 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceGuard: Structured Multi-Dimensional Monitoring as a Collusion-Resistant Control Protocol
Apr 05, 2026AI control protocols use monitors to detect attacks by untrusted AI agents, but standard single-score monitors face two limitations: they miss subtle attacks where outputs look clean but reasoning is off, and they collapse to near-zero safety when the monitor is the same model as the agent (collusion). We present TraceGuard, a structured multi-dimensional monitoring protocol that evaluates agent actions across five dimensions -- goal alignment, constraint adherence, reasoning coherence, safety awareness, and action-trace consistency -- scored in parallel by independent LLM calls, augmented by seven heuristic detectors and an LLM-based intent analyzer. We evaluate on BashArena (637 bash tasks, 4 attack categories) within the ControlArena framework. Our results on 519 samples (279 honest, 240 attack) show that: (1) the hybrid approach achieves clear attack-honest separation (attack mean 0.616 vs. honest mean 0.206, Delta=0.410); (2) structured scoring constrains collusion -- the untrusted structured monitor achieves 95% safety vs. 0% for single-score untrusted monitoring; (3) goal alignment and constraint adherence are the most discriminative dimensions; and (4) a separation-of-duties variant splitting dimensions across trusted and untrusted models achieves 100% safety while preventing any single model from seeing the full evaluation. TraceGuard is implemented as a new monitor type for the open-source ControlArena framework.
FisheyePP4AV: A privacy-preserving method for autonomous vehicles on fisheye camera images
Sep 07, 2023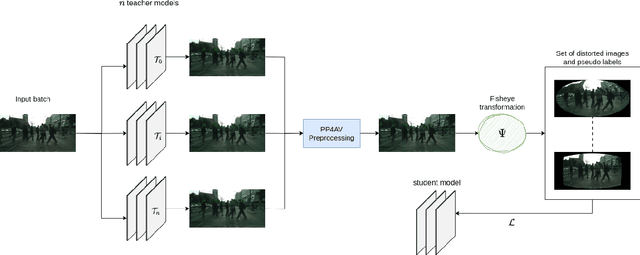

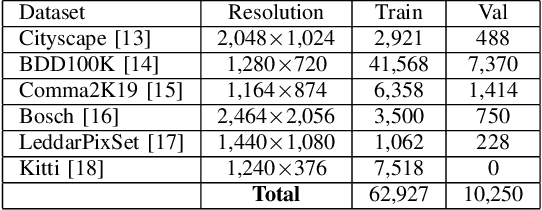
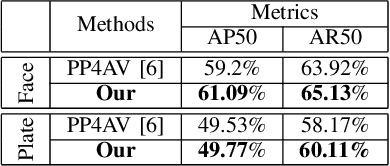
In many parts of the world, the use of vast amounts of data collected on public roadways for autonomous driving has increased. In order to detect and anonymize pedestrian faces and nearby car license plates in actual road-driving scenarios, there is an urgent need for effective solutions. As more data is collected, privacy concerns regarding it increase, including but not limited to pedestrian faces and surrounding vehicle license plates. Normal and fisheye cameras are the two common camera types that are typically mounted on collection vehicles. With complex camera distortion models, fisheye camera images were deformed in contrast to regular images. It causes computer vision tasks to perform poorly when using numerous deep learning models. In this work, we pay particular attention to protecting privacy while yet adhering to several laws for fisheye camera photos taken by driverless vehicles. First, we suggest a framework for extracting face and plate identification knowledge from several teacher models. Our second suggestion is to transform both the image and the label from a regular image to fisheye-like data using a varied and realistic fisheye transformation. Finally, we run a test using the open-source PP4AV dataset. The experimental findings demonstrated that our model outperformed baseline methods when trained on data from autonomous vehicles, even when the data were softly labeled. The implementation code is available at our github: https://github.com/khaclinh/FisheyePP4AV.
Hybrid Long Document Summarization using C2F-FAR and ChatGPT: A Practical Study
Jun 01, 2023



Text summarization is a downstream natural language processing (NLP) task that challenges the understanding and generation capabilities of language models. Considerable progress has been made in automatically summarizing short texts, such as news articles, often leading to satisfactory results. However, summarizing long documents remains a major challenge. This is due to the complex contextual information in the text and the lack of open-source benchmarking datasets and evaluation frameworks that can be used to develop and test model performance. In this work, we use ChatGPT, the latest breakthrough in the field of large language models (LLMs), together with the extractive summarization model C2F-FAR (Coarse-to-Fine Facet-Aware Ranking) to propose a hybrid extraction and summarization pipeline for long documents such as business articles and books. We work with the world-renowned company getAbstract AG and leverage their expertise and experience in professional book summarization. A practical study has shown that machine-generated summaries can perform at least as well as human-written summaries when evaluated using current automated evaluation metrics. However, a closer examination of the texts generated by ChatGPT through human evaluations has shown that there are still critical issues in terms of text coherence, faithfulness, and style. Overall, our results show that the use of ChatGPT is a very promising but not yet mature approach for summarizing long documents and can at best serve as an inspiration for human editors. We anticipate that our work will inform NLP researchers about the extent to which ChatGPT's capabilities for summarizing long documents overlap with practitioners' needs. Further work is needed to test the proposed hybrid summarization pipeline, in particular involving GPT-4, and to propose a new evaluation framework tailored to the task of summarizing long documents.