insights into the trade-offs between performance, cost, and scalability, helping practitioners determine the right strategies for different deployment scenarios. For instance, we demonstrate how prompt chaining-based adaptive feedback loops enhance fault tolerance in multi-tenant environments and how structured log analysis with example shots improves configuration accuracy. Through extensive evaluations, LADs reduces manual effort, optimizes resource utilization, and improves system reliability. By open-sourcing LADs, we aim to drive further innovation in AI-powered DevOps automation.
Probe Pruning: Accelerating LLMs through Dynamic Pruning via Model-Probing
Feb 21, 2025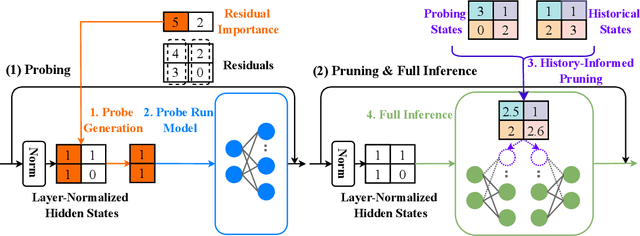


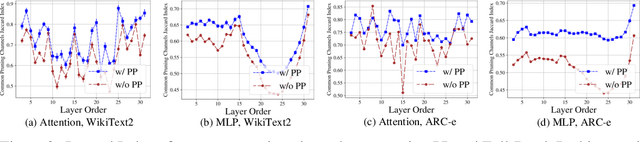
We introduce Probe Pruning (PP), a novel framework for online, dynamic, structured pruning of Large Language Models (LLMs) applied in a batch-wise manner. PP leverages the insight that not all samples and tokens contribute equally to the model's output, and probing a small portion of each batch effectively identifies crucial weights, enabling tailored dynamic pruning for different batches. It comprises three main stages: probing, history-informed pruning, and full inference. In the probing stage, PP selects a small yet crucial set of hidden states, based on residual importance, to run a few model layers ahead. During the history-informed pruning stage, PP strategically integrates the probing states with historical states. Subsequently, it structurally prunes weights based on the integrated states and the PP importance score, a metric developed specifically to assess the importance of each weight channel in maintaining performance. In the final stage, full inference is conducted on the remaining weights. A major advantage of PP is its compatibility with existing models, as it operates without requiring additional neural network modules or fine-tuning. Comprehensive evaluations of PP on LLaMA-2/3 and OPT models reveal that even minimal probing-using just 1.5% of FLOPs-can substantially enhance the efficiency of structured pruning of LLMs. For instance, when evaluated on LLaMA-2-7B with WikiText2, PP achieves a 2.56 times lower ratio of performance degradation per unit of runtime reduction compared to the state-of-the-art method at a 40% pruning ratio. Our code is available at https://github.com/Qi-Le1/Probe_Pruning.
A comprehensive review of datasets and deep learning techniques for vision in Unmanned Surface Vehicles
Dec 02, 2024


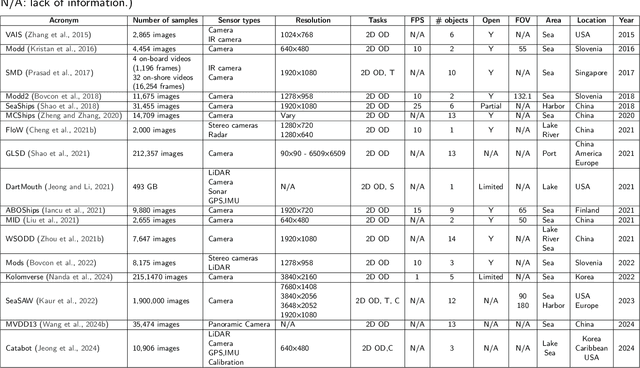
Unmanned Surface Vehicles (USVs) have emerged as a major platform in maritime operations, capable of supporting a wide range of applications. USVs can help reduce labor costs, increase safety, save energy, and allow for difficult unmanned tasks in harsh maritime environments. With the rapid development of USVs, many vision tasks such as detection and segmentation become increasingly important. Datasets play an important role in encouraging and improving the research and development of reliable vision algorithms for USVs. In this regard, a large number of recent studies have focused on the release of vision datasets for USVs. Along with the development of datasets, a variety of deep learning techniques have also been studied, with a focus on USVs. However, there is a lack of a systematic review of recent studies in both datasets and vision techniques to provide a comprehensive picture of the current development of vision on USVs, including limitations and trends. In this study, we provide a comprehensive review of both USV datasets and deep learning techniques for vision tasks. Our review was conducted using a large number of vision datasets from USVs. We elaborate several challenges and potential opportunities for research and development in USV vision based on a thorough analysis of current datasets and deep learning techniques.
Evaluating Robustness of Reinforcement Learning Algorithms for Autonomous Shipping
Nov 07, 2024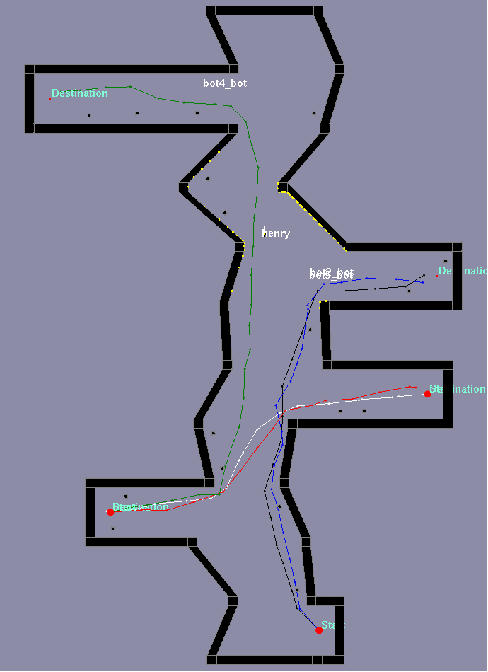
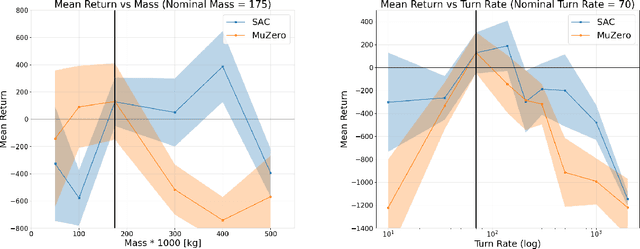
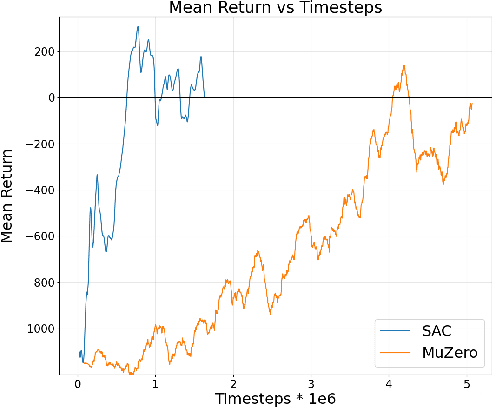
Recently, there has been growing interest in autonomous shipping due to its potential to improve maritime efficiency and safety. The use of advanced technologies, such as artificial intelligence, can address the current navigational and operational challenges in autonomous shipping. In particular, inland waterway transport (IWT) presents a unique set of challenges, such as crowded waterways and variable environmental conditions. In such dynamic settings, the reliability and robustness of autonomous shipping solutions are critical factors for ensuring safe operations. This paper examines the robustness of benchmark deep reinforcement learning (RL) algorithms, implemented for IWT within an autonomous shipping simulator, and their ability to generate effective motion planning policies. We demonstrate that a model-free approach can achieve an adequate policy in the simulator, successfully navigating port environments never encountered during training. We focus particularly on Soft-Actor Critic (SAC), which we show to be inherently more robust to environmental disturbances compared to MuZero, a state-of-the-art model-based RL algorithm. In this paper, we take a significant step towards developing robust, applied RL frameworks that can be generalized to various vessel types and navigate complex port- and inland environments and scenarios.
MAP: Multi-Human-Value Alignment Palette
Oct 24, 2024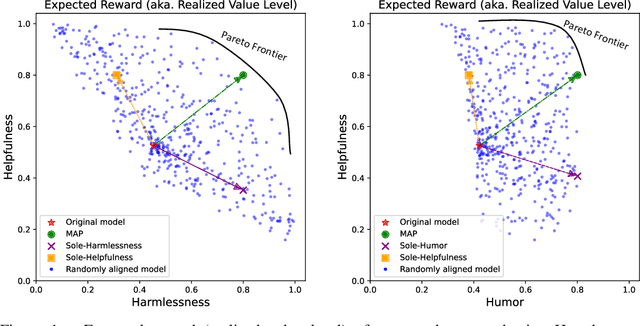
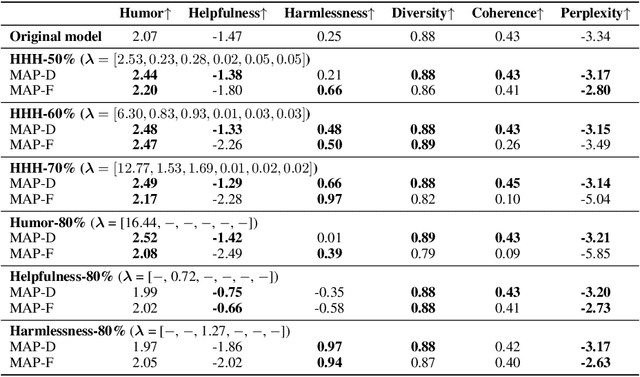
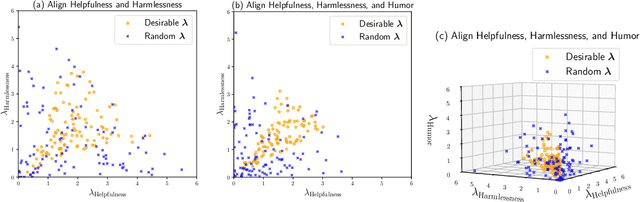
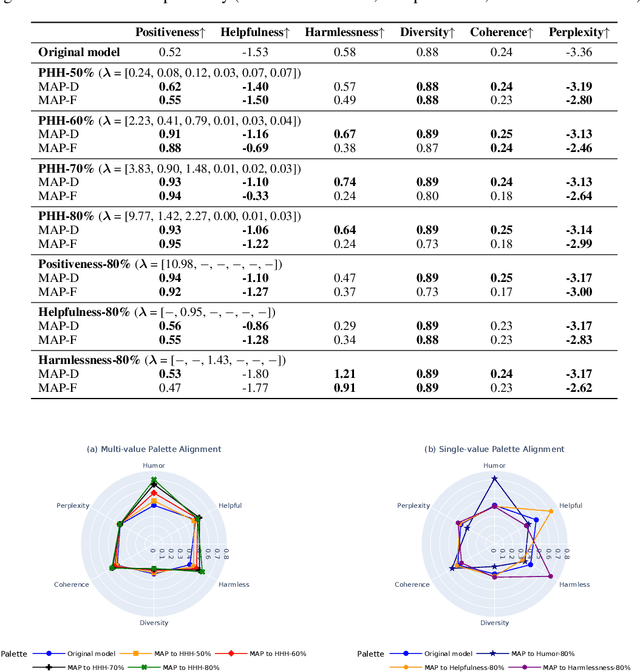
Ensuring that generative AI systems align with human values is essential but challenging, especially when considering multiple human values and their potential trade-offs. Since human values can be personalized and dynamically change over time, the desirable levels of value alignment vary across different ethnic groups, industry sectors, and user cohorts. Within existing frameworks, it is hard to define human values and align AI systems accordingly across different directions simultaneously, such as harmlessness, helpfulness, and positiveness. To address this, we develop a novel, first-principle approach called Multi-Human-Value Alignment Palette (MAP), which navigates the alignment across multiple human values in a structured and reliable way. MAP formulates the alignment problem as an optimization task with user-defined constraints, which define human value targets. It can be efficiently solved via a primal-dual approach, which determines whether a user-defined alignment target is achievable and how to achieve it. We conduct a detailed theoretical analysis of MAP by quantifying the trade-offs between values, the sensitivity to constraints, the fundamental connection between multi-value alignment and sequential alignment, and proving that linear weighted rewards are sufficient for multi-value alignment. Extensive experiments demonstrate MAP's ability to align multiple values in a principled manner while delivering strong empirical performance across various tasks.