 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwin Network Augmentation: A Novel Training Strategy for Improved Spiking Neural Networks and Efficient Weight Quantization
Sep 24, 2024



The proliferation of Artificial Neural Networks (ANNs) has led to increased energy consumption, raising concerns about their sustainability. Spiking Neural Networks (SNNs), which are inspired by biological neural systems and operate using sparse, event-driven spikes to communicate information between neurons, offer a potential solution due to their lower energy requirements. An alternative technique for reducing a neural network's footprint is quantization, which compresses weight representations to decrease memory usage and energy consumption. In this study, we present Twin Network Augmentation (TNA), a novel training framework aimed at improving the performance of SNNs while also facilitating an enhanced compression through low-precision quantization of weights. TNA involves co-training an SNN with a twin network, optimizing both networks to minimize their cross-entropy losses and the mean squared error between their output logits. We demonstrate that TNA significantly enhances classification performance across various vision datasets and in addition is particularly effective when applied when reducing SNNs to ternary weight precision. Notably, during inference , only the ternary SNN is retained, significantly reducing the network in number of neurons, connectivity and weight size representation. Our results show that TNA outperforms traditional knowledge distillation methods and achieves state-of-the-art performance for the evaluated network architecture on benchmark datasets, including CIFAR-10, CIFAR-100, and CIFAR-10-DVS. This paper underscores the effectiveness of TNA in bridging the performance gap between SNNs and ANNs and suggests further exploration into the application of TNA in different network architectures and datasets.
Inferring the relationship between soil temperature and the normalized difference vegetation index with machine learning
Dec 19, 2023



Changes in climate can greatly affect the phenology of plants, which can have important feedback effects, such as altering the carbon cycle. These phenological feedback effects are often induced by a shift in the start or end dates of the growing season of plants. The normalized difference vegetation index (NDVI) serves as a straightforward indicator for assessing the presence of green vegetation and can also provide an estimation of the plants' growing season. In this study, we investigated the effect of soil temperature on the timing of the start of the season (SOS), timing of the peak of the season (POS), and the maximum annual NDVI value (PEAK) in subarctic grassland ecosystems between 2014 and 2019. We also explored the impact of other meteorological variables, including air temperature, precipitation, and irradiance, on the inter-annual variation in vegetation phenology. Using machine learning (ML) techniques and SHapley Additive exPlanations (SHAP) values, we analyzed the relative importance and contribution of each variable to the phenological predictions. Our results reveal a significant relationship between soil temperature and SOS and POS, indicating that higher soil temperatures lead to an earlier start and peak of the growing season. However, the Peak NDVI values showed just a slight increase with higher soil temperatures. The analysis of other meteorological variables demonstrated their impacts on the inter-annual variation of the vegetation phenology. Ultimately, this study contributes to our knowledge of the relationships between soil temperature, meteorological variables, and vegetation phenology, providing valuable insights for predicting vegetation phenology characteristics and managing subarctic grasslands in the face of climate change. Additionally, this work provides a solid foundation for future ML-based vegetation phenology studies.
An Encoding Framework for Binarized Images using HyperDimensional Computing
Dec 01, 2023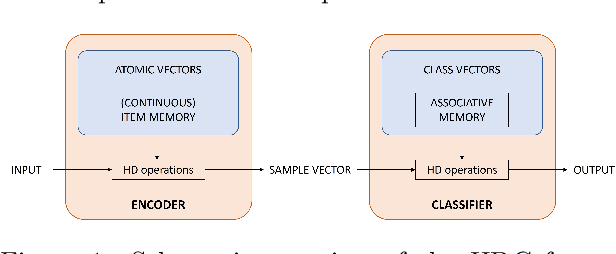



Hyperdimensional Computing (HDC) is a brain-inspired and light-weight machine learning method. It has received significant attention in the literature as a candidate to be applied in the wearable internet of things, near-sensor artificial intelligence applications and on-device processing. HDC is computationally less complex than traditional deep learning algorithms and typically achieves moderate to good classification performance. A key aspect that determines the performance of HDC is the encoding of the input data to the hyperdimensional (HD) space. This article proposes a novel light-weight approach relying only on native HD arithmetic vector operations to encode binarized images that preserves similarity of patterns at nearby locations by using point of interest selection and local linear mapping. The method reaches an accuracy of 97.35% on the test set for the MNIST data set and 84.12% for the Fashion-MNIST data set. These results outperform other studies using baseline HDC with different encoding approaches and are on par with more complex hybrid HDC models. The proposed encoding approach also demonstrates a higher robustness to noise and blur compared to the baseline encoding.
Structured Exploration Through Instruction Enhancement for Object Navigation
Nov 15, 2022



Finding an object of a specific class in an unseen environment remains an unsolved navigation problem. Hence, we propose a hierarchical learning-based method for object navigation. The top-level is capable of high-level planning, and building a memory on a floorplan-level (e.g., which room makes the most sense for the agent to visit next, where has the agent already been?). While the lower-level is tasked with efficiently navigating between rooms and looking for objects in them. Instructions can be provided to the agent using a simple synthetic language. The top-level intelligently enhances the instructions in order to make the overall task more tractable. Language grounding, mapping instructions to visual observations, is performed by utilizing an additional separate supervised trained goal assessment module. We demonstrate the effectiveness of our method on a dynamic configurable domestic environment.
An Analysis of Discretization Methods for Communication Learning with Multi-Agent Reinforcement Learning
Apr 12, 2022


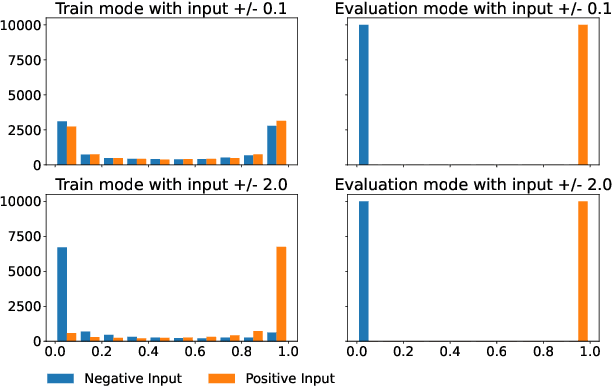
Communication is crucial in multi-agent reinforcement learning when agents are not able to observe the full state of the environment. The most common approach to allow learned communication between agents is the use of a differentiable communication channel that allows gradients to flow between agents as a form of feedback. However, this is challenging when we want to use discrete messages to reduce the message size since gradients cannot flow through a discrete communication channel. Previous work proposed methods to deal with this problem. However, these methods are tested in different communication learning architectures and environments, making it hard to compare them. In this paper, we compare several state-of-the-art discretization methods as well as two methods that have not been used for communication learning before. We do this comparison in the context of communication learning using gradients from other agents and perform tests on several environments. Our results show that none of the methods is best in all environments. The best choice in discretization method greatly depends on the environment. However, the discretize regularize unit (DRU), straight through DRU and the straight through gumbel softmax show the most consistent results across all the tested environments. Therefore, these methods prove to be the best choice for general use while the straight through estimator and the gumbel softmax may provide better results in specific environments but fail completely in others.
Learning to Communicate with Reinforcement Learning for an Adaptive Traffic Control System
Oct 29, 2021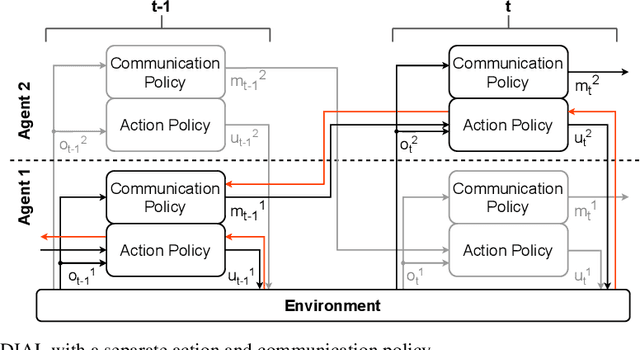


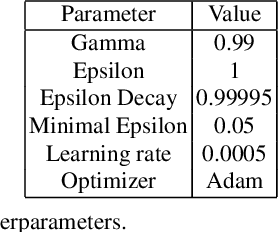
Recent work in multi-agent reinforcement learning has investigated inter agent communication which is learned simultaneously with the action policy in order to improve the team reward. In this paper, we investigate independent Q-learning (IQL) without communication and differentiable inter-agent learning (DIAL) with learned communication on an adaptive traffic control system (ATCS). In real world ATCS, it is impossible to present the full state of the environment to every agent so in our simulation, the individual agents will only have a limited observation of the full state of the environment. The ATCS will be simulated using the Simulation of Urban MObility (SUMO) traffic simulator in which two connected intersections are simulated. Every intersection is controlled by an agent which has the ability to change the direction of the traffic flow. Our results show that a DIAL agent outperforms an independent Q-learner on both training time and on maximum achieved reward as it is able to share relevant information with the other agents.
Mixed Cooperative-Competitive Communication Using Multi-Agent Reinforcement Learning
Oct 29, 2021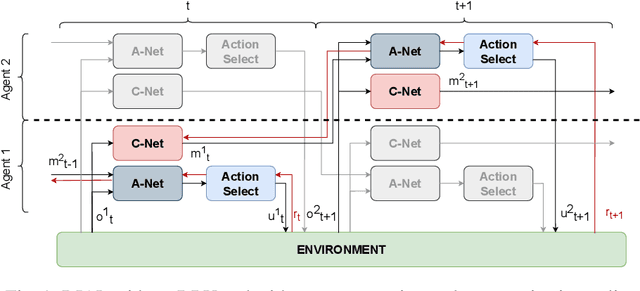
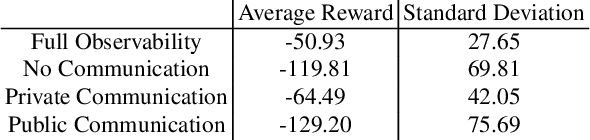


By using communication between multiple agents in multi-agent environments, one can reduce the effects of partial observability by combining one agent's observation with that of others in the same dynamic environment. While a lot of successful research has been done towards communication learning in cooperative settings, communication learning in mixed cooperative-competitive settings is also important and brings its own complexities such as the opposing team overhearing the communication. In this paper, we apply differentiable inter-agent learning (DIAL), designed for cooperative settings, to a mixed cooperative-competitive setting. We look at the difference in performance between communication that is private for a team and communication that can be overheard by the other team. Our research shows that communicating agents are able to achieve similar performance to fully observable agents after a given training period in our chosen environment. Overall, we find that sharing communication across teams results in decreased performance for the communicating team in comparison to results achieved with private communication.
A Review of the Deep Sea Treasure problem as a Multi-Objective Reinforcement Learning Benchmark
Oct 26, 2021


In this paper, the authors investigate the Deep Sea Treasure (DST) problem as proposed by Vamplew et al. Through a number of proofs, the authors show the original DST problem to be quite basic, and not always representative of practical Multi-Objective Optimization problems. In an attempt to bring theory closer to practice, the authors propose an alternative, improved version of the DST problem, and prove that some of the properties that simplify the original DST problem no longer hold. The authors also provide a reference implementation and perform a comparison between their implementation, and other existing open-source implementations of the problem. Finally, the authors also provide a complete Pareto-front for their new DST problem.
Neural Additive Vector Autoregression Models for Causal Discovery in Time Series Data
Oct 19, 2020

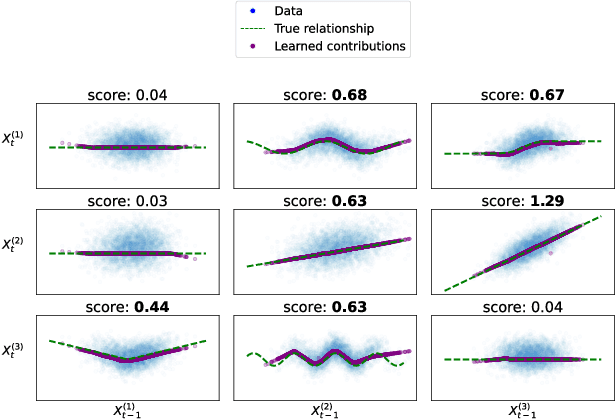

Causal structure discovery in complex dynamical systems is an important challenge for many scientific domains. Although data from (interventional) experiments is usually limited, large amounts of observational time series data sets are usually available. Current methods that learn causal structure from time series often assume linear relationships. Hence, they may fail in realistic settings that contain nonlinear relations between the variables. We propose Neural Additive Vector Autoregression (NAVAR) models, a neural approach to causal structure learning that can discover nonlinear relationships. We train deep neural networks that extract the (additive) Granger causal influences from the time evolution in multi-variate time series. The method achieves state-of-the-art results on various benchmark data sets for causal discovery, while providing clear interpretations of the mapped causal relations.
HTMRL: Biologically Plausible Reinforcement Learning with Hierarchical Temporal Memory
Sep 18, 2020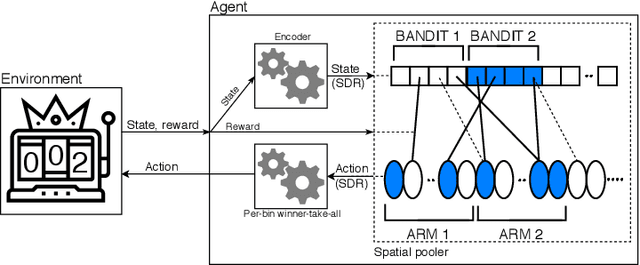
Building Reinforcement Learning (RL) algorithms which are able to adapt to continuously evolving tasks is an open research challenge. One technology that is known to inherently handle such non-stationary input patterns well is Hierarchical Temporal Memory (HTM), a general and biologically plausible computational model for the human neocortex. As the RL paradigm is inspired by human learning, HTM is a natural framework for an RL algorithm supporting non-stationary environments. In this paper, we present HTMRL, the first strictly HTM-based RL algorithm. We empirically and statistically show that HTMRL scales to many states and actions, and demonstrate that HTM's ability for adapting to changing patterns extends to RL. Specifically, HTMRL performs well on a 10-armed bandit after 750 steps, but only needs a third of that to adapt to the bandit suddenly shuffling its arms. HTMRL is the first iteration of a novel RL approach, with the potential of extending to a capable algorithm for Meta-RL.