 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Hoc Robustness for Model-Based Reinforcement Learning
Jun 02, 2026To improve the real-world applicability of reinforcement learning (RL), the field of adversarially robust RL studies how to train agents under adversarial environment perturbations. In this setting, a protagonist agent optimizes a policy under environmental perturbations from an adversary, resulting in a zero-sum Markov game. When adversarially robust RL is combined with model-based RL, the adversary can target a learned transition model instead of the training environment. Extending this idea, this work introduces post-hoc robustification of deep RL agents at inference time. By using the learned model in combination with a trained nominal policy, our approach performs a robust policy improvement step. The goal is to improve robustness without any additional training of neural networks. Specifically, we utilize model-predictive control under adversarial rollouts, which are approximated via projected gradient descent within a bounded uncertainty set. Furthermore, these offline rollouts are performed while considering and mitigating out-of-distribution issues. The proposed methodology is validated by demonstrating significant improvements in robustness when the algorithm is evaluated in perturbed Gymnasium MuJoCo environments, while considering the computational limitations of the post-hoc inference setting.
A Hybrid Inductive-Transductive Network for Traffic Flow Imputation on Unsampled Locations
Dec 19, 2025


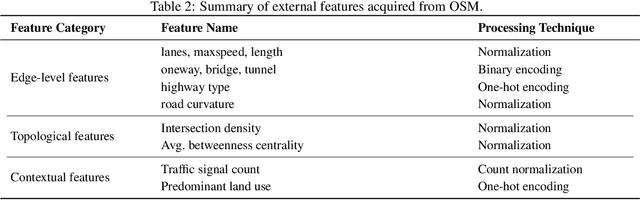
Accurately imputing traffic flow at unsensed locations is difficult: loop detectors provide precise but sparse measurements, speed from probe vehicles is widely available yet only weakly correlated with flow, and nearby links often exhibit strong heterophily in the scale of traffic flow (e.g., ramps vs. mainline), which breaks standard GNN assumptions. We propose HINT, a Hybrid INductive-Transductive Network, and an INDU-TRANSDUCTIVE training strategy that treats speed as a transductive, network-wide signal while learning flow inductively to generalize to unseen locations. HINT couples (i) an inductive spatial transformer that learns similarity-driven, long-range interactions from node features with (ii) a diffusion GCN conditioned by FiLM on rich static context (OSM-derived attributes and traffic simulation), and (iii) a node-wise calibration layer that corrects scale biases per segment. Training uses masked reconstruction with epoch-wise node sampling, hard-node mining to emphasize difficult sensors, and noise injection on visible flows to prevent identity mapping, while graph structure is built from driving distances. Across three real-world datasets, MOW (Antwerp, Belgium), UTD19-Torino, and UTD19-Essen, HINT consistently surpasses state-of-the-art inductive baselines. Relative to KITS, HINT reduces MAE on MOW by $\approx42$% with basic simulation and $\approx50$% with calibrated simulation; on Torino by $\approx22$%, and on Essen by $\approx12$%. Even without simulation, HINT remains superior on MOW and Torino, while simulation is crucial on Essen. These results show that combining inductive flow imputation with transductive speed, traffic simulations and external geospatial improves accuracy for the task described above.
PAPN: Proximity Attention Encoder and Pointer Network Decoder for Parcel Pickup Route Prediction
Apr 30, 2025Optimization of the last-mile delivery and first-mile pickup of parcels is an integral part of the broader logistics optimization pipeline as it entails both cost and resource efficiency as well as a heightened service quality. Such optimization requires accurate route and time prediction systems to adapt to different scenarios in advance. This work tackles the first building block, namely route prediction. This is done by introducing a novel Proximity Attention mechanism in an encoder-decoder architecture utilizing a Pointer Network in the decoding process (Proximity Attention Encoder and Pointer Network decoder: PAPN) to leverage the underlying connections between the different visitable pickup positions at each timestep. To this local attention process is coupled global context computing via a multi-head attention transformer encoder. The obtained global context is then mixed to an aggregated version of the local embedding thus achieving a mix of global and local attention for complete modeling of the problems. Proximity attention is also used in the decoding process to skew predictions towards the locations with the highest attention scores and thus using inter-connectivity of locations as a base for next-location prediction. This method is trained, validated and tested on a large industry-level dataset of real-world, large-scale last-mile delivery and first-mile pickup named LaDE[1]. This approach shows noticeable promise, outperforming all state-of-the-art supervised systems in terms of most metrics used for benchmarking methods on this dataset while still being competitive with the best-performing reinforcement learning method named DRL4Route[2].
A comprehensive review of datasets and deep learning techniques for vision in Unmanned Surface Vehicles
Dec 02, 2024


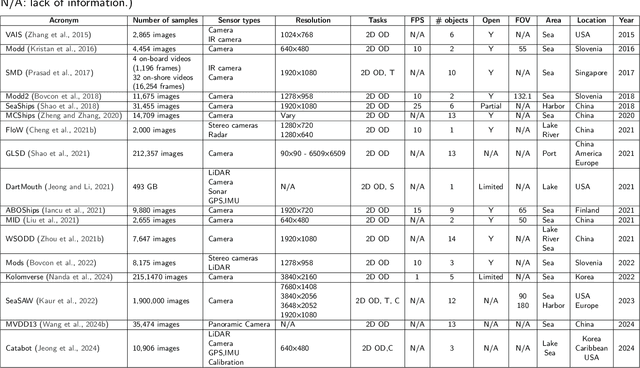
Unmanned Surface Vehicles (USVs) have emerged as a major platform in maritime operations, capable of supporting a wide range of applications. USVs can help reduce labor costs, increase safety, save energy, and allow for difficult unmanned tasks in harsh maritime environments. With the rapid development of USVs, many vision tasks such as detection and segmentation become increasingly important. Datasets play an important role in encouraging and improving the research and development of reliable vision algorithms for USVs. In this regard, a large number of recent studies have focused on the release of vision datasets for USVs. Along with the development of datasets, a variety of deep learning techniques have also been studied, with a focus on USVs. However, there is a lack of a systematic review of recent studies in both datasets and vision techniques to provide a comprehensive picture of the current development of vision on USVs, including limitations and trends. In this study, we provide a comprehensive review of both USV datasets and deep learning techniques for vision tasks. Our review was conducted using a large number of vision datasets from USVs. We elaborate several challenges and potential opportunities for research and development in USV vision based on a thorough analysis of current datasets and deep learning techniques.
Task Adaptation of Reinforcement Learning-based NAS Agents through Transfer Learning
Dec 02, 2024Recently, a novel paradigm has been proposed for reinforcement learning-based NAS agents, that revolves around the incremental improvement of a given architecture. We assess the abilities of such reinforcement learning agents to transfer between different tasks. We perform our evaluation using the Trans-NASBench-101 benchmark, and consider the efficacy of the transferred agents, as well as how quickly they can be trained. We find that pretraining an agent on one task benefits the performance of the agent in another task in all but 1 task when considering final performance. We also show that the training procedure for an agent can be shortened significantly by pretraining it on another task. Our results indicate that these effects occur regardless of the source or target task, although they are more pronounced for some tasks than for others. Our results show that transfer learning can be an effective tool in mitigating the computational cost of the initial training procedure for reinforcement learning-based NAS agents.
Evaluating Robustness of Reinforcement Learning Algorithms for Autonomous Shipping
Nov 07, 2024
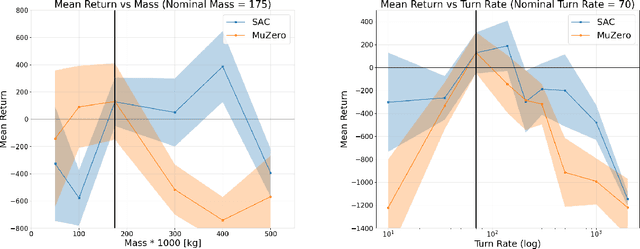
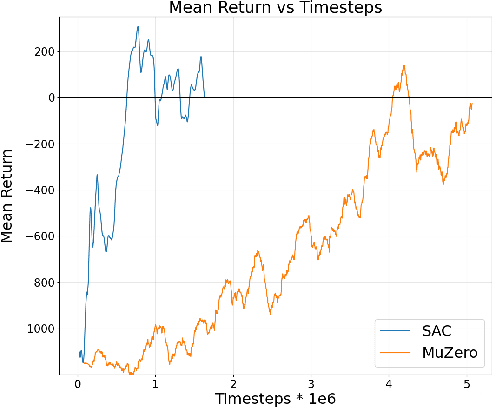
Recently, there has been growing interest in autonomous shipping due to its potential to improve maritime efficiency and safety. The use of advanced technologies, such as artificial intelligence, can address the current navigational and operational challenges in autonomous shipping. In particular, inland waterway transport (IWT) presents a unique set of challenges, such as crowded waterways and variable environmental conditions. In such dynamic settings, the reliability and robustness of autonomous shipping solutions are critical factors for ensuring safe operations. This paper examines the robustness of benchmark deep reinforcement learning (RL) algorithms, implemented for IWT within an autonomous shipping simulator, and their ability to generate effective motion planning policies. We demonstrate that a model-free approach can achieve an adequate policy in the simulator, successfully navigating port environments never encountered during training. We focus particularly on Soft-Actor Critic (SAC), which we show to be inherently more robust to environmental disturbances compared to MuZero, a state-of-the-art model-based RL algorithm. In this paper, we take a significant step towards developing robust, applied RL frameworks that can be generalized to various vessel types and navigate complex port- and inland environments and scenarios.
Designing a Classifier for Active Fire Detection from Multispectral Satellite Imagery Using Neural Architecture Search
Oct 07, 2024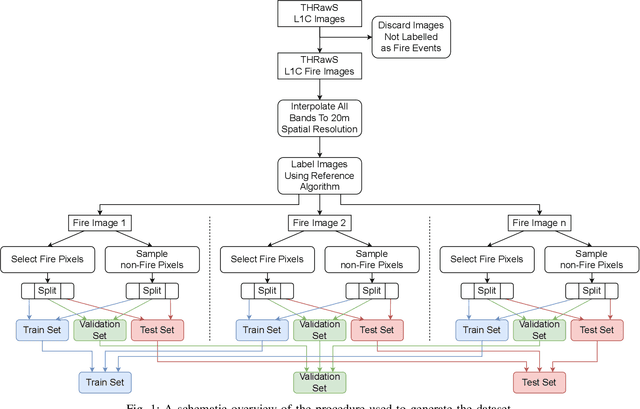
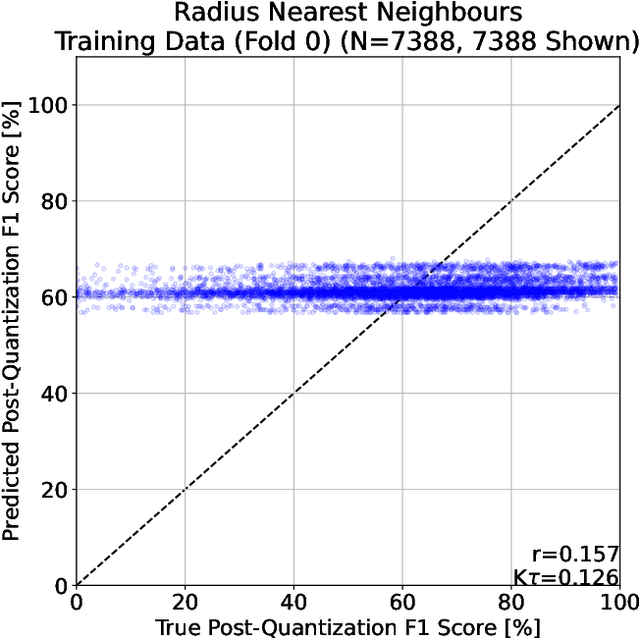


This paper showcases the use of a reinforcement learning-based Neural Architecture Search (NAS) agent to design a small neural network to perform active fire detection on multispectral satellite imagery. Specifically, we aim to design a neural network that can determine if a single multispectral pixel is a part of a fire, and do so within the constraints of a Low Earth Orbit (LEO) nanosatellite with a limited power budget, to facilitate on-board processing of sensor data. In order to use reinforcement learning, a reward function is needed. We supply this reward function in the shape of a regression model that predicts the F1 score obtained by a particular architecture, following quantization to INT8 precision, from purely architectural features. This model is trained by collecting a random sample of neural network architectures, training these architectures, and collecting their classification performance statistics. Besides the F1 score, we also include the total number of trainable parameters in our reward function to limit the size of the designed model and ensure it fits within the resource constraints imposed by nanosatellite platforms. Finally, we deployed the best neural network to the Google Coral Micro Dev Board and evaluated its inference latency and power consumption. This neural network consists of 1,716 trainable parameters, takes on average 984{\mu}s to inference, and consumes around 800mW to perform inference. These results show that our reinforcement learning-based NAS approach can be successfully applied to novel problems not tackled before.
Improving classification of road surface conditions via road area extraction and contrastive learning
Jul 19, 2024Maintaining roads is crucial to economic growth and citizen well-being because roads are a vital means of transportation. In various countries, the inspection of road surfaces is still done manually, however, to automate it, research interest is now focused on detecting the road surface defects via the visual data. While, previous research has been focused on deep learning methods which tend to process the entire image and leads to heavy computational cost. In this study, we focus our attention on improving the classification performance while keeping the computational cost of our solution low. Instead of processing the whole image, we introduce a segmentation model to only focus the downstream classification model to the road surface in the image. Furthermore, we employ contrastive learning during model training to improve the road surface condition classification. Our experiments on the public RTK dataset demonstrate a significant improvement in our proposed method when compared to previous works.
Data selection method for assessment of autonomous vehicles
Jul 16, 2024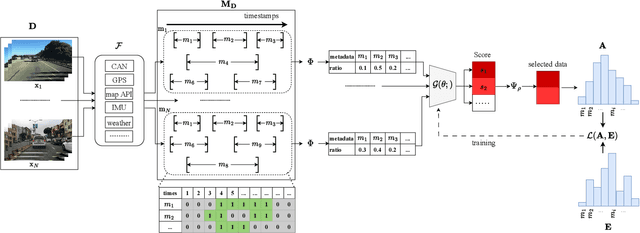
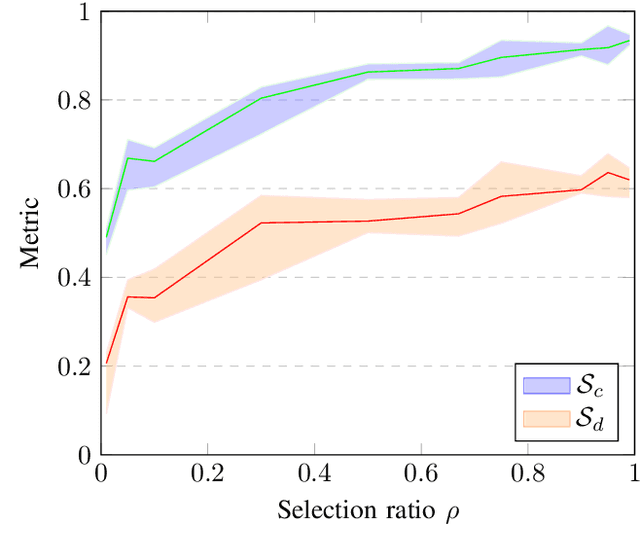

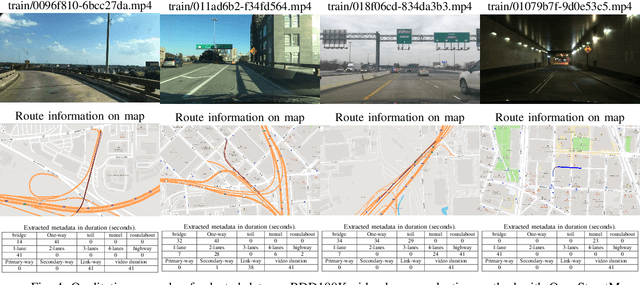
As the popularity of autonomous vehicles has grown, many standards and regulators, such as ISO, NHTSA, and Euro NCAP, require safety validation to ensure a sufficient level of safety before deploying them in the real world. Manufacturers gather a large amount of public road data for this purpose. However, the majority of these validation activities are done manually by humans. Furthermore, the data used to validate each driving feature may differ. As a result, it is essential to have an efficient data selection method that can be used flexibly and dynamically for verification and validation while also accelerating the validation process. In this paper, we present a data selection method that is practical, flexible, and efficient for assessment of autonomous vehicles. Our idea is to optimize the similarity between the metadata distribution of the selected data and a predefined metadata distribution that is expected for validation. Our experiments on the large dataset BDD100K show that our method can perform data selection tasks efficiently. These results demonstrate that our methods are highly reliable and can be used to select appropriate data for the validation of various safety functions.
Multiple data sources and domain generalization learning method for road surface defect classification
Jul 14, 2024



Roads are an essential mode of transportation, and maintaining them is critical to economic growth and citizen well-being. With the continued advancement of AI, road surface inspection based on camera images has recently been extensively researched and can be performed automatically. However, because almost all of the deep learning methods for detecting road surface defects were optimized for a specific dataset, they are difficult to apply to a new, previously unseen dataset. Furthermore, there is a lack of research on training an efficient model using multiple data sources. In this paper, we propose a method for classifying road surface defects using camera images. In our method, we propose a scheme for dealing with the invariance of multiple data sources while training a model on multiple data sources. Furthermore, we present a domain generalization training algorithm for developing a generalized model that can work with new, completely unseen data sources without requiring model updates. We validate our method using an experiment with six data sources corresponding to six countries from the RDD2022 dataset. The results show that our method can efficiently classify road surface defects on previously unseen data.