 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comprehensive review of datasets and deep learning techniques for vision in Unmanned Surface Vehicles
Dec 02, 2024


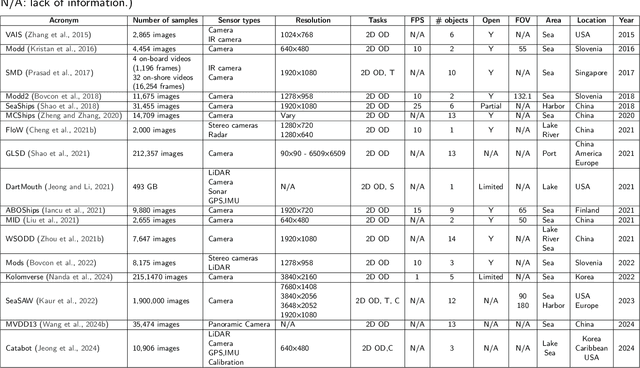
Unmanned Surface Vehicles (USVs) have emerged as a major platform in maritime operations, capable of supporting a wide range of applications. USVs can help reduce labor costs, increase safety, save energy, and allow for difficult unmanned tasks in harsh maritime environments. With the rapid development of USVs, many vision tasks such as detection and segmentation become increasingly important. Datasets play an important role in encouraging and improving the research and development of reliable vision algorithms for USVs. In this regard, a large number of recent studies have focused on the release of vision datasets for USVs. Along with the development of datasets, a variety of deep learning techniques have also been studied, with a focus on USVs. However, there is a lack of a systematic review of recent studies in both datasets and vision techniques to provide a comprehensive picture of the current development of vision on USVs, including limitations and trends. In this study, we provide a comprehensive review of both USV datasets and deep learning techniques for vision tasks. Our review was conducted using a large number of vision datasets from USVs. We elaborate several challenges and potential opportunities for research and development in USV vision based on a thorough analysis of current datasets and deep learning techniques.
Improving classification of road surface conditions via road area extraction and contrastive learning
Jul 19, 2024Maintaining roads is crucial to economic growth and citizen well-being because roads are a vital means of transportation. In various countries, the inspection of road surfaces is still done manually, however, to automate it, research interest is now focused on detecting the road surface defects via the visual data. While, previous research has been focused on deep learning methods which tend to process the entire image and leads to heavy computational cost. In this study, we focus our attention on improving the classification performance while keeping the computational cost of our solution low. Instead of processing the whole image, we introduce a segmentation model to only focus the downstream classification model to the road surface in the image. Furthermore, we employ contrastive learning during model training to improve the road surface condition classification. Our experiments on the public RTK dataset demonstrate a significant improvement in our proposed method when compared to previous works.
Data selection method for assessment of autonomous vehicles
Jul 16, 2024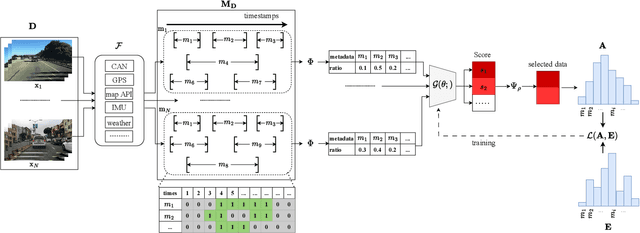
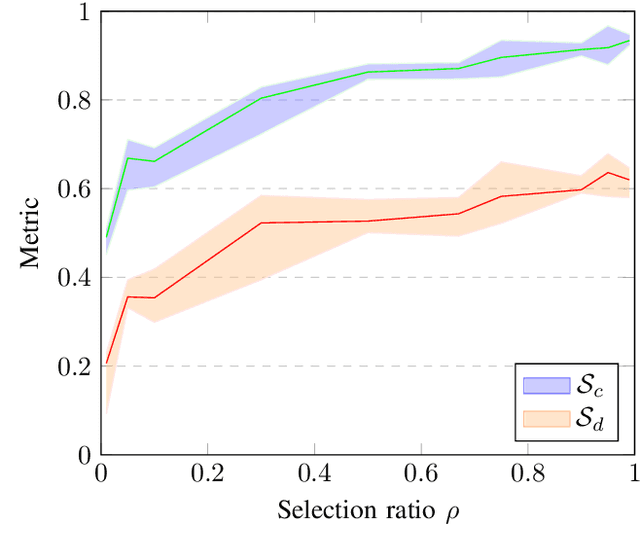

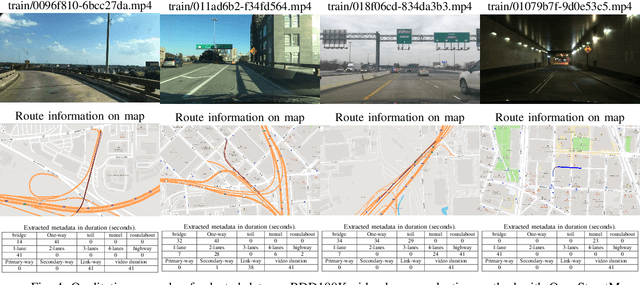
As the popularity of autonomous vehicles has grown, many standards and regulators, such as ISO, NHTSA, and Euro NCAP, require safety validation to ensure a sufficient level of safety before deploying them in the real world. Manufacturers gather a large amount of public road data for this purpose. However, the majority of these validation activities are done manually by humans. Furthermore, the data used to validate each driving feature may differ. As a result, it is essential to have an efficient data selection method that can be used flexibly and dynamically for verification and validation while also accelerating the validation process. In this paper, we present a data selection method that is practical, flexible, and efficient for assessment of autonomous vehicles. Our idea is to optimize the similarity between the metadata distribution of the selected data and a predefined metadata distribution that is expected for validation. Our experiments on the large dataset BDD100K show that our method can perform data selection tasks efficiently. These results demonstrate that our methods are highly reliable and can be used to select appropriate data for the validation of various safety functions.
Multiple data sources and domain generalization learning method for road surface defect classification
Jul 14, 2024



Roads are an essential mode of transportation, and maintaining them is critical to economic growth and citizen well-being. With the continued advancement of AI, road surface inspection based on camera images has recently been extensively researched and can be performed automatically. However, because almost all of the deep learning methods for detecting road surface defects were optimized for a specific dataset, they are difficult to apply to a new, previously unseen dataset. Furthermore, there is a lack of research on training an efficient model using multiple data sources. In this paper, we propose a method for classifying road surface defects using camera images. In our method, we propose a scheme for dealing with the invariance of multiple data sources while training a model on multiple data sources. Furthermore, we present a domain generalization training algorithm for developing a generalized model that can work with new, completely unseen data sources without requiring model updates. We validate our method using an experiment with six data sources corresponding to six countries from the RDD2022 dataset. The results show that our method can efficiently classify road surface defects on previously unseen data.
A novel framework for adaptive stress testing of autonomous vehicles in highways
Feb 19, 2024



Guaranteeing the safe operations of autonomous vehicles (AVs) is crucial for their widespread adoption and public acceptance. It is thus of a great significance to not only assess the AV against the standard safety tests, but also discover potential corner cases of the AV under test that could lead to unsafe behaviour or scenario. In this paper, we propose a novel framework to systematically explore corner cases that can result in safety concerns in a highway traffic scenario. The framework is based on an adaptive stress testing (AST) approach, an emerging validation method that leverages a Markov decision process to formulate the scenarios and deep reinforcement learning (DRL) to discover the desirable patterns representing corner cases. To this end, we develop a new reward function for DRL to guide the AST in identifying crash scenarios based on the collision probability estimate between the AV under test (i.e., the ego vehicle) and the trajectory of other vehicles on the highway. The proposed framework is further integrated with a new driving model enabling us to create more realistic traffic scenarios capturing both the longitudinal and lateral movements of vehicles on the highway. In our experiment, we calibrate our model using real-world crash statistics involving automated vehicles in California, and then we analyze the characteristics of the AV and the framework. Quantitative and qualitative analyses of our experimental results demonstrate that our framework outperforms other existing AST schemes. The study can help discover crash scenarios of AV that are unknown or absent in human driving, thereby enhancing the safety and trustworthiness of AV technology.
TurtleRabbit 2024 SSL Team Description Paper
Feb 13, 2024

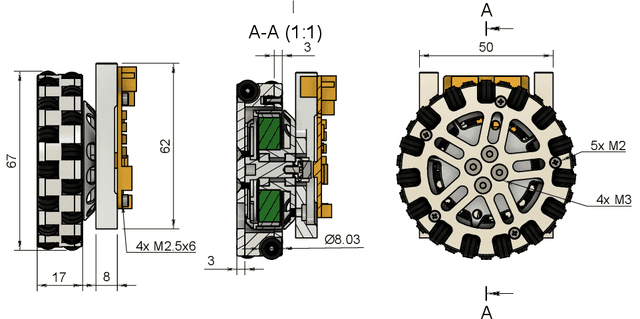

TurtleRabbit is a new RoboCup SSL team from Western Sydney University. This team description paper presents our approach in navigating some of the challenges in developing a new SSL team from scratch. SSL is dominated by teams with extensive experience and customised equipment that has been developed over many years. Here, we outline our approach in overcoming some of the complexities associated with replicating advanced open-sourced designs and managing the high costs of custom components. Opting for simplicity and cost-effectiveness, our strategy primarily employs off-the-shelf electronics components and ``hobby'' brushless direct current (BLDC) motors, complemented by 3D printing and CNC milling. This approach helped us to streamline the development process and, with our open-sourced hardware design, hopefully will also lower the bar for other teams to enter RoboCup SSL in the future. The paper details the specific hardware choices, their approximate costs, the integration of electronics and mechanics, and the initial steps taken in software development, for our entry into SSL that aims to be simple yet competitive.
SeaDSC: A video-based unsupervised method for dynamic scene change detection in unmanned surface vehicles
Nov 20, 2023Recently, there has been an upsurge in the research on maritime vision, where a lot of works are influenced by the application of computer vision for Unmanned Surface Vehicles (USVs). Various sensor modalities such as camera, radar, and lidar have been used to perform tasks such as object detection, segmentation, object tracking, and motion planning. A large subset of this research is focused on the video analysis, since most of the current vessel fleets contain the camera's onboard for various surveillance tasks. Due to the vast abundance of the video data, video scene change detection is an initial and crucial stage for scene understanding of USVs. This paper outlines our approach to detect dynamic scene changes in USVs. To the best of our understanding, this work represents the first investigation of scene change detection in the maritime vision application. Our objective is to identify significant changes in the dynamic scenes of maritime video data, particularly those scenes that exhibit a high degree of resemblance. In our system for dynamic scene change detection, we propose completely unsupervised learning method. In contrast to earlier studies, we utilize a modified cutting-edge generative picture model called VQ-VAE-2 to train on multiple marine datasets, aiming to enhance the feature extraction. Next, we introduce our innovative similarity scoring technique for directly calculating the level of similarity in a sequence of consecutive frames by utilizing grid calculation on retrieved features. The experiments were conducted using a nautical video dataset called RoboWhaler to showcase the efficient performance of our technique.
FisheyePP4AV: A privacy-preserving method for autonomous vehicles on fisheye camera images
Sep 07, 2023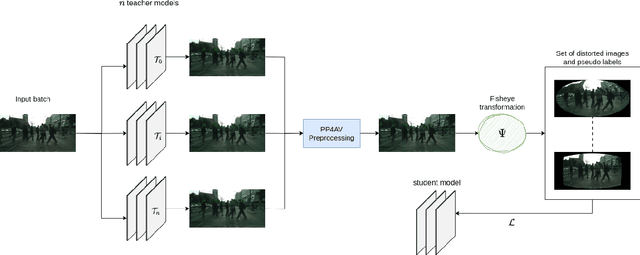

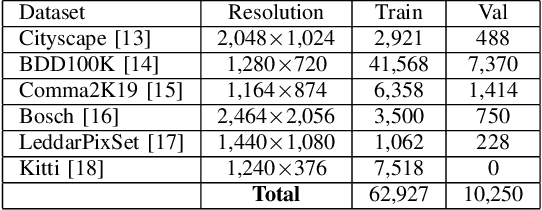
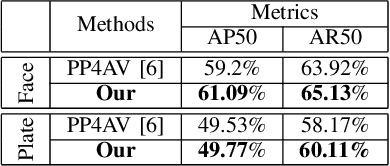
In many parts of the world, the use of vast amounts of data collected on public roadways for autonomous driving has increased. In order to detect and anonymize pedestrian faces and nearby car license plates in actual road-driving scenarios, there is an urgent need for effective solutions. As more data is collected, privacy concerns regarding it increase, including but not limited to pedestrian faces and surrounding vehicle license plates. Normal and fisheye cameras are the two common camera types that are typically mounted on collection vehicles. With complex camera distortion models, fisheye camera images were deformed in contrast to regular images. It causes computer vision tasks to perform poorly when using numerous deep learning models. In this work, we pay particular attention to protecting privacy while yet adhering to several laws for fisheye camera photos taken by driverless vehicles. First, we suggest a framework for extracting face and plate identification knowledge from several teacher models. Our second suggestion is to transform both the image and the label from a regular image to fisheye-like data using a varied and realistic fisheye transformation. Finally, we run a test using the open-source PP4AV dataset. The experimental findings demonstrated that our model outperformed baseline methods when trained on data from autonomous vehicles, even when the data were softly labeled. The implementation code is available at our github: https://github.com/khaclinh/FisheyePP4AV.
The Second Monocular Depth Estimation Challenge
Apr 26, 2023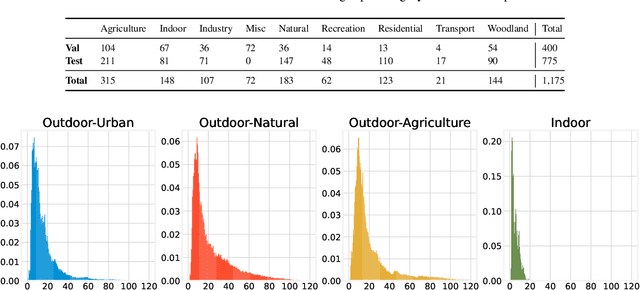
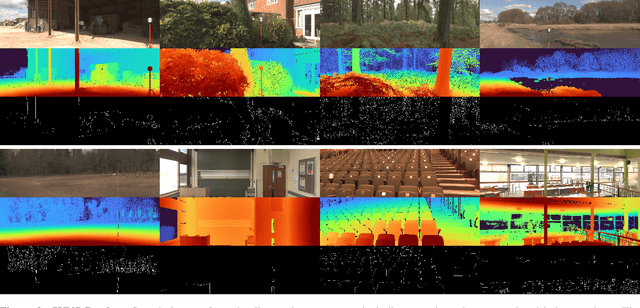
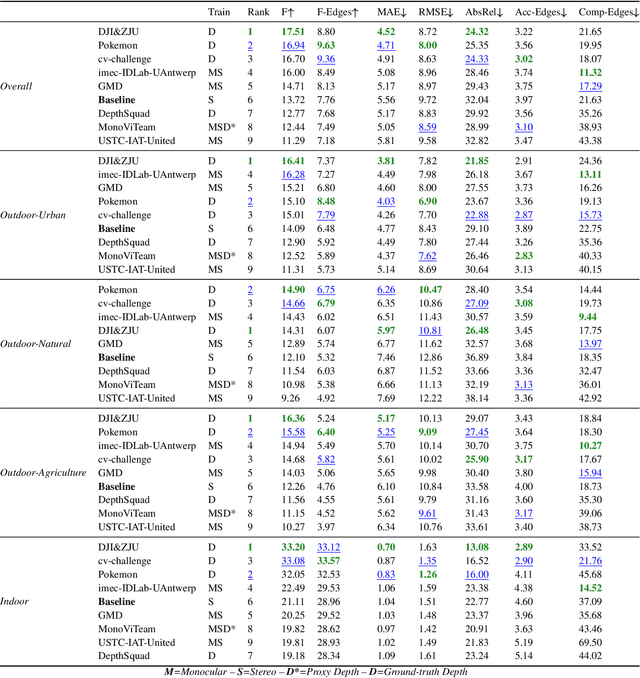
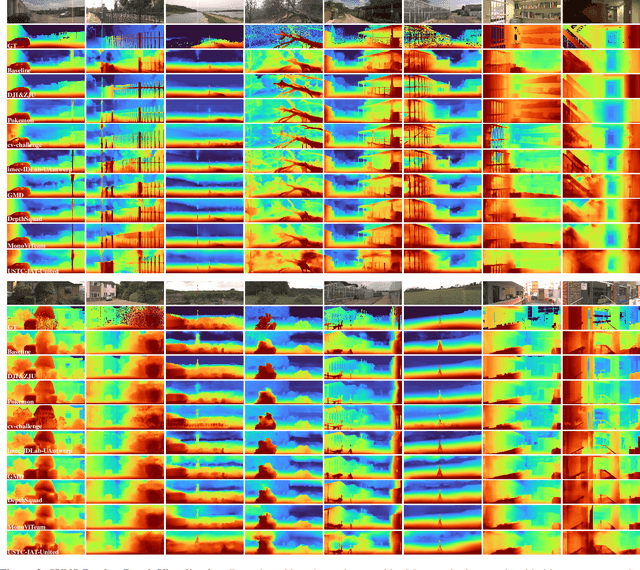
This paper discusses the results for the second edition of the Monocular Depth Estimation Challenge (MDEC). This edition was open to methods using any form of supervision, including fully-supervised, self-supervised, multi-task or proxy depth. The challenge was based around the SYNS-Patches dataset, which features a wide diversity of environments with high-quality dense ground-truth. This includes complex natural environments, e.g. forests or fields, which are greatly underrepresented in current benchmarks. The challenge received eight unique submissions that outperformed the provided SotA baseline on any of the pointcloud- or image-based metrics. The top supervised submission improved relative F-Score by 27.62%, while the top self-supervised improved it by 16.61%. Supervised submissions generally leveraged large collections of datasets to improve data diversity. Self-supervised submissions instead updated the network architecture and pretrained backbones. These results represent a significant progress in the field, while highlighting avenues for future research, such as reducing interpolation artifacts at depth boundaries, improving self-supervised indoor performance and overall natural image accuracy.