 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositionality Unlocks Deep Interpretable Models
Apr 03, 2025We propose $\chi$-net, an intrinsically interpretable architecture combining the compositional multilinear structure of tensor networks with the expressivity and efficiency of deep neural networks. $\chi$-nets retain equal accuracy compared to their baseline counterparts. Our novel, efficient diagonalisation algorithm, ODT, reveals linear low-rank structure in a multilayer SVHN model. We leverage this toward formal weight-based interpretability and model compression.
The Trifecta: Three simple techniques for training deeper Forward-Forward networks
Nov 29, 2023Modern machine learning models are able to outperform humans on a variety of non-trivial tasks. However, as the complexity of the models increases, they consume significant amounts of power and still struggle to generalize effectively to unseen data. Local learning, which focuses on updating subsets of a model's parameters at a time, has emerged as a promising technique to address these issues. Recently, a novel local learning algorithm, called Forward-Forward, has received widespread attention due to its innovative approach to learning. Unfortunately, its application has been limited to smaller datasets due to scalability issues. To this end, we propose The Trifecta, a collection of three simple techniques that synergize exceptionally well and drastically improve the Forward-Forward algorithm on deeper networks. Our experiments demonstrate that our models are on par with similarly structured, backpropagation-based models in both training speed and test accuracy on simple datasets. This is achieved by the ability to learn representations that are informative locally, on a layer-by-layer basis, and retain their informativeness when propagated to deeper layers in the architecture. This leads to around 84\% accuracy on CIFAR-10, a notable improvement (25\%) over the original FF algorithm. These results highlight the potential of Forward-Forward as a genuine competitor to backpropagation and as a promising research avenue.
Considering Layerwise Importance in the Lottery Ticket Hypothesis
Feb 22, 2023



The Lottery Ticket Hypothesis (LTH) showed that by iteratively training a model, removing connections with the lowest global weight magnitude and rewinding the remaining connections, sparse networks can be extracted. This global comparison removes context information between connections within a layer. Here we study means for recovering some of this layer distributional context and generalise the LTH to consider weight importance values rather than global weight magnitudes. We find that given a repeatable training procedure, applying different importance metrics leads to distinct performant lottery tickets with little overlapping connections. This strongly suggests that lottery tickets are not unique
On The Coherence of Quantitative Evaluation of Visual Expalantion
Feb 14, 2023Recent years have shown an increased development of methods for justifying the predictions of neural networks through visual explanations. These explanations usually take the form of heatmaps which assign a saliency (or relevance) value to each pixel of the input image that expresses how relevant the pixel is for the prediction of a label. Complementing this development, evaluation methods have been proposed to assess the "goodness" of such explanations. On the one hand, some of these methods rely on synthetic datasets. However, this introduces the weakness of having limited guarantees regarding their applicability on more realistic settings. On the other hand, some methods rely on metrics for objective evaluation. However the level to which some of these evaluation methods perform with respect to each other is uncertain. Taking this into account, we conduct a comprehensive study on a subset of the ImageNet-1k validation set where we evaluate a number of different commonly-used explanation methods following a set of evaluation methods. We complement our study with sanity checks on the studied evaluation methods as a means to investigate their reliability and the impact of characteristics of the explanations on the evaluation methods. Results of our study suggest that there is a lack of coherency on the grading provided by some of the considered evaluation methods. Moreover, we have identified some characteristics of the explanations, e.g. sparsity, which can have a significant effect on the performance.
Deep set conditioned latent representations for action recognition
Dec 21, 2022In recent years multi-label, multi-class video action recognition has gained significant popularity. While reasoning over temporally connected atomic actions is mundane for intelligent species, standard artificial neural networks (ANN) still struggle to classify them. In the real world, atomic actions often temporally connect to form more complex composite actions. The challenge lies in recognising composite action of varying durations while other distinct composite or atomic actions occur in the background. Drawing upon the success of relational networks, we propose methods that learn to reason over the semantic concept of objects and actions. We empirically show how ANNs benefit from pretraining, relational inductive biases and unordered set-based latent representations. In this paper we propose deep set conditioned I3D (SCI3D), a two stream relational network that employs latent representation of state and visual representation for reasoning over events and actions. They learn to reason about temporally connected actions in order to identify all of them in the video. The proposed method achieves an improvement of around 1.49% mAP in atomic action recognition and 17.57% mAP in composite action recognition, over a I3D-NL baseline, on the CATER dataset.
* Conference VISAPP 2022, 11 pages,5 figures, 2 Tables, 6 plots
MinMaxCAM: Improving object coverage for CAM-basedWeakly Supervised Object Localization
Apr 29, 2021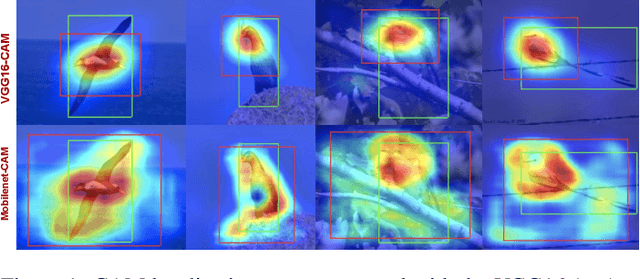
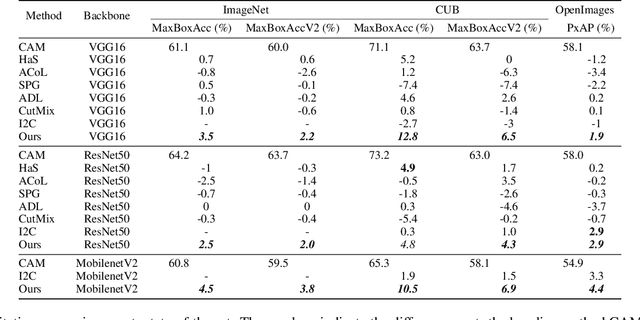
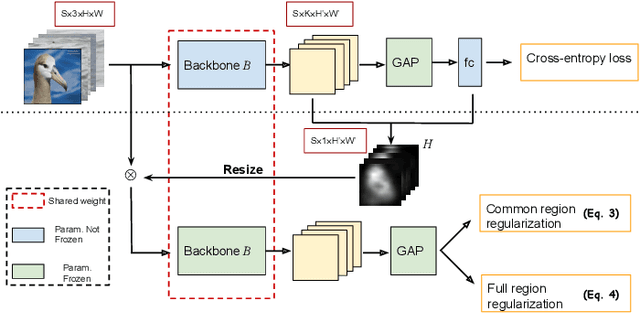
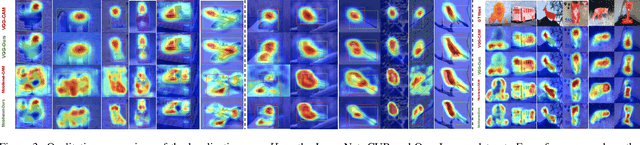
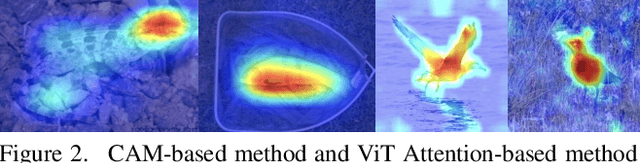
One of the most common problems of weakly supervised object localization is that of inaccurate object coverage. In the context of state-of-the-art methods based on Class Activation Mapping, this is caused either by localization maps which focus, exclusively, on the most discriminative region of the objects of interest or by activations occurring in background regions. To address these two problems, we propose two representation regularization mechanisms: Full Region Regularizationwhich tries to maximize the coverage of the localization map inside the object region, and Common Region Regularization which minimizes the activations occurring in background regions. We evaluate the two regularizations on the ImageNet, CUB-200-2011 and OpenImages-segmentation datasets, and show that the proposed regularizations tackle both problems, outperforming the state-of-the-art by a significant margin.
Towards Human-Understandable Visual Explanations:Imperceptible High-frequency Cues Can Better Be Removed
Apr 16, 2021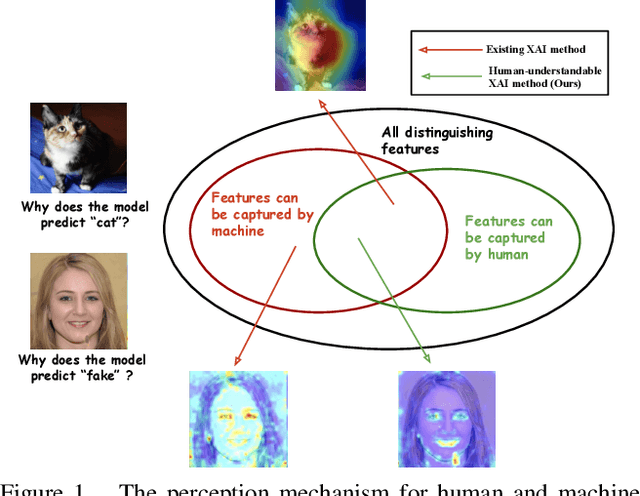


Explainable AI (XAI) methods focus on explaining what a neural network has learned - in other words, identifying the features that are the most influential to the prediction. In this paper, we call them "distinguishing features". However, whether a human can make sense of the generated explanation also depends on the perceptibility of these features to humans. To make sure an explanation is human-understandable, we argue that the capabilities of humans, constrained by the Human Visual System (HVS) and psychophysics, need to be taken into account. We propose the {\em human perceptibility principle for XAI}, stating that, to generate human-understandable explanations, neural networks should be steered towards focusing on human-understandable cues during training. We conduct a case study regarding the classification of real vs. fake face images, where many of the distinguishing features picked up by standard neural networks turn out not to be perceptible to humans. By applying the proposed principle, a neural network with human-understandable explanations is trained which, in a user study, is shown to better align with human intuition. This is likely to make the AI more trustworthy and opens the door to humans learning from machines. In the case study, we specifically investigate and analyze the behaviour of the human-imperceptible high spatial frequency features in neural networks and XAI methods.
Can the state of relevant neurons in a deep neural networks serve as indicators for detecting adversarial attacks?
Oct 29, 2020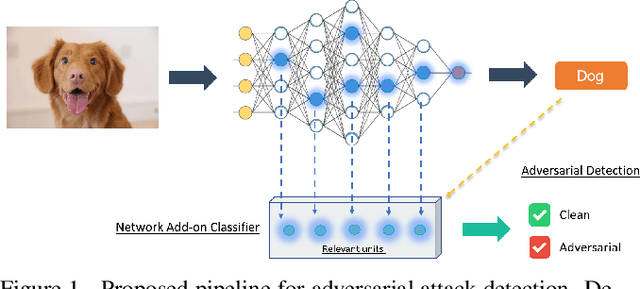
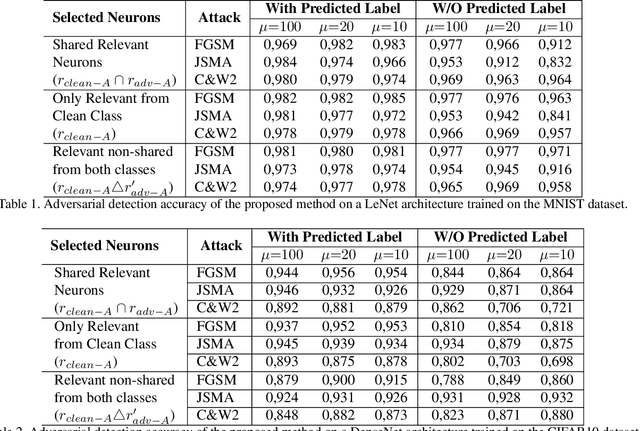
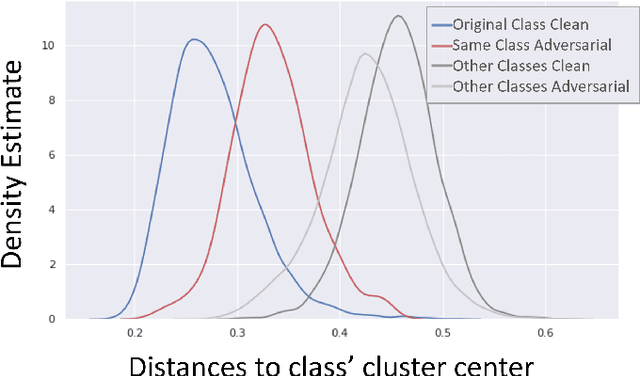
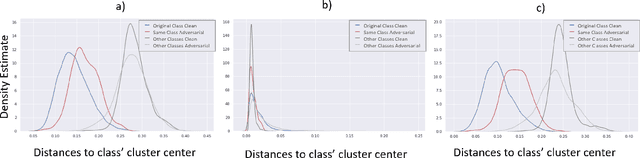
We present a method for adversarial attack detection based on the inspection of a sparse set of neurons. We follow the hypothesis that adversarial attacks introduce imperceptible perturbations in the input and that these perturbations change the state of neurons relevant for the concepts modelled by the attacked model. Therefore, monitoring the status of these neurons would enable the detection of adversarial attacks. Focusing on the image classification task, our method identifies neurons that are relevant for the classes predicted by the model. A deeper qualitative inspection of these sparse set of neurons indicates that their state changes in the presence of adversarial samples. Moreover, quantitative results from our empirical evaluation indicate that our method is capable of recognizing adversarial samples, produced by state-of-the-art attack methods, with comparable accuracy to that of state-of-the-art detectors.
Multiple Exemplars-based Hallucinationfor Face Super-resolution and Editing
Sep 17, 2020
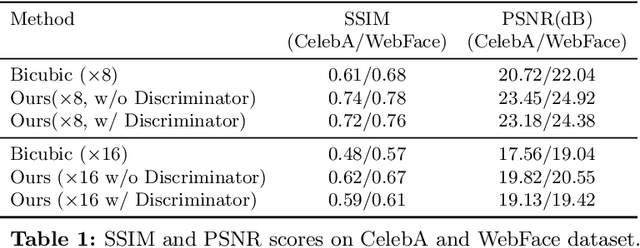
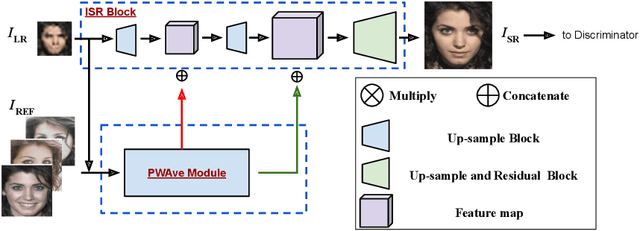

Given a really low-resolution input image of a face (say 16x16 or 8x8 pixels), the goal of this paper is to reconstruct a high-resolution version thereof. This, by itself, is an ill-posed problem, as the high-frequency information is missing in the low-resolution input and needs to be hallucinated, based on prior knowledge about the image content. Rather than relying on a generic face prior, in this paper, we explore the use of a set of exemplars, i.e. other high-resolution images of the same person. These guide the neural network as we condition the output on them. Multiple exemplars work better than a single one. To combine the information from multiple exemplars effectively, we introduce a pixel-wise weight generation module. Besides standard face super-resolution, our method allows to perform subtle face editing simply by replacing the exemplars with another set with different facial features. A user study is conducted and shows the super-resolved images can hardly be distinguished from real images on the CelebA dataset. A qualitative comparison indicates our model outperforms methods proposed in the literature on the CelebA and WebFace dataset.
Information Compensation for Deep Conditional Generative Networks
Jan 24, 2020
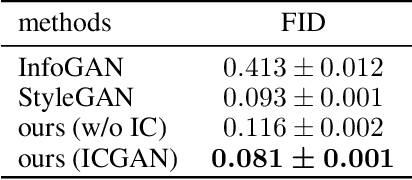
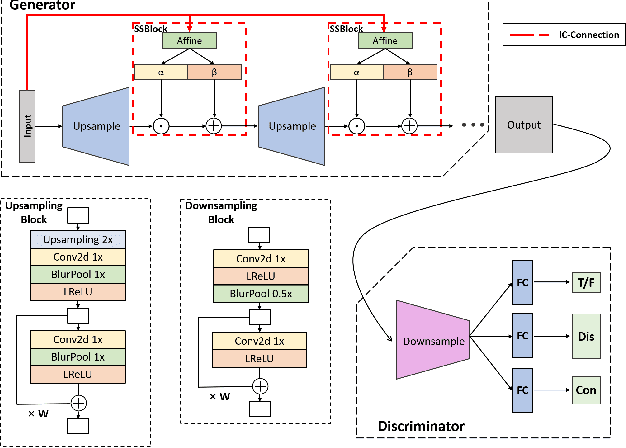
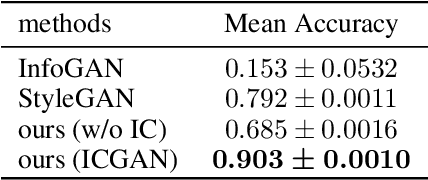
In recent years, unsupervised/weakly-supervised conditional generative adversarial networks (GANs) have achieved many successes on the task of modeling and generating data. However, one of their weaknesses lies in their poor ability to separate, or disentangle, the different factors that characterize the representation encoded in their latent space. To address this issue, we propose a novel structure for unsupervised conditional GANs powered by a novel Information Compensation Connection (IC-Connection). The proposed IC-Connection enables GANs to compensate for information loss incurred during deconvolution operations. In addition, to quantify the degree of disentanglement on both discrete and continuous latent variables, we design a novel evaluation procedure. Our empirical results suggest that our method achieves better disentanglement compared to the state-of-the-art GANs in a conditional generation setting.