 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Conformal Risk Control
Dec 14, 2025
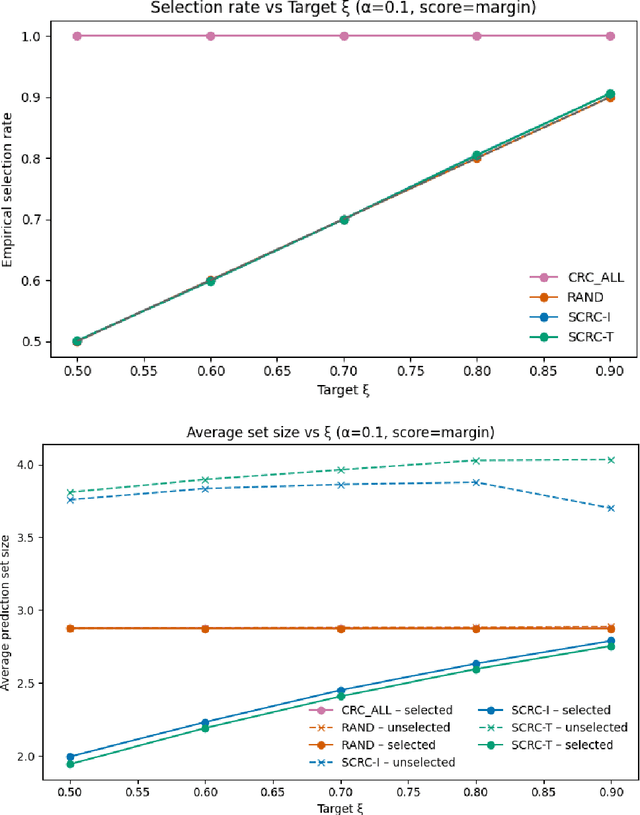

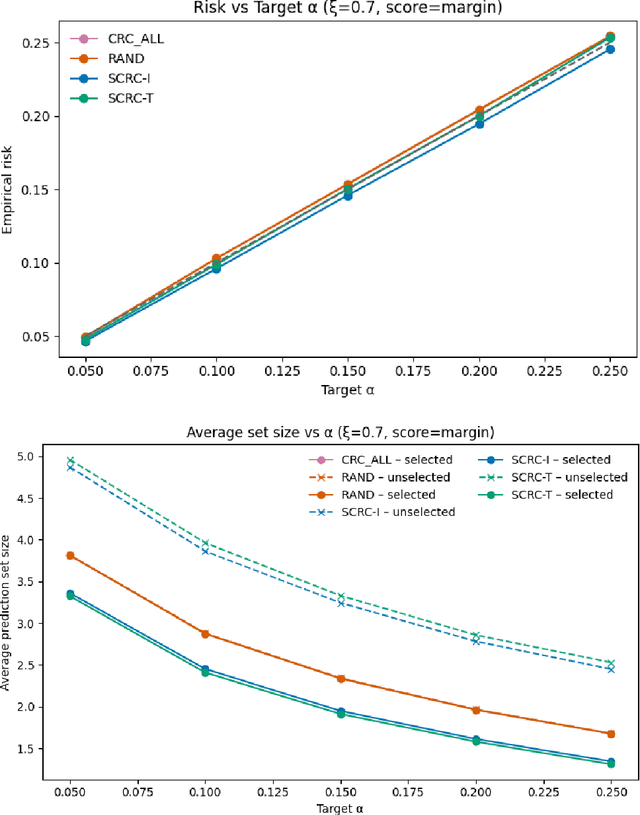
Reliable uncertainty quantification is essential for deploying machine learning systems in high-stakes domains. Conformal prediction provides distribution-free coverage guarantees but often produces overly large prediction sets, limiting its practical utility. To address this issue, we propose \textit{Selective Conformal Risk Control} (SCRC), a unified framework that integrates conformal prediction with selective classification. The framework formulates uncertainty control as a two-stage problem: the first stage selects confident samples for prediction, and the second stage applies conformal risk control on the selected subset to construct calibrated prediction sets. We develop two algorithms under this framework. The first, SCRC-T, preserves exchangeability by computing thresholds jointly over calibration and test samples, offering exact finite-sample guarantees. The second, SCRC-I, is a calibration-only variant that provides PAC-style probabilistic guarantees while being more computational efficient. Experiments on two public datasets show that both methods achieve the target coverage and risk levels, with nearly identical performance, while SCRC-I exhibits slightly more conservative risk control but superior computational practicality. Our results demonstrate that selective conformal risk control offers an effective and efficient path toward compact, reliable uncertainty quantification.
DaLPSR: Leverage Degradation-Aligned Language Prompt for Real-World Image Super-Resolution
Jun 24, 2024



Image super-resolution pursuits reconstructing high-fidelity high-resolution counterpart for low-resolution image. In recent years, diffusion-based models have garnered significant attention due to their capabilities with rich prior knowledge. The success of diffusion models based on general text prompts has validated the effectiveness of textual control in the field of text2image. However, given the severe degradation commonly presented in low-resolution images, coupled with the randomness characteristics of diffusion models, current models struggle to adequately discern semantic and degradation information within severely degraded images. This often leads to obstacles such as semantic loss, visual artifacts, and visual hallucinations, which pose substantial challenges for practical use. To address these challenges, this paper proposes to leverage degradation-aligned language prompt for accurate, fine-grained, and high-fidelity image restoration. Complementary priors including semantic content descriptions and degradation prompts are explored. Specifically, on one hand, image-restoration prompt alignment decoder is proposed to automatically discern the degradation degree of LR images, thereby generating beneficial degradation priors for image restoration. On the other hand, much richly tailored descriptions from pretrained multimodal large language model elicit high-level semantic priors closely aligned with human perception, ensuring fidelity control for image restoration. Comprehensive comparisons with state-of-the-art methods have been done on several popular synthetic and real-world benchmark datasets. The quantitative and qualitative analysis have demonstrated that the proposed method achieves a new state-of-the-art perceptual quality level, especially in real-world cases based on reference-free metrics.
Conformal Risk Control for Ordinal Classification
May 01, 2024As a natural extension to the standard conformal prediction method, several conformal risk control methods have been recently developed and applied to various learning problems. In this work, we seek to control the conformal risk in expectation for ordinal classification tasks, which have broad applications to many real problems. For this purpose, we firstly formulated the ordinal classification task in the conformal risk control framework, and provided theoretic risk bounds of the risk control method. Then we proposed two types of loss functions specially designed for ordinal classification tasks, and developed corresponding algorithms to determine the prediction set for each case to control their risks at a desired level. We demonstrated the effectiveness of our proposed methods, and analyzed the difference between the two types of risks on three different datasets, including a simulated dataset, the UTKFace dataset and the diabetic retinopathy detection dataset.
* 17 pages, 8 figures, 2 table; 1 supplementary page
Conformal Ranked Retrieval
Apr 27, 2024



Given the wide adoption of ranked retrieval techniques in various information systems that significantly impact our daily lives, there is an increasing need to assess and address the uncertainty inherent in their predictions. This paper introduces a novel method using the conformal risk control framework to quantitatively measure and manage risks in the context of ranked retrieval problems. Our research focuses on a typical two-stage ranked retrieval problem, where the retrieval stage generates candidates for subsequent ranking. By carefully formulating the conformal risk for each stage, we have developed algorithms to effectively control these risks within their specified bounds. The efficacy of our proposed methods has been demonstrated through comprehensive experiments on three large-scale public datasets for ranked retrieval tasks, including the MSLR-WEB dataset, the Yahoo LTRC dataset and the MS MARCO dataset.
DeepVar: An End-to-End Deep Learning Approach for Genomic Variant Recognition in Biomedical Literature
Jun 05, 2020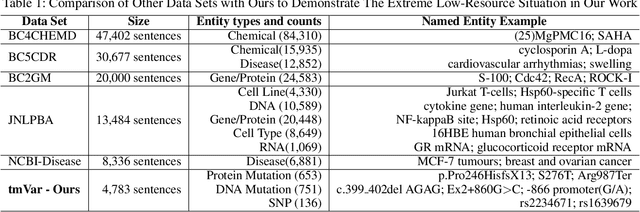
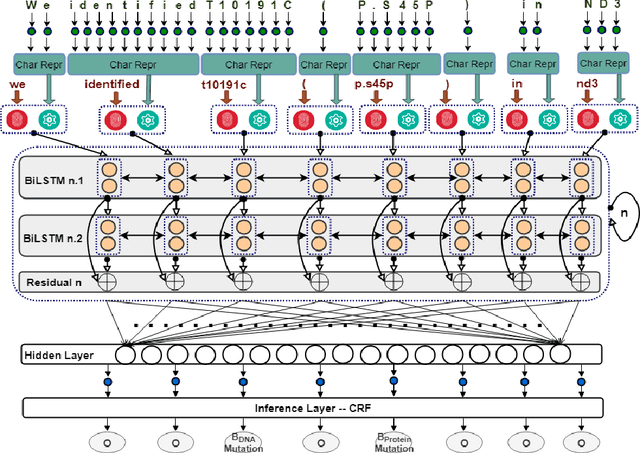

We consider the problem of Named Entity Recognition (NER) on biomedical scientific literature, and more specifically the genomic variants recognition in this work. Significant success has been achieved for NER on canonical tasks in recent years where large data sets are generally available. However, it remains a challenging problem on many domain-specific areas, especially the domains where only small gold annotations can be obtained. In addition, genomic variant entities exhibit diverse linguistic heterogeneity, differing much from those that have been characterized in existing canonical NER tasks. The state-of-the-art machine learning approaches in such tasks heavily rely on arduous feature engineering to characterize those unique patterns. In this work, we present the first successful end-to-end deep learning approach to bridge the gap between generic NER algorithms and low-resource applications through genomic variants recognition. Our proposed model can result in promising performance without any hand-crafted features or post-processing rules. Our extensive experiments and results may shed light on other similar low-resource NER applications.
A Blended Deep Learning Approach for Predicting User Intended Actions
Oct 11, 2018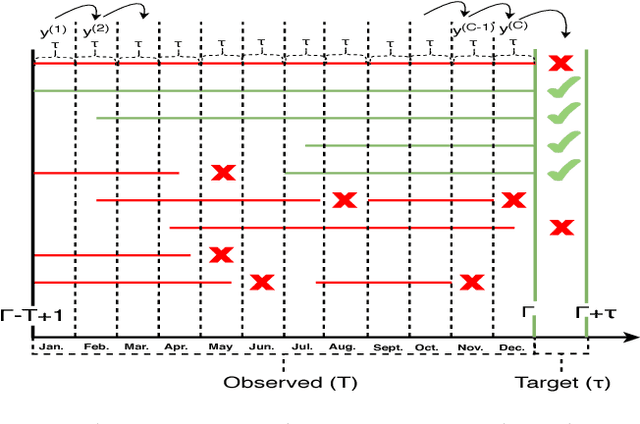
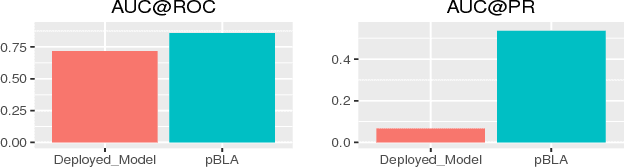
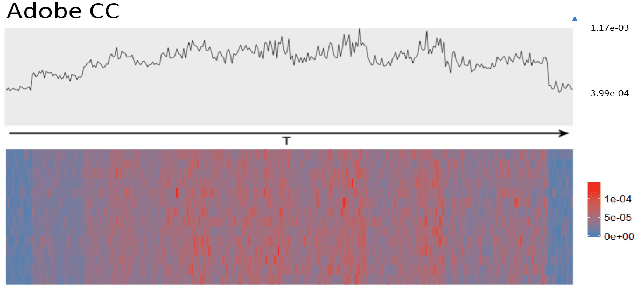
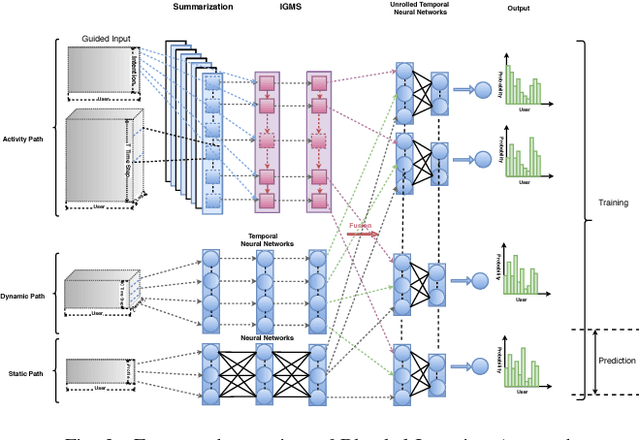
User intended actions are widely seen in many areas. Forecasting these actions and taking proactive measures to optimize business outcome is a crucial step towards sustaining the steady business growth. In this work, we focus on pre- dicting attrition, which is one of typical user intended actions. Conventional attrition predictive modeling strategies suffer a few inherent drawbacks. To overcome these limitations, we propose a novel end-to-end learning scheme to keep track of the evolution of attrition patterns for the predictive modeling. It integrates user activity logs, dynamic and static user profiles based on multi-path learning. It exploits historical user records by establishing a decaying multi-snapshot technique. And finally it employs the precedent user intentions via guiding them to the subsequent learning procedure. As a result, it addresses all disadvantages of conventional methods. We evaluate our methodology on two public data repositories and one private user usage dataset provided by Adobe Creative Cloud. The extensive experiments demonstrate that it can offer the appealing performance in comparison with several existing approaches as rated by different popular metrics. Furthermore, we introduce an advanced interpretation and visualization strategy to effectively characterize the periodicity of user activity logs. It can help to pinpoint important factors that are critical to user attrition and retention and thus suggests actionable improvement targets for business practice. Our work will provide useful insights into the prediction and elucidation of other user intended actions as well.
A Noise-Filtering Approach for Cancer Drug Sensitivity Prediction
Dec 05, 2016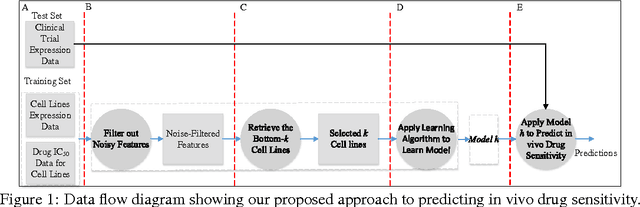

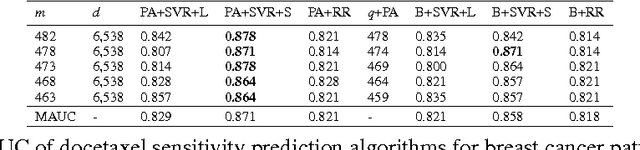
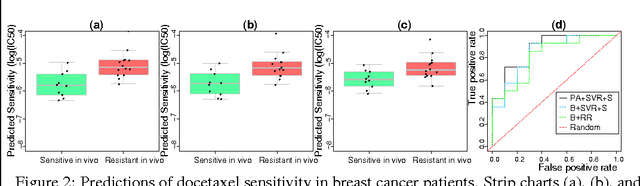
Accurately predicting drug responses to cancer is an important problem hindering oncologists' efforts to find the most effective drugs to treat cancer, which is a core goal in precision medicine. The scientific community has focused on improving this prediction based on genomic, epigenomic, and proteomic datasets measured in human cancer cell lines. Real-world cancer cell lines contain noise, which degrades the performance of machine learning algorithms. This problem is rarely addressed in the existing approaches. In this paper, we present a noise-filtering approach that integrates techniques from numerical linear algebra and information retrieval targeted at filtering out noisy cancer cell lines. By filtering out noisy cancer cell lines, we can train machine learning algorithms on better quality cancer cell lines. We evaluate the performance of our approach and compare it with an existing approach using the Area Under the ROC Curve (AUC) on clinical trial data. The experimental results show that our proposed approach is stable and also yields the highest AUC at a statistically significant level.