 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-attentive Transformer for Fast and Accurate Postprocessing of Temperature and Wind Speed Forecasts
Dec 18, 2024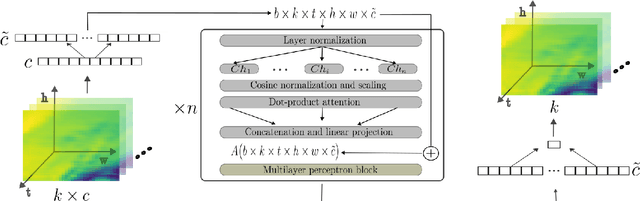
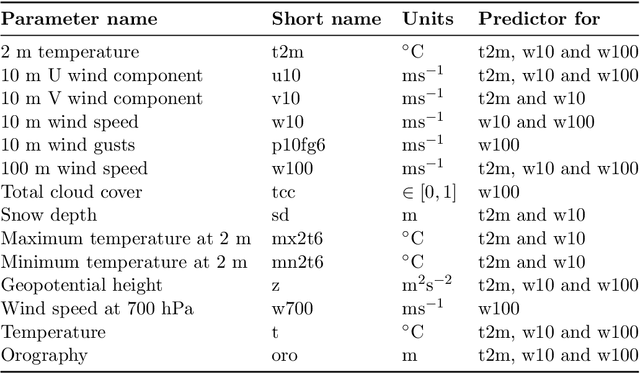
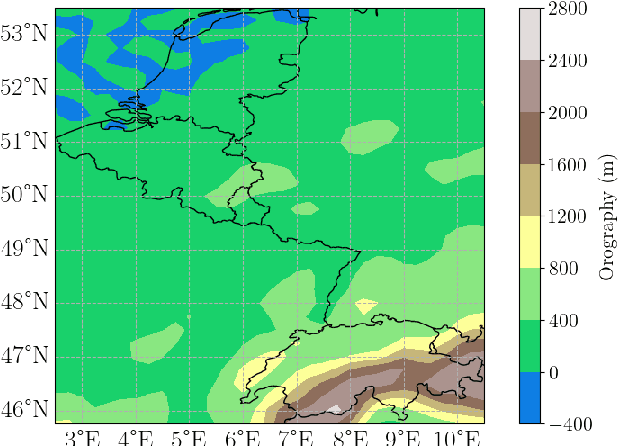

Current postprocessing techniques often require separate models for each lead time and disregard possible inter-ensemble relationships by either correcting each member separately or by employing distributional approaches. In this work, we tackle these shortcomings with an innovative, fast and accurate Transformer which postprocesses each ensemble member individually while allowing information exchange across variables, spatial dimensions and lead times by means of multi-headed self-attention. Weather foreacasts are postprocessed over 20 lead times simultaneously while including up to twelve meteorological predictors. We use the EUPPBench dataset for training which contains ensemble predictions from the European Center for Medium-range Weather Forecasts' integrated forecasting system alongside corresponding observations. The work presented here is the first to postprocess the ten and one hundred-meter wind speed forecasts within this benchmark dataset, while also correcting the two-meter temperature. Our approach significantly improves the original forecasts, as measured by the CRPS, with 17.5 % for two-meter temperature, nearly 5% for ten-meter wind speed and 5.3 % for one hundred-meter wind speed, outperforming a classical member-by-member approach employed as competitive benchmark. Furthermore, being up to 75 times faster, it fulfills the demand for rapid operational weather forecasts in various downstream applications, including renewable energy forecasting.
Safety Aware Autonomous Path Planning Using Model Predictive Reinforcement Learning for Inland Waterways
Nov 16, 2023In recent years, interest in autonomous shipping in urban waterways has increased significantly due to the trend of keeping cars and trucks out of city centers. Classical approaches such as Frenet frame based planning and potential field navigation often require tuning of many configuration parameters and sometimes even require a different configuration depending on the situation. In this paper, we propose a novel path planning approach based on reinforcement learning called Model Predictive Reinforcement Learning (MPRL). MPRL calculates a series of waypoints for the vessel to follow. The environment is represented as an occupancy grid map, allowing us to deal with any shape of waterway and any number and shape of obstacles. We demonstrate our approach on two scenarios and compare the resulting path with path planning using a Frenet frame and path planning based on a proximal policy optimization (PPO) agent. Our results show that MPRL outperforms both baselines in both test scenarios. The PPO based approach was not able to reach the goal in either scenario while the Frenet frame approach failed in the scenario consisting of a corner with obstacles. MPRL was able to safely (collision free) navigate to the goal in both of the test scenarios.
An In-Depth Analysis of Discretization Methods for Communication Learning using Backpropagation with Multi-Agent Reinforcement Learning
Aug 09, 2023Communication is crucial in multi-agent reinforcement learning when agents are not able to observe the full state of the environment. The most common approach to allow learned communication between agents is the use of a differentiable communication channel that allows gradients to flow between agents as a form of feedback. However, this is challenging when we want to use discrete messages to reduce the message size, since gradients cannot flow through a discrete communication channel. Previous work proposed methods to deal with this problem. However, these methods are tested in different communication learning architectures and environments, making it hard to compare them. In this paper, we compare several state-of-the-art discretization methods as well as a novel approach. We do this comparison in the context of communication learning using gradients from other agents and perform tests on several environments. In addition, we present COMA-DIAL, a communication learning approach based on DIAL and COMA extended with learning rate scaling and adapted exploration. Using COMA-DIAL allows us to perform experiments on more complex environments. Our results show that the novel ST-DRU method, proposed in this paper, achieves the best results out of all discretization methods across the different environments. It achieves the best or close to the best performance in each of the experiments and is the only method that does not fail on any of the tested environments.
Scalability of Message Encoding Techniques for Continuous Communication Learned with Multi-Agent Reinforcement Learning
Aug 09, 2023Many multi-agent systems require inter-agent communication to properly achieve their goal. By learning the communication protocol alongside the action protocol using multi-agent reinforcement learning techniques, the agents gain the flexibility to determine which information should be shared. However, when the number of agents increases we need to create an encoding of the information contained in these messages. In this paper, we investigate the effect of increasing the amount of information that should be contained in a message and increasing the number of agents. We evaluate these effects on two different message encoding methods, the mean message encoder and the attention message encoder. We perform our experiments on a matrix environment. Surprisingly, our results show that the mean message encoder consistently outperforms the attention message encoder. Therefore, we analyse the communication protocol used by the agents that use the mean message encoder and can conclude that the agents use a combination of an exponential and a logarithmic function in their communication policy to avoid the loss of important information after applying the mean message encoder.
Deep set conditioned latent representations for action recognition
Dec 21, 2022In recent years multi-label, multi-class video action recognition has gained significant popularity. While reasoning over temporally connected atomic actions is mundane for intelligent species, standard artificial neural networks (ANN) still struggle to classify them. In the real world, atomic actions often temporally connect to form more complex composite actions. The challenge lies in recognising composite action of varying durations while other distinct composite or atomic actions occur in the background. Drawing upon the success of relational networks, we propose methods that learn to reason over the semantic concept of objects and actions. We empirically show how ANNs benefit from pretraining, relational inductive biases and unordered set-based latent representations. In this paper we propose deep set conditioned I3D (SCI3D), a two stream relational network that employs latent representation of state and visual representation for reasoning over events and actions. They learn to reason about temporally connected actions in order to identify all of them in the video. The proposed method achieves an improvement of around 1.49% mAP in atomic action recognition and 17.57% mAP in composite action recognition, over a I3D-NL baseline, on the CATER dataset.
* Conference VISAPP 2022, 11 pages,5 figures, 2 Tables, 6 plots
An Analysis of Discretization Methods for Communication Learning with Multi-Agent Reinforcement Learning
Apr 12, 2022


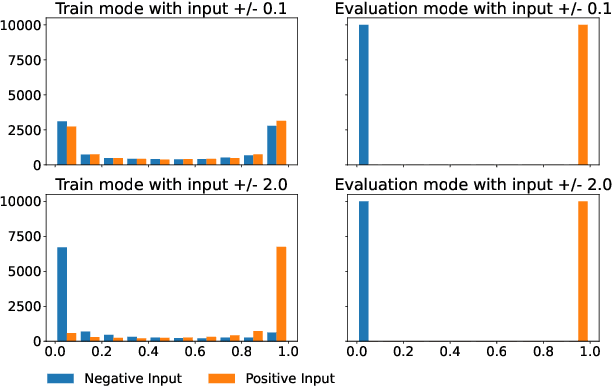
Communication is crucial in multi-agent reinforcement learning when agents are not able to observe the full state of the environment. The most common approach to allow learned communication between agents is the use of a differentiable communication channel that allows gradients to flow between agents as a form of feedback. However, this is challenging when we want to use discrete messages to reduce the message size since gradients cannot flow through a discrete communication channel. Previous work proposed methods to deal with this problem. However, these methods are tested in different communication learning architectures and environments, making it hard to compare them. In this paper, we compare several state-of-the-art discretization methods as well as two methods that have not been used for communication learning before. We do this comparison in the context of communication learning using gradients from other agents and perform tests on several environments. Our results show that none of the methods is best in all environments. The best choice in discretization method greatly depends on the environment. However, the discretize regularize unit (DRU), straight through DRU and the straight through gumbel softmax show the most consistent results across all the tested environments. Therefore, these methods prove to be the best choice for general use while the straight through estimator and the gumbel softmax may provide better results in specific environments but fail completely in others.
Learning to Communicate with Reinforcement Learning for an Adaptive Traffic Control System
Oct 29, 2021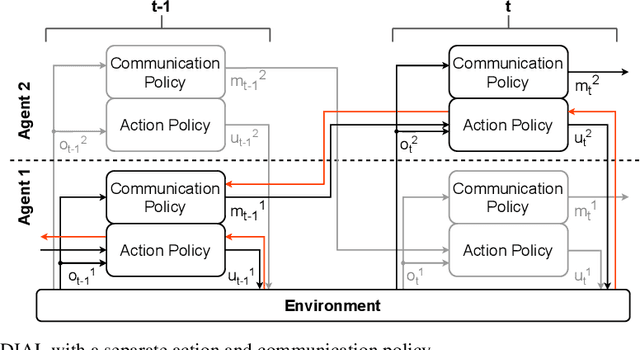


Recent work in multi-agent reinforcement learning has investigated inter agent communication which is learned simultaneously with the action policy in order to improve the team reward. In this paper, we investigate independent Q-learning (IQL) without communication and differentiable inter-agent learning (DIAL) with learned communication on an adaptive traffic control system (ATCS). In real world ATCS, it is impossible to present the full state of the environment to every agent so in our simulation, the individual agents will only have a limited observation of the full state of the environment. The ATCS will be simulated using the Simulation of Urban MObility (SUMO) traffic simulator in which two connected intersections are simulated. Every intersection is controlled by an agent which has the ability to change the direction of the traffic flow. Our results show that a DIAL agent outperforms an independent Q-learner on both training time and on maximum achieved reward as it is able to share relevant information with the other agents.
Mixed Cooperative-Competitive Communication Using Multi-Agent Reinforcement Learning
Oct 29, 2021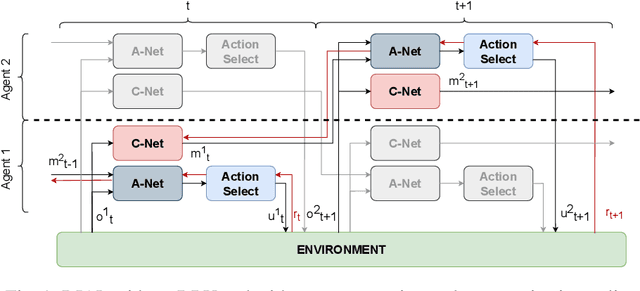
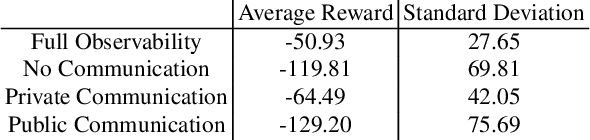


By using communication between multiple agents in multi-agent environments, one can reduce the effects of partial observability by combining one agent's observation with that of others in the same dynamic environment. While a lot of successful research has been done towards communication learning in cooperative settings, communication learning in mixed cooperative-competitive settings is also important and brings its own complexities such as the opposing team overhearing the communication. In this paper, we apply differentiable inter-agent learning (DIAL), designed for cooperative settings, to a mixed cooperative-competitive setting. We look at the difference in performance between communication that is private for a team and communication that can be overheard by the other team. Our research shows that communicating agents are able to achieve similar performance to fully observable agents after a given training period in our chosen environment. Overall, we find that sharing communication across teams results in decreased performance for the communicating team in comparison to results achieved with private communication.
A Review of the Deep Sea Treasure problem as a Multi-Objective Reinforcement Learning Benchmark
Oct 26, 2021


In this paper, the authors investigate the Deep Sea Treasure (DST) problem as proposed by Vamplew et al. Through a number of proofs, the authors show the original DST problem to be quite basic, and not always representative of practical Multi-Objective Optimization problems. In an attempt to bring theory closer to practice, the authors propose an alternative, improved version of the DST problem, and prove that some of the properties that simplify the original DST problem no longer hold. The authors also provide a reference implementation and perform a comparison between their implementation, and other existing open-source implementations of the problem. Finally, the authors also provide a complete Pareto-front for their new DST problem.
Exploiting non-i.i.d. data towards more robust machine learning algorithms
Oct 07, 2020



In the field of machine learning there is a growing interest towards more robust and generalizable algorithms. This is for example important to bridge the gap between the environment in which the training data was collected and the environment where the algorithm is deployed. Machine learning algorithms have increasingly been shown to excel in finding patterns and correlations from data. Determining the consistency of these patterns and for example the distinction between causal correlations and nonsensical spurious relations has proven to be much more difficult. In this paper a regularization scheme is introduced that prefers universal causal correlations. This approach is based on 1) the robustness of causal correlations and 2) the data not being independently and identically distribute (i.i.d.). The scheme is demonstrated with a classification task by clustering the (non-i.i.d.) training set in subpopulations. A non-i.i.d. regularization term is then introduced that penalizes weights that are not invariant over these clusters. The resulting algorithm favours correlations that are universal over the subpopulations and indeed a better performance is obtained on an out-of-distribution test set with respect to a more conventional l_2-regularization.