 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGCE-Font: Skeleton Guided Channel Expansion for Chinese Font Generation
Nov 26, 2022



The automatic generation of Chinese fonts is an important problem involved in many applications. The predominated methods for the Chinese font generation are based on the deep generative models, especially the generative adversarial networks (GANs). However, existing GAN-based methods (say, CycleGAN) for the Chinese font generation usually suffer from the mode collapse issue, mainly due to the lack of effective guidance information. This paper proposes a novel information guidance module called the skeleton guided channel expansion (SGCE) module for the Chinese font generation through integrating the skeleton information into the generator with the channel expansion way, motivated by the observation that the skeleton embodies both local and global structure information of Chinese characters. We conduct extensive experiments to show the effectiveness of the proposed module. Numerical results show that the mode collapse issue suffered by the known CycleGAN can be effectively alleviated by equipping with the proposed SGCE module, and the CycleGAN equipped with SGCE outperforms the state-of-the-art models in terms of four important evaluation metrics and visualization quality. Besides CycleGAN, we also show that the suggested SGCE module can be adapted to other models for Chinese font generation as a plug-and-play module to further improve their performance.
StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding
Nov 11, 2022

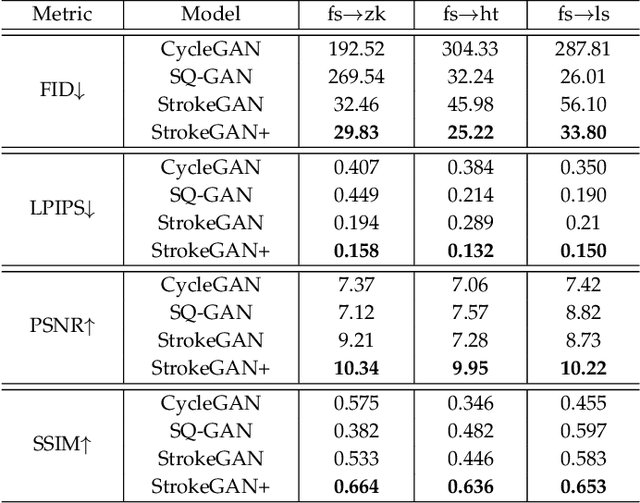

The generation of Chinese fonts has a wide range of applications. The currently predominated methods are mainly based on deep generative models, especially the generative adversarial networks (GANs). However, existing GAN-based models usually suffer from the well-known mode collapse problem. When mode collapse happens, the kind of GAN-based models will be failure to yield the correct fonts. To address this issue, we introduce a one-bit stroke encoding and a few-shot semi-supervised scheme (i.e., using a few paired data as semi-supervised information) to explore the local and global structure information of Chinese characters respectively, motivated by the intuition that strokes and characters directly embody certain local and global modes of Chinese characters. Based on these ideas, this paper proposes an effective model called \textit{StrokeGAN+}, which incorporates the stroke encoding and the few-shot semi-supervised scheme into the CycleGAN model. The effectiveness of the proposed model is demonstrated by amounts of experiments. Experimental results show that the mode collapse issue can be effectively alleviated by the introduced one-bit stroke encoding and few-shot semi-supervised training scheme, and that the proposed model outperforms the state-of-the-art models in fourteen font generation tasks in terms of four important evaluation metrics and the quality of generated characters. Besides CycleGAN, we also show that the proposed idea can be adapted to other existing models to improve their performance. The effectiveness of the proposed model for the zero-shot traditional Chinese font generation is also evaluated in this paper.
Audio-Visual Grounding Referring Expression for Robotic Manipulation
Sep 22, 2021
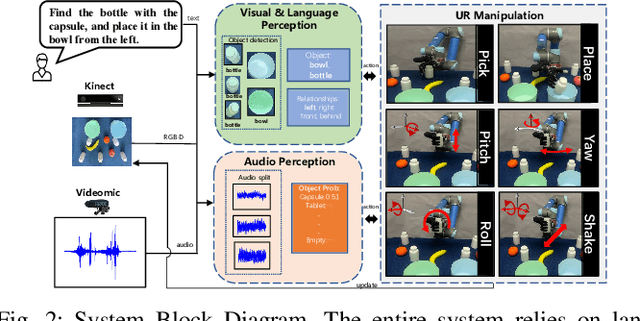
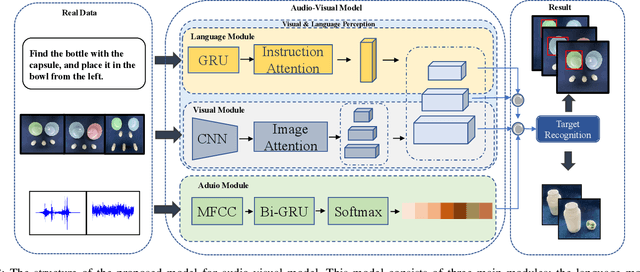

Referring expressions are commonly used when referring to a specific target in people's daily dialogue. In this paper, we develop a novel task of audio-visual grounding referring expression for robotic manipulation. The robot leverages both the audio and visual information to understand the referring expression in the given manipulation instruction and the corresponding manipulations are implemented. To solve the proposed task, an audio-visual framework is proposed for visual localization and sound recognition. We have also established a dataset which contains visual data, auditory data and manipulation instructions for evaluation. Finally, extensive experiments are conducted both offline and online to verify the effectiveness of the proposed audio-visual framework. And it is demonstrated that the robot performs better with the audio-visual data than with only the visual data.