 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-dimensional Visual Prompt Enhanced Image Restoration via Mamba-Transformer Aggregation
Dec 20, 2024



Recent efforts on image restoration have focused on developing "all-in-one" models that can handle different degradation types and levels within single model. However, most of mainstream Transformer-based ones confronted with dilemma between model capabilities and computation burdens, since self-attention mechanism quadratically increase in computational complexity with respect to image size, and has inadequacies in capturing long-range dependencies. Most of Mamba-related ones solely scanned feature map in spatial dimension for global modeling, failing to fully utilize information in channel dimension. To address aforementioned problems, this paper has proposed to fully utilize complementary advantages from Mamba and Transformer without sacrificing computation efficiency. Specifically, the selective scanning mechanism of Mamba is employed to focus on spatial modeling, enabling capture long-range spatial dependencies under linear complexity. The self-attention mechanism of Transformer is applied to focus on channel modeling, avoiding high computation burdens that are in quadratic growth with image's spatial dimensions. Moreover, to enrich informative prompts for effective image restoration, multi-dimensional prompt learning modules are proposed to learn prompt-flows from multi-scale encoder/decoder layers, benefiting for revealing underlying characteristic of various degradations from both spatial and channel perspectives, therefore, enhancing the capabilities of "all-in-one" model to solve various restoration tasks. Extensive experiment results on several image restoration benchmark tasks such as image denoising, dehazing, and deraining, have demonstrated that the proposed method can achieve new state-of-the-art performance, compared with many popular mainstream methods. Related source codes and pre-trained parameters will be public on github https://github.com/12138-chr/MTAIR.
DaLPSR: Leverage Degradation-Aligned Language Prompt for Real-World Image Super-Resolution
Jun 24, 2024



Image super-resolution pursuits reconstructing high-fidelity high-resolution counterpart for low-resolution image. In recent years, diffusion-based models have garnered significant attention due to their capabilities with rich prior knowledge. The success of diffusion models based on general text prompts has validated the effectiveness of textual control in the field of text2image. However, given the severe degradation commonly presented in low-resolution images, coupled with the randomness characteristics of diffusion models, current models struggle to adequately discern semantic and degradation information within severely degraded images. This often leads to obstacles such as semantic loss, visual artifacts, and visual hallucinations, which pose substantial challenges for practical use. To address these challenges, this paper proposes to leverage degradation-aligned language prompt for accurate, fine-grained, and high-fidelity image restoration. Complementary priors including semantic content descriptions and degradation prompts are explored. Specifically, on one hand, image-restoration prompt alignment decoder is proposed to automatically discern the degradation degree of LR images, thereby generating beneficial degradation priors for image restoration. On the other hand, much richly tailored descriptions from pretrained multimodal large language model elicit high-level semantic priors closely aligned with human perception, ensuring fidelity control for image restoration. Comprehensive comparisons with state-of-the-art methods have been done on several popular synthetic and real-world benchmark datasets. The quantitative and qualitative analysis have demonstrated that the proposed method achieves a new state-of-the-art perceptual quality level, especially in real-world cases based on reference-free metrics.
A Novel Approach to Industrial Defect Generation through Blended Latent Diffusion Model with Online Adaptation
Feb 29, 2024

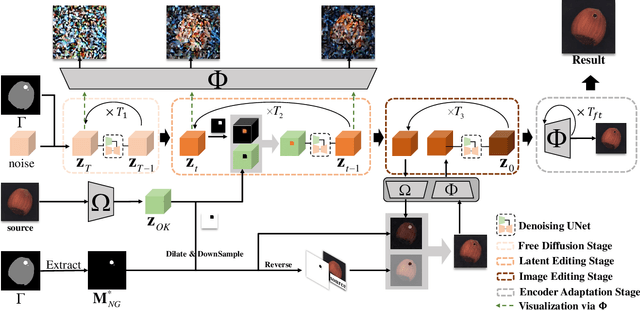

Effectively addressing the challenge of industrial Anomaly Detection (AD) necessitates an ample supply of defective samples, a constraint often hindered by their scarcity in industrial contexts. This paper introduces a novel algorithm designed to augment defective samples, thereby enhancing AD performance. The proposed method tailors the blended latent diffusion model for defect sample generation, employing a diffusion model to generate defective samples in the latent space. A feature editing process, controlled by a "trimap" mask and text prompts, refines the generated samples. The image generation inference process is structured into three stages: a free diffusion stage, an editing diffusion stage, and an online decoder adaptation stage. This sophisticated inference strategy yields high-quality synthetic defective samples with diverse pattern variations, leading to significantly improved AD accuracies based on the augmented training set. Specifically, on the widely recognized MVTec AD dataset, the proposed method elevates the state-of-the-art (SOTA) performance of AD with augmented data by 1.5%, 1.9%, and 3.1% for AD metrics AP, IAP, and IAP90, respectively. The implementation code of this work can be found at the GitHub repository https://github.com/GrandpaXun242/AdaBLDM.git
Information Retrieval Meets Large Language Models: A Strategic Report from Chinese IR Community
Jul 27, 2023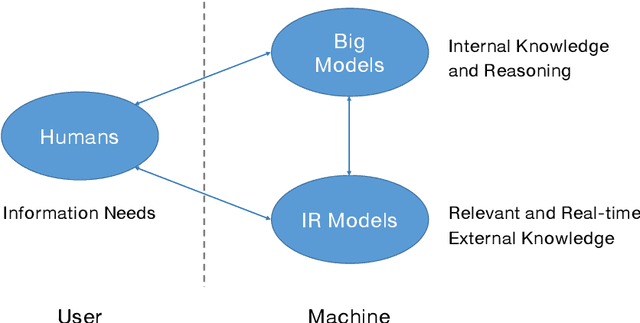
The research field of Information Retrieval (IR) has evolved significantly, expanding beyond traditional search to meet diverse user information needs. Recently, Large Language Models (LLMs) have demonstrated exceptional capabilities in text understanding, generation, and knowledge inference, opening up exciting avenues for IR research. LLMs not only facilitate generative retrieval but also offer improved solutions for user understanding, model evaluation, and user-system interactions. More importantly, the synergistic relationship among IR models, LLMs, and humans forms a new technical paradigm that is more powerful for information seeking. IR models provide real-time and relevant information, LLMs contribute internal knowledge, and humans play a central role of demanders and evaluators to the reliability of information services. Nevertheless, significant challenges exist, including computational costs, credibility concerns, domain-specific limitations, and ethical considerations. To thoroughly discuss the transformative impact of LLMs on IR research, the Chinese IR community conducted a strategic workshop in April 2023, yielding valuable insights. This paper provides a summary of the workshop's outcomes, including the rethinking of IR's core values, the mutual enhancement of LLMs and IR, the proposal of a novel IR technical paradigm, and open challenges.
Efficient Anomaly Detection with Budget Annotation Using Semi-Supervised Residual Transformer
Jun 06, 2023



Anomaly Detection is challenging as usually only the normal samples are seen during training and the detector needs to discover anomalies on-the-fly. The recently proposed deep-learning-based approaches could somehow alleviate the problem but there is still a long way to go in obtaining an industrial-class anomaly detector for real-world applications. On the other hand, in some particular AD tasks, a few anomalous samples are labeled manually for achieving higher accuracy. However, this performance gain is at the cost of considerable annotation efforts, which can be intractable in many practical scenarios. In this work, the above two problems are addressed in a unified framework. Firstly, inspired by the success of the patch-matching-based AD algorithms, we train a sliding vision transformer over the residuals generated by a novel position-constrained patch-matching. Secondly, the conventional pixel-wise segmentation problem is cast into a block-wise classification problem. Thus the sliding transformer can attain even higher accuracy with much less annotation labor. Thirdly, to further reduce the labeling cost, we propose to label the anomalous regions using only bounding boxes. The unlabeled regions caused by the weak labels are effectively exploited using a highly-customized semi-supervised learning scheme equipped with two novel data augmentation methods. The proposed method outperforms all the state-of-the-art approaches using all the evaluation metrics in both the unsupervised and supervised scenarios. On the popular MVTec-AD dataset, our SemiREST algorithm obtains the Average Precision (AP) of 81.2% in the unsupervised condition and 84.4% AP for supervised anomaly detection. Surprisingly, with the bounding-box-based semi-supervisions, SemiREST still outperforms the SOTA methods with full supervision (83.8% AP) on MVTec-AD.
StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding
Nov 11, 2022

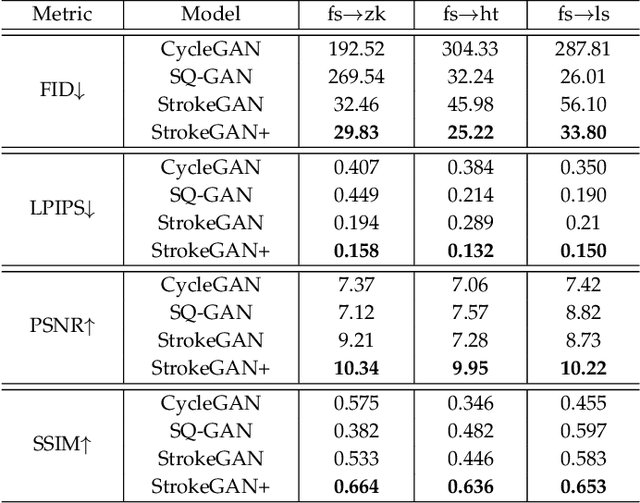

The generation of Chinese fonts has a wide range of applications. The currently predominated methods are mainly based on deep generative models, especially the generative adversarial networks (GANs). However, existing GAN-based models usually suffer from the well-known mode collapse problem. When mode collapse happens, the kind of GAN-based models will be failure to yield the correct fonts. To address this issue, we introduce a one-bit stroke encoding and a few-shot semi-supervised scheme (i.e., using a few paired data as semi-supervised information) to explore the local and global structure information of Chinese characters respectively, motivated by the intuition that strokes and characters directly embody certain local and global modes of Chinese characters. Based on these ideas, this paper proposes an effective model called \textit{StrokeGAN+}, which incorporates the stroke encoding and the few-shot semi-supervised scheme into the CycleGAN model. The effectiveness of the proposed model is demonstrated by amounts of experiments. Experimental results show that the mode collapse issue can be effectively alleviated by the introduced one-bit stroke encoding and few-shot semi-supervised training scheme, and that the proposed model outperforms the state-of-the-art models in fourteen font generation tasks in terms of four important evaluation metrics and the quality of generated characters. Besides CycleGAN, we also show that the proposed idea can be adapted to other existing models to improve their performance. The effectiveness of the proposed model for the zero-shot traditional Chinese font generation is also evaluated in this paper.
Convolutional Neural Network with Convolutional Block Attention Module for Finger Vein Recognition
Feb 14, 2022Convolutional neural networks have become a popular research in the field of finger vein recognition because of their powerful image feature representation. However, most researchers focus on improving the performance of the network by increasing the CNN depth and width, which often requires high computational effort. Moreover, we can notice that not only the importance of pixels in different channels is different, but also the importance of pixels in different positions of the same channel is different. To reduce the computational effort and to take into account the different importance of pixels, we propose a lightweight convolutional neural network with a convolutional block attention module (CBAM) for finger vein recognition, which can achieve a more accurate capture of visual structures through an attention mechanism. First, image sequences are fed into a lightweight convolutional neural network we designed to improve visual features. Afterwards, it learns to assign feature weights in an adaptive manner with the help of a convolutional block attention module. The experiments are carried out on two publicly available databases and the results demonstrate that the proposed method achieves a stable, highly accurate, and robust performance in multimodal finger recognition.
Finger Vein Recognition by Generating Code
Jan 21, 2021Finger vein recognition has drawn increasing attention as one of the most popular and promising biometrics due to its high distinguishes ability, security and non-invasive procedure. The main idea of traditional schemes is to directly extract features from finger vein images or patterns and then compare features to find the best match. However, the features extracted from images contain much redundant data, while the features extracted from patterns are greatly influenced by image segmentation methods. To tack these problems, this paper proposes a new finger vein recognition by generating code. The proposed method does not require an image segmentation algorithm, is simple to calculate and has a small amount of data. Firstly, the finger vein images were divided into blocks to calculate the mean value. Then the centrosymmetric coding is performed by using the generated eigenmatrix. The obtained codewords are concatenated as the feature codewords of the image. The similarity between vein codes is measured by the ratio of minimum Hamming distance to codeword length. Extensive experiments on two public finger vein databases verify the effectiveness of the proposed method. The results indicate that our method outperforms the state-of-theart methods and has competitive potential in performing the matching task.
StrokeGAN: Reducing Mode Collapse in Chinese Font Generation via Stroke Encoding
Jan 11, 2021
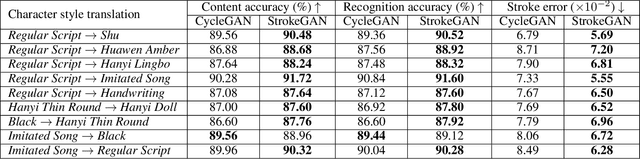


The generation of stylish Chinese fonts is an important problem involved in many applications. Most of existing generation methods are based on the deep generative models, particularly, the generative adversarial networks (GAN) based models. However, these deep generative models may suffer from the mode collapse issue, which significantly degrades the diversity and quality of generated results. In this paper, we introduce a one-bit stroke encoding to capture the key mode information of Chinese characters and then incorporate it into CycleGAN, a popular deep generative model for Chinese font generation. As a result we propose an efficient method called StrokeGAN, mainly motivated by the observation that the stroke encoding contains amount of mode information of Chinese characters. In order to reconstruct the one-bit stroke encoding of the associated generated characters, we introduce a stroke-encoding reconstruction loss imposed on the discriminator. Equipped with such one-bit stroke encoding and stroke-encoding reconstruction loss, the mode collapse issue of CycleGAN can be significantly alleviated, with an improved preservation of strokes and diversity of generated characters. The effectiveness of StrokeGAN is demonstrated by a series of generation tasks over nine datasets with different fonts. The numerical results demonstrate that StrokeGAN generally outperforms the state-of-the-art methods in terms of content and recognition accuracies, as well as certain stroke error, and also generates more realistic characters.
* 10 pages, our codes and data are available at: https://github.com/JinshanZeng/StrokeGAN
Scale-Aware Network with Regional and Semantic Attentions for Crowd Counting under Cluttered Background
Jan 07, 2021
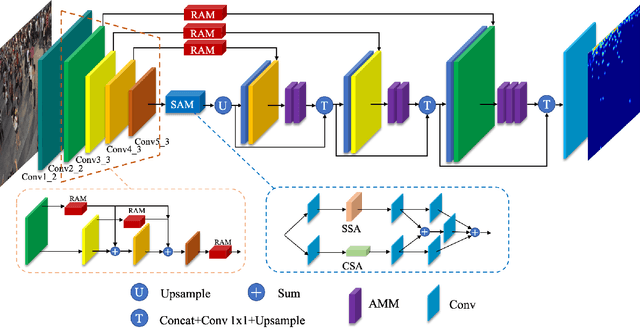


Crowd counting is an important task that shown great application value in public safety-related fields, which has attracted increasing attention in recent years. In the current research, the accuracy of counting numbers and crowd density estimation are the main concerns. Although the emergence of deep learning has greatly promoted the development of this field, crowd counting under cluttered background is still a serious challenge. In order to solve this problem, we propose a ScaleAware Crowd Counting Network (SACCN) with regional and semantic attentions. The proposed SACCN distinguishes crowd and background by applying regional and semantic self-attention mechanisms on the shallow layers and deep layers, respectively. Moreover, the asymmetric multi-scale module (AMM) is proposed to deal with the problem of scale diversity, and regional attention based dense connections and skip connections are designed to alleviate the variations on crowd scales. Extensive experimental results on multiple public benchmarks demonstrate that our proposed SACCN achieves satisfied superior performances and outperform most state-of-the-art methods. All codes and pretrained models will be released soon.