 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Detail Bottlenecks in Latent Diffusion for RGB-to-SWIR Image Translation
Jun 18, 2026Latent diffusion models (LDMs) enable efficient image-to-image translation but discard fine spatial details during compression, degrading downstream perception tasks. We identify two bottlenecks: the autoencoder, which loses spatial information, and the conditioning pathway, which further degrades the source signal through naive downsampling. We propose two lightweight, backbone-agnostic fixes: a Source-Conditioned Autoencoder (SCAE) that injects high-resolution source features into the decoder via skip connections, and a Learnable Guidance Encoder (LGE) that replaces naive downsampling with a learned conditioning signal. Evaluated on RGB-to-SWIR translation for driving scenes with two denoiser backbones (U-Net and DiT), our approach improves detection mAP by up to 2x over the latent diffusion baseline, with up to 3.4x gains on small objects (COCO-small, <32^2 px^2), while achieving state-of-the-art FID. We further show that FID and detection performance are poorly correlated, motivating multi-axis evaluation. Results generalise zero-shot to the public RASMD benchmark. We will publicly release test data with annotations, all checkpoints, and training code.
DTIAM: A unified framework for predicting drug-target interactions, binding affinities and activation/inhibition mechanisms
Dec 23, 2023Accurate and robust prediction of drug-target interactions (DTIs) plays a vital role in drug discovery. Despite extensive efforts have been invested in predicting novel DTIs, existing approaches still suffer from insufficient labeled data and cold start problems. More importantly, there is currently a lack of studies focusing on elucidating the mechanism of action (MoA) between drugs and targets. Distinguishing the activation and inhibition mechanisms is critical and challenging in drug development. Here, we introduce a unified framework called DTIAM, which aims to predict interactions, binding affinities, and activation/inhibition mechanisms between drugs and targets. DTIAM learns drug and target representations from large amounts of label-free data through self-supervised pre-training, which accurately extracts the substructure and contextual information of drugs and targets, and thus benefits the downstream prediction based on these representations. DTIAM achieves substantial performance improvement over other state-of-the-art methods in all tasks, particularly in the cold start scenario. Moreover, independent validation demonstrates the strong generalization ability of DTIAM. All these results suggested that DTIAM can provide a practically useful tool for predicting novel DTIs and further distinguishing the MoA of candidate drugs. DTIAM, for the first time, provides a unified framework for accurate and robust prediction of drug-target interactions, binding affinities, and activation/inhibition mechanisms.
Modelling the Frequency of Home Deliveries: An Induced Travel Demand Contribution of Aggrandized E-shopping in Toronto during COVID-19 Pandemics
Sep 21, 2022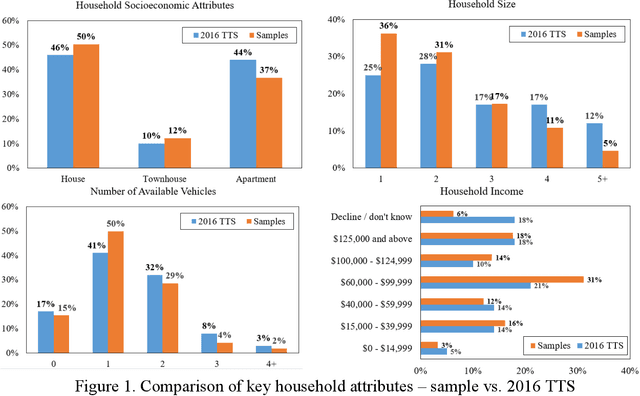


The COVID-19 pandemic dramatically catalyzed the proliferation of e-shopping. The dramatic growth of e-shopping will undoubtedly cause significant impacts on travel demand. As a result, transportation modeller's ability to model e-shopping demand is becoming increasingly important. This study developed models to predict household' weekly home delivery frequencies. We used both classical econometric and machine learning techniques to obtain the best model. It is found that socioeconomic factors such as having an online grocery membership, household members' average age, the percentage of male household members, the number of workers in the household and various land use factors influence home delivery demand. This study also compared the interpretations and performances of the machine learning models and the classical econometric model. Agreement is found in the variable's effects identified through the machine learning and econometric models. However, with similar recall accuracy, the ordered probit model, a classical econometric model, can accurately predict the aggregate distribution of household delivery demand. In contrast, both machine learning models failed to match the observed distribution.
Tutela: An Open-Source Tool for Assessing User-Privacy on Ethereum and Tornado Cash
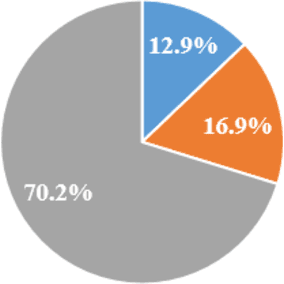
Jan 18, 2022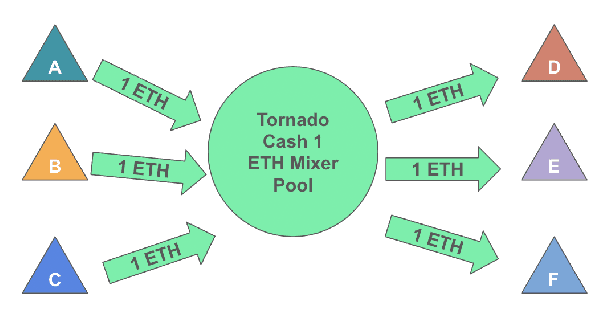
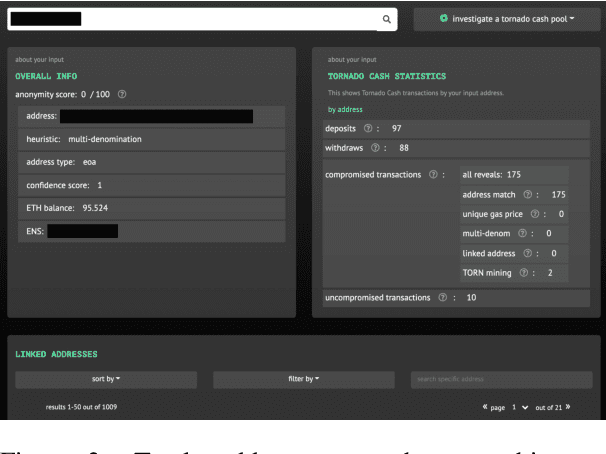
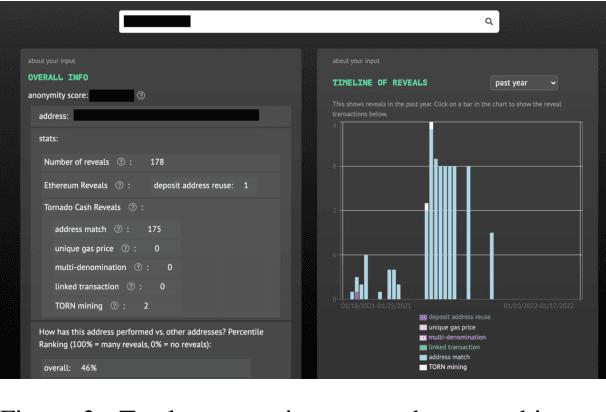
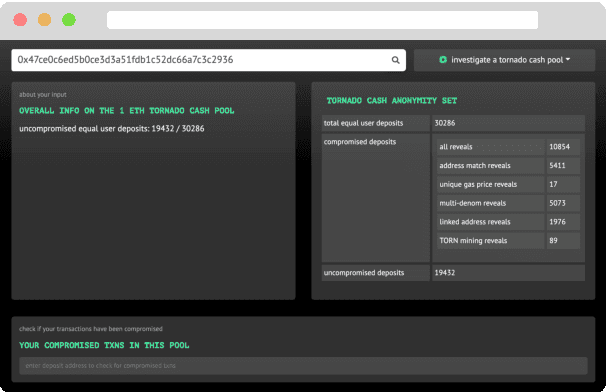
A common misconception among blockchain users is that pseudonymity guarantees privacy. The reality is almost the opposite. Every transaction one makes is recorded on a public ledger and reveals information about one's identity. Mixers, such as Tornado Cash, were developed to preserve privacy through "mixing" transactions with those of others in an anonymity pool, making it harder to link deposits and withdrawals from the pool. Unfortunately, it is still possible to reveal information about those in the anonymity pool if users are not careful. We introduce Tutela, an application built on expert heuristics to report the true anonymity of an Ethereum address. In particular, Tutela has three functionalities: first, it clusters together Ethereum addresses based on interaction history such that for an Ethereum address, we can identify other addresses likely owned by the same entity; second, it shows Ethereum users their potentially compromised transactions; third, Tutela computes the true size of the anonymity pool of each Tornado Cash mixer by excluding potentially compromised transactions. A public implementation of Tutela can be found at https://github.com/TutelaLabs/tutela-app. To use Tutela, visit https://www.tutela.xyz.
Audio-Visual Grounding Referring Expression for Robotic Manipulation
Sep 22, 2021
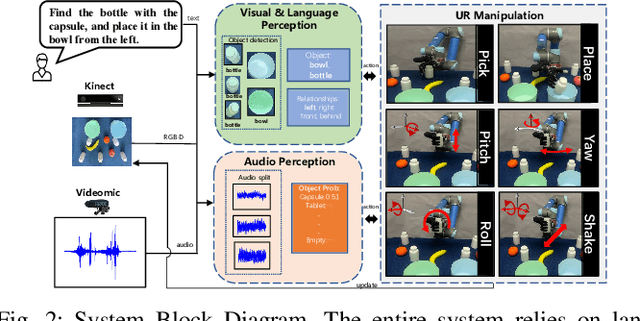
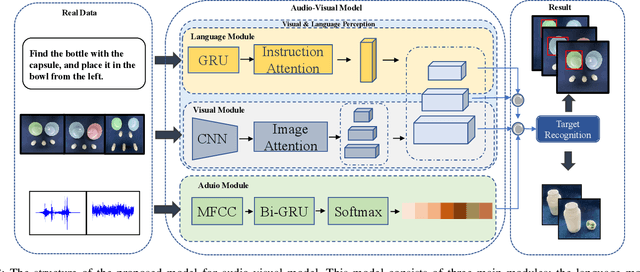

Referring expressions are commonly used when referring to a specific target in people's daily dialogue. In this paper, we develop a novel task of audio-visual grounding referring expression for robotic manipulation. The robot leverages both the audio and visual information to understand the referring expression in the given manipulation instruction and the corresponding manipulations are implemented. To solve the proposed task, an audio-visual framework is proposed for visual localization and sound recognition. We have also established a dataset which contains visual data, auditory data and manipulation instructions for evaluation. Finally, extensive experiments are conducted both offline and online to verify the effectiveness of the proposed audio-visual framework. And it is demonstrated that the robot performs better with the audio-visual data than with only the visual data.
MinMaxCAM: Improving object coverage for CAM-basedWeakly Supervised Object Localization
Apr 29, 2021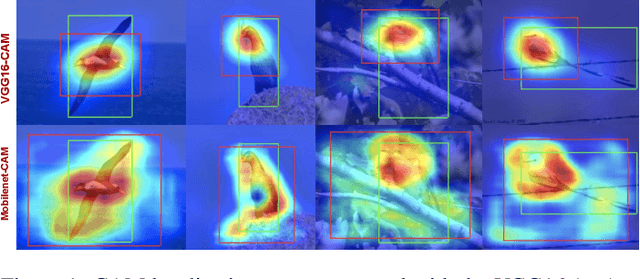
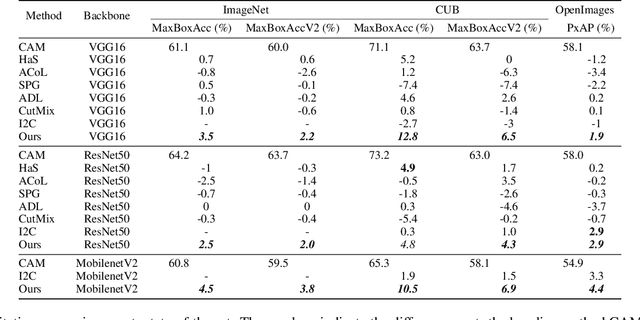
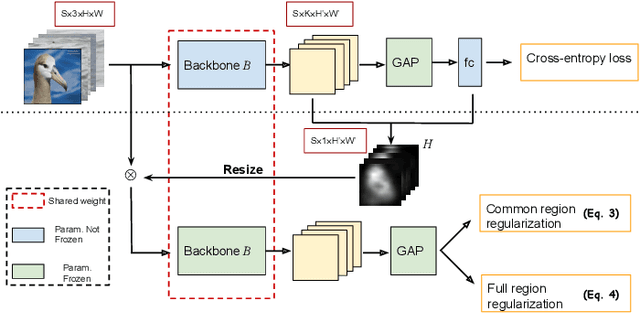
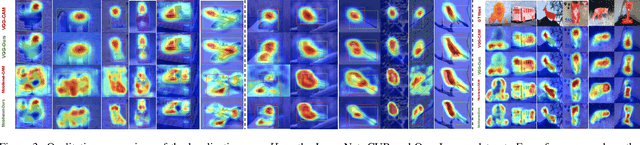
One of the most common problems of weakly supervised object localization is that of inaccurate object coverage. In the context of state-of-the-art methods based on Class Activation Mapping, this is caused either by localization maps which focus, exclusively, on the most discriminative region of the objects of interest or by activations occurring in background regions. To address these two problems, we propose two representation regularization mechanisms: Full Region Regularizationwhich tries to maximize the coverage of the localization map inside the object region, and Common Region Regularization which minimizes the activations occurring in background regions. We evaluate the two regularizations on the ImageNet, CUB-200-2011 and OpenImages-segmentation datasets, and show that the proposed regularizations tackle both problems, outperforming the state-of-the-art by a significant margin.
Towards Human-Understandable Visual Explanations:Imperceptible High-frequency Cues Can Better Be Removed
Apr 16, 2021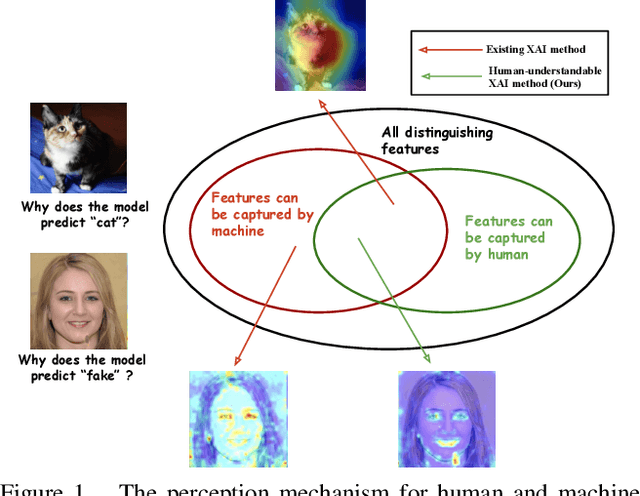

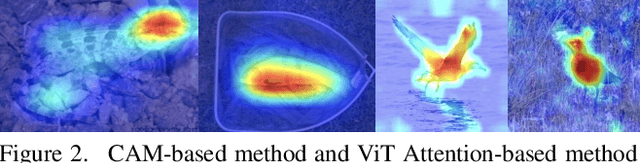

Explainable AI (XAI) methods focus on explaining what a neural network has learned - in other words, identifying the features that are the most influential to the prediction. In this paper, we call them "distinguishing features". However, whether a human can make sense of the generated explanation also depends on the perceptibility of these features to humans. To make sure an explanation is human-understandable, we argue that the capabilities of humans, constrained by the Human Visual System (HVS) and psychophysics, need to be taken into account. We propose the {\em human perceptibility principle for XAI}, stating that, to generate human-understandable explanations, neural networks should be steered towards focusing on human-understandable cues during training. We conduct a case study regarding the classification of real vs. fake face images, where many of the distinguishing features picked up by standard neural networks turn out not to be perceptible to humans. By applying the proposed principle, a neural network with human-understandable explanations is trained which, in a user study, is shown to better align with human intuition. This is likely to make the AI more trustworthy and opens the door to humans learning from machines. In the case study, we specifically investigate and analyze the behaviour of the human-imperceptible high spatial frequency features in neural networks and XAI methods.
Multiple Exemplars-based Hallucinationfor Face Super-resolution and Editing
Sep 17, 2020
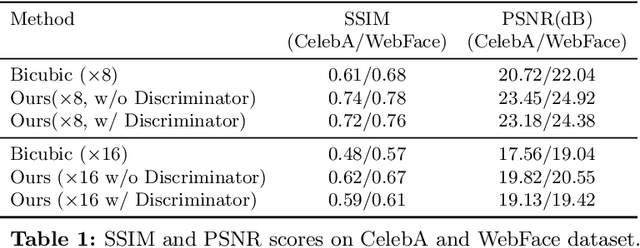
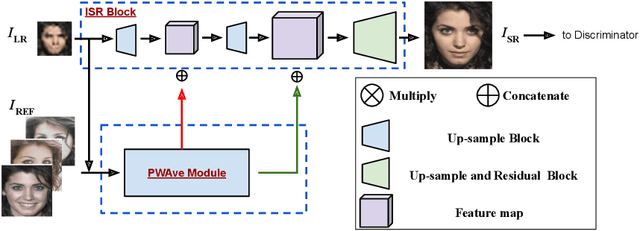

Given a really low-resolution input image of a face (say 16x16 or 8x8 pixels), the goal of this paper is to reconstruct a high-resolution version thereof. This, by itself, is an ill-posed problem, as the high-frequency information is missing in the low-resolution input and needs to be hallucinated, based on prior knowledge about the image content. Rather than relying on a generic face prior, in this paper, we explore the use of a set of exemplars, i.e. other high-resolution images of the same person. These guide the neural network as we condition the output on them. Multiple exemplars work better than a single one. To combine the information from multiple exemplars effectively, we introduce a pixel-wise weight generation module. Besides standard face super-resolution, our method allows to perform subtle face editing simply by replacing the exemplars with another set with different facial features. A user study is conducted and shows the super-resolved images can hardly be distinguished from real images on the CelebA dataset. A qualitative comparison indicates our model outperforms methods proposed in the literature on the CelebA and WebFace dataset.
Information Compensation for Deep Conditional Generative Networks
Jan 24, 2020
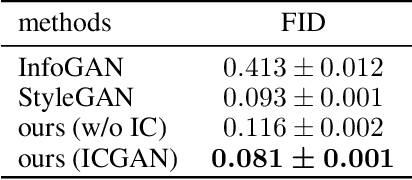
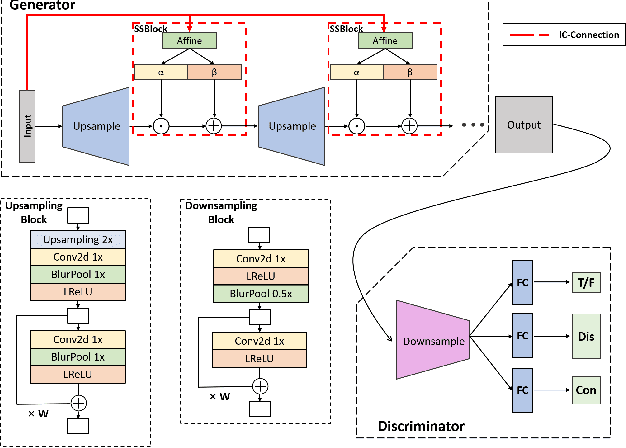
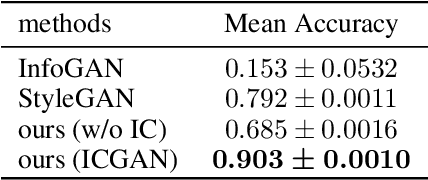
In recent years, unsupervised/weakly-supervised conditional generative adversarial networks (GANs) have achieved many successes on the task of modeling and generating data. However, one of their weaknesses lies in their poor ability to separate, or disentangle, the different factors that characterize the representation encoded in their latent space. To address this issue, we propose a novel structure for unsupervised conditional GANs powered by a novel Information Compensation Connection (IC-Connection). The proposed IC-Connection enables GANs to compensate for information loss incurred during deconvolution operations. In addition, to quantify the degree of disentanglement on both discrete and continuous latent variables, we design a novel evaluation procedure. Our empirical results suggest that our method achieves better disentanglement compared to the state-of-the-art GANs in a conditional generation setting.
An Iterative Approach for Multiple Instance Learning Problems
Sep 11, 2019
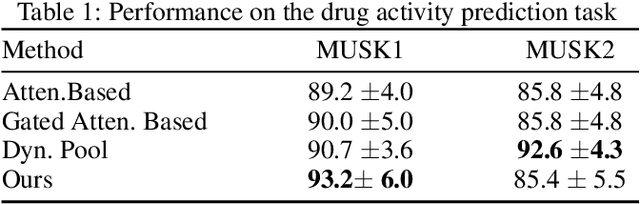
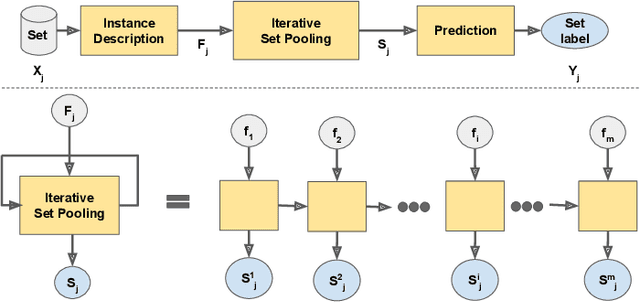

Multiple Instance learning (MIL) algorithms are tasked with learning how to associate sets of elements with specific set-level outputs. Towards this goal, the main challenge of MIL lies in modelling the underlying structure that characterizes sets of elements. Existing methods addressing MIL problems are usually tailored to address either: a specific underlying set structure; specific prediction tasks, e.g. classification, regression; or a combination of both. Here we present an approach where a set representation is learned, iteratively, by looking at the constituent elements of each set one at a time. The iterative analysis of set elements enables our approach with the capability to update the set representation so that it reflects whether relevant elements have been detected and whether the underlying structure has been matched. These features provide our method with some model explanation capabilities. Despite its simplicity, the proposed approach not only effectively models different types of underlying set structures, but it is also capable of handling both classification and regression tasks - all this while requiring minimal modifications. An extensive empirical evaluation shows that the proposed method is able to reach and surpass the state-of-the-art.