 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances in Continual Graph Learning for Anti-Money Laundering Systems: A Comprehensive Review
Mar 31, 2025Financial institutions are required by regulation to report suspicious financial transactions related to money laundering. Therefore, they need to constantly monitor vast amounts of incoming and outgoing transactions. A particular challenge in detecting money laundering is that money launderers continuously adapt their tactics to evade detection. Hence, detection methods need constant fine-tuning. Traditional machine learning models suffer from catastrophic forgetting when fine-tuning the model on new data, thereby limiting their effectiveness in dynamic environments. Continual learning methods may address this issue and enhance current anti-money laundering (AML) practices, by allowing models to incorporate new information while retaining prior knowledge. Research on continual graph learning for AML, however, is still scarce. In this review, we critically evaluate state-of-the-art continual graph learning approaches for AML applications. We categorise methods into replay-based, regularization-based, and architecture-based strategies within the graph neural network (GNN) framework, and we provide in-depth experimental evaluations on both synthetic and real-world AML data sets that showcase the effect of the different hyperparameters. Our analysis demonstrates that continual learning improves model adaptability and robustness in the face of extreme class imbalances and evolving fraud patterns. Finally, we outline key challenges and propose directions for future research.
Task Adaptation of Reinforcement Learning-based NAS Agents through Transfer Learning
Dec 02, 2024Recently, a novel paradigm has been proposed for reinforcement learning-based NAS agents, that revolves around the incremental improvement of a given architecture. We assess the abilities of such reinforcement learning agents to transfer between different tasks. We perform our evaluation using the Trans-NASBench-101 benchmark, and consider the efficacy of the transferred agents, as well as how quickly they can be trained. We find that pretraining an agent on one task benefits the performance of the agent in another task in all but 1 task when considering final performance. We also show that the training procedure for an agent can be shortened significantly by pretraining it on another task. Our results indicate that these effects occur regardless of the source or target task, although they are more pronounced for some tasks than for others. Our results show that transfer learning can be an effective tool in mitigating the computational cost of the initial training procedure for reinforcement learning-based NAS agents.
Designing a Classifier for Active Fire Detection from Multispectral Satellite Imagery Using Neural Architecture Search
Oct 07, 2024
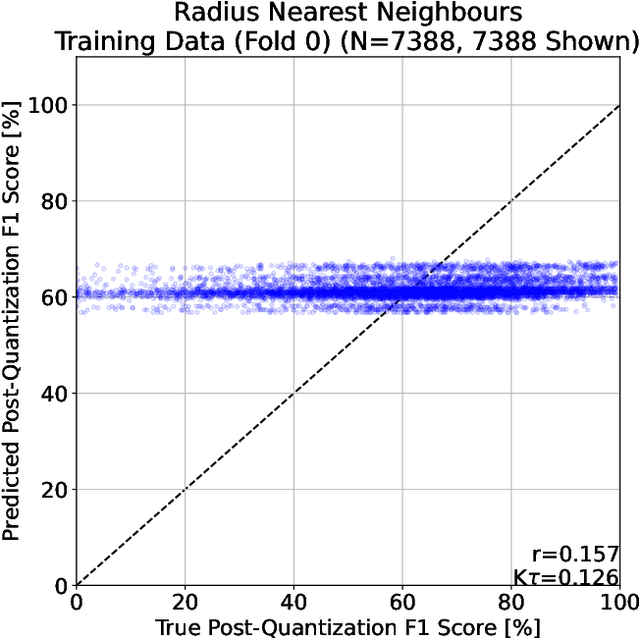


This paper showcases the use of a reinforcement learning-based Neural Architecture Search (NAS) agent to design a small neural network to perform active fire detection on multispectral satellite imagery. Specifically, we aim to design a neural network that can determine if a single multispectral pixel is a part of a fire, and do so within the constraints of a Low Earth Orbit (LEO) nanosatellite with a limited power budget, to facilitate on-board processing of sensor data. In order to use reinforcement learning, a reward function is needed. We supply this reward function in the shape of a regression model that predicts the F1 score obtained by a particular architecture, following quantization to INT8 precision, from purely architectural features. This model is trained by collecting a random sample of neural network architectures, training these architectures, and collecting their classification performance statistics. Besides the F1 score, we also include the total number of trainable parameters in our reward function to limit the size of the designed model and ensure it fits within the resource constraints imposed by nanosatellite platforms. Finally, we deployed the best neural network to the Google Coral Micro Dev Board and evaluated its inference latency and power consumption. This neural network consists of 1,716 trainable parameters, takes on average 984{\mu}s to inference, and consumes around 800mW to perform inference. These results show that our reinforcement learning-based NAS approach can be successfully applied to novel problems not tackled before.
Dataset Condensation with Latent Quantile Matching
Jun 14, 2024Dataset condensation (DC) methods aim to learn a smaller synthesized dataset with informative data records to accelerate the training of machine learning models. Current distribution matching (DM) based DC methods learn a synthesized dataset by matching the mean of the latent embeddings between the synthetic and the real dataset. However two distributions with the same mean can still be vastly different. In this work we demonstrate the shortcomings of using Maximum Mean Discrepancy to match latent distributions i.e. the weak matching power and lack of outlier regularization. To alleviate these shortcomings we propose our new method: Latent Quantile Matching (LQM) which matches the quantiles of the latent embeddings to minimize the goodness of fit test statistic between two distributions. Empirical experiments on both image and graph-structured datasets show that LQM matches or outperforms previous state of the art in distribution matching based DC. Moreover we show that LQM improves the performance in continual graph learning (CGL) setting where memory efficiency and privacy can be important. Our work sheds light on the application of DM based DC for CGL.
Benchmarking Sensitivity of Continual Graph Learning for Skeleton-Based Action Recognition
Jan 31, 2024

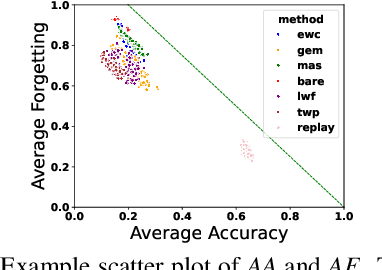

Continual learning (CL) is the research field that aims to build machine learning models that can accumulate knowledge continuously over different tasks without retraining from scratch. Previous studies have shown that pre-training graph neural networks (GNN) may lead to negative transfer (Hu et al., 2020) after fine-tuning, a setting which is closely related to CL. Thus, we focus on studying GNN in the continual graph learning (CGL) setting. We propose the first continual graph learning benchmark for spatio-temporal graphs and use it to benchmark well-known CGL methods in this novel setting. The benchmark is based on the N-UCLA and NTU-RGB+D datasets for skeleton-based action recognition. Beyond benchmarking for standard performance metrics, we study the class and task-order sensitivity of CGL methods, i.e., the impact of learning order on each class/task's performance, and the architectural sensitivity of CGL methods with backbone GNN at various widths and depths. We reveal that task-order robust methods can still be class-order sensitive and observe results that contradict previous empirical observations on architectural sensitivity in CL.
Safety Aware Autonomous Path Planning Using Model Predictive Reinforcement Learning for Inland Waterways
Nov 16, 2023In recent years, interest in autonomous shipping in urban waterways has increased significantly due to the trend of keeping cars and trucks out of city centers. Classical approaches such as Frenet frame based planning and potential field navigation often require tuning of many configuration parameters and sometimes even require a different configuration depending on the situation. In this paper, we propose a novel path planning approach based on reinforcement learning called Model Predictive Reinforcement Learning (MPRL). MPRL calculates a series of waypoints for the vessel to follow. The environment is represented as an occupancy grid map, allowing us to deal with any shape of waterway and any number and shape of obstacles. We demonstrate our approach on two scenarios and compare the resulting path with path planning using a Frenet frame and path planning based on a proximal policy optimization (PPO) agent. Our results show that MPRL outperforms both baselines in both test scenarios. The PPO based approach was not able to reach the goal in either scenario while the Frenet frame approach failed in the scenario consisting of a corner with obstacles. MPRL was able to safely (collision free) navigate to the goal in both of the test scenarios.
Scalability of Message Encoding Techniques for Continuous Communication Learned with Multi-Agent Reinforcement Learning
Aug 09, 2023Many multi-agent systems require inter-agent communication to properly achieve their goal. By learning the communication protocol alongside the action protocol using multi-agent reinforcement learning techniques, the agents gain the flexibility to determine which information should be shared. However, when the number of agents increases we need to create an encoding of the information contained in these messages. In this paper, we investigate the effect of increasing the amount of information that should be contained in a message and increasing the number of agents. We evaluate these effects on two different message encoding methods, the mean message encoder and the attention message encoder. We perform our experiments on a matrix environment. Surprisingly, our results show that the mean message encoder consistently outperforms the attention message encoder. Therefore, we analyse the communication protocol used by the agents that use the mean message encoder and can conclude that the agents use a combination of an exponential and a logarithmic function in their communication policy to avoid the loss of important information after applying the mean message encoder.
An In-Depth Analysis of Discretization Methods for Communication Learning using Backpropagation with Multi-Agent Reinforcement Learning
Aug 09, 2023Communication is crucial in multi-agent reinforcement learning when agents are not able to observe the full state of the environment. The most common approach to allow learned communication between agents is the use of a differentiable communication channel that allows gradients to flow between agents as a form of feedback. However, this is challenging when we want to use discrete messages to reduce the message size, since gradients cannot flow through a discrete communication channel. Previous work proposed methods to deal with this problem. However, these methods are tested in different communication learning architectures and environments, making it hard to compare them. In this paper, we compare several state-of-the-art discretization methods as well as a novel approach. We do this comparison in the context of communication learning using gradients from other agents and perform tests on several environments. In addition, we present COMA-DIAL, a communication learning approach based on DIAL and COMA extended with learning rate scaling and adapted exploration. Using COMA-DIAL allows us to perform experiments on more complex environments. Our results show that the novel ST-DRU method, proposed in this paper, achieves the best results out of all discretization methods across the different environments. It achieves the best or close to the best performance in each of the experiments and is the only method that does not fail on any of the tested environments.
Deep set conditioned latent representations for action recognition
Dec 21, 2022In recent years multi-label, multi-class video action recognition has gained significant popularity. While reasoning over temporally connected atomic actions is mundane for intelligent species, standard artificial neural networks (ANN) still struggle to classify them. In the real world, atomic actions often temporally connect to form more complex composite actions. The challenge lies in recognising composite action of varying durations while other distinct composite or atomic actions occur in the background. Drawing upon the success of relational networks, we propose methods that learn to reason over the semantic concept of objects and actions. We empirically show how ANNs benefit from pretraining, relational inductive biases and unordered set-based latent representations. In this paper we propose deep set conditioned I3D (SCI3D), a two stream relational network that employs latent representation of state and visual representation for reasoning over events and actions. They learn to reason about temporally connected actions in order to identify all of them in the video. The proposed method achieves an improvement of around 1.49% mAP in atomic action recognition and 17.57% mAP in composite action recognition, over a I3D-NL baseline, on the CATER dataset.
* Conference VISAPP 2022, 11 pages,5 figures, 2 Tables, 6 plots
Structured Exploration Through Instruction Enhancement for Object Navigation
Nov 15, 2022



Finding an object of a specific class in an unseen environment remains an unsolved navigation problem. Hence, we propose a hierarchical learning-based method for object navigation. The top-level is capable of high-level planning, and building a memory on a floorplan-level (e.g., which room makes the most sense for the agent to visit next, where has the agent already been?). While the lower-level is tasked with efficiently navigating between rooms and looking for objects in them. Instructions can be provided to the agent using a simple synthetic language. The top-level intelligently enhances the instructions in order to make the overall task more tractable. Language grounding, mapping instructions to visual observations, is performed by utilizing an additional separate supervised trained goal assessment module. We demonstrate the effectiveness of our method on a dynamic configurable domestic environment.