 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-dimensional Visual Prompt Enhanced Image Restoration via Mamba-Transformer Aggregation
Dec 20, 2024



Recent efforts on image restoration have focused on developing "all-in-one" models that can handle different degradation types and levels within single model. However, most of mainstream Transformer-based ones confronted with dilemma between model capabilities and computation burdens, since self-attention mechanism quadratically increase in computational complexity with respect to image size, and has inadequacies in capturing long-range dependencies. Most of Mamba-related ones solely scanned feature map in spatial dimension for global modeling, failing to fully utilize information in channel dimension. To address aforementioned problems, this paper has proposed to fully utilize complementary advantages from Mamba and Transformer without sacrificing computation efficiency. Specifically, the selective scanning mechanism of Mamba is employed to focus on spatial modeling, enabling capture long-range spatial dependencies under linear complexity. The self-attention mechanism of Transformer is applied to focus on channel modeling, avoiding high computation burdens that are in quadratic growth with image's spatial dimensions. Moreover, to enrich informative prompts for effective image restoration, multi-dimensional prompt learning modules are proposed to learn prompt-flows from multi-scale encoder/decoder layers, benefiting for revealing underlying characteristic of various degradations from both spatial and channel perspectives, therefore, enhancing the capabilities of "all-in-one" model to solve various restoration tasks. Extensive experiment results on several image restoration benchmark tasks such as image denoising, dehazing, and deraining, have demonstrated that the proposed method can achieve new state-of-the-art performance, compared with many popular mainstream methods. Related source codes and pre-trained parameters will be public on github https://github.com/12138-chr/MTAIR.
Variable Aperture Bokeh Rendering via Customized Focal Plane Guidance
Oct 18, 2024
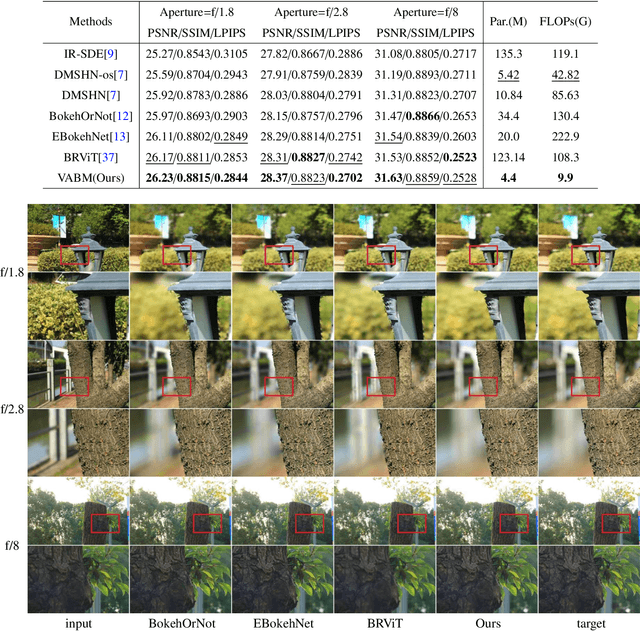
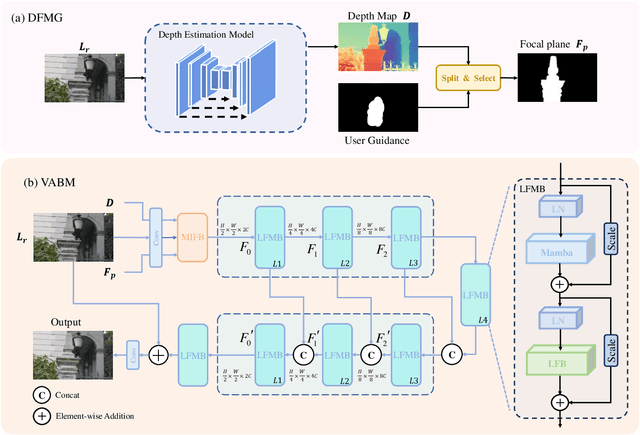
Bokeh rendering is one of the most popular techniques in photography. It can make photographs visually appealing, forcing users to focus their attentions on particular area of image. However, achieving satisfactory bokeh effect usually presents significant challenge, since mobile cameras with restricted optical systems are constrained, while expensive high-end DSLR lens with large aperture should be needed. Therefore, many deep learning-based computational photography methods have been developed to mimic the bokeh effect in recent years. Nevertheless, most of these methods were limited to rendering bokeh effect in certain single aperture. There lacks user-friendly bokeh rendering method that can provide precise focal plane control and customised bokeh generation. There as well lacks authentic realistic bokeh dataset that can potentially promote bokeh learning on variable apertures. To address these two issues, in this paper, we have proposed an effective controllable bokeh rendering method, and contributed a Variable Aperture Bokeh Dataset (VABD). In the proposed method, user can customize focal plane to accurately locate concerned subjects and select target aperture information for bokeh rendering. Experimental results on public EBB! benchmark dataset and our constructed dataset VABD have demonstrated that the customized focal plane together aperture prompt can bootstrap model to simulate realistic bokeh effect. The proposed method has achieved competitive state-of-the-art performance with only 4.4M parameters, which is much lighter than mainstream computational bokeh models. The contributed dataset and source codes will be released on github https://github.com/MoTong-AI-studio/VABM.
Latent Conditional Diffusion-based Data Augmentation for Continuous-Time Dynamic Graph Mode
Jul 11, 2024
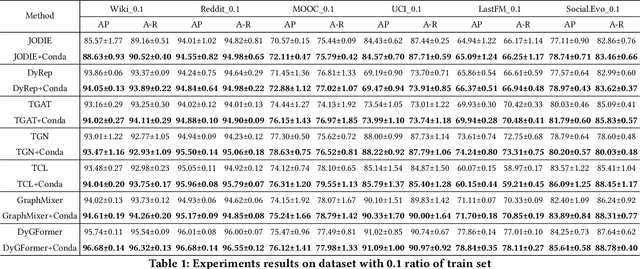
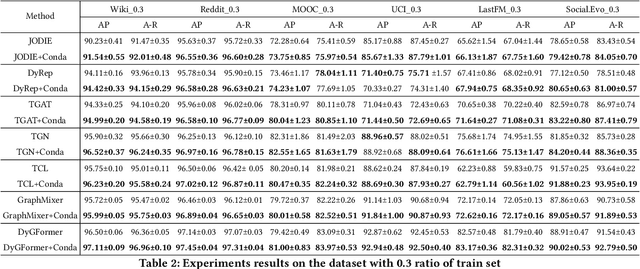

Continuous-Time Dynamic Graph (CTDG) precisely models evolving real-world relationships, drawing heightened interest in dynamic graph learning across academia and industry. However, existing CTDG models encounter challenges stemming from noise and limited historical data. Graph Data Augmentation (GDA) emerges as a critical solution, yet current approaches primarily focus on static graphs and struggle to effectively address the dynamics inherent in CTDGs. Moreover, these methods often demand substantial domain expertise for parameter tuning and lack theoretical guarantees for augmentation efficacy. To address these issues, we propose Conda, a novel latent diffusion-based GDA method tailored for CTDGs. Conda features a sandwich-like architecture, incorporating a Variational Auto-Encoder (VAE) and a conditional diffusion model, aimed at generating enhanced historical neighbor embeddings for target nodes. Unlike conventional diffusion models trained on entire graphs via pre-training, Conda requires historical neighbor sequence embeddings of target nodes for training, thus facilitating more targeted augmentation. We integrate Conda into the CTDG model and adopt an alternating training strategy to optimize performance. Extensive experimentation across six widely used real-world datasets showcases the consistent performance improvement of our approach, particularly in scenarios with limited historical data.
DaLPSR: Leverage Degradation-Aligned Language Prompt for Real-World Image Super-Resolution
Jun 24, 2024



Image super-resolution pursuits reconstructing high-fidelity high-resolution counterpart for low-resolution image. In recent years, diffusion-based models have garnered significant attention due to their capabilities with rich prior knowledge. The success of diffusion models based on general text prompts has validated the effectiveness of textual control in the field of text2image. However, given the severe degradation commonly presented in low-resolution images, coupled with the randomness characteristics of diffusion models, current models struggle to adequately discern semantic and degradation information within severely degraded images. This often leads to obstacles such as semantic loss, visual artifacts, and visual hallucinations, which pose substantial challenges for practical use. To address these challenges, this paper proposes to leverage degradation-aligned language prompt for accurate, fine-grained, and high-fidelity image restoration. Complementary priors including semantic content descriptions and degradation prompts are explored. Specifically, on one hand, image-restoration prompt alignment decoder is proposed to automatically discern the degradation degree of LR images, thereby generating beneficial degradation priors for image restoration. On the other hand, much richly tailored descriptions from pretrained multimodal large language model elicit high-level semantic priors closely aligned with human perception, ensuring fidelity control for image restoration. Comprehensive comparisons with state-of-the-art methods have been done on several popular synthetic and real-world benchmark datasets. The quantitative and qualitative analysis have demonstrated that the proposed method achieves a new state-of-the-art perceptual quality level, especially in real-world cases based on reference-free metrics.
Dual-Path Coupled Image Deraining Network via Spatial-Frequency Interaction
Feb 07, 2024



Transformers have recently emerged as a significant force in the field of image deraining. Existing image deraining methods utilize extensive research on self-attention. Though showcasing impressive results, they tend to neglect critical frequency information, as self-attention is generally less adept at capturing high-frequency details. To overcome this shortcoming, we have developed an innovative Dual-Path Coupled Deraining Network (DPCNet) that integrates information from both spatial and frequency domains through Spatial Feature Extraction Block (SFEBlock) and Frequency Feature Extraction Block (FFEBlock). We have further introduced an effective Adaptive Fusion Module (AFM) for the dual-path feature aggregation. Extensive experiments on six public deraining benchmarks and downstream vision tasks have demonstrated that our proposed method not only outperforms the existing state-of-the-art deraining method but also achieves visually pleasuring results with excellent robustness on downstream vision tasks.
Textual Prompt Guided Image Restoration
Dec 11, 2023

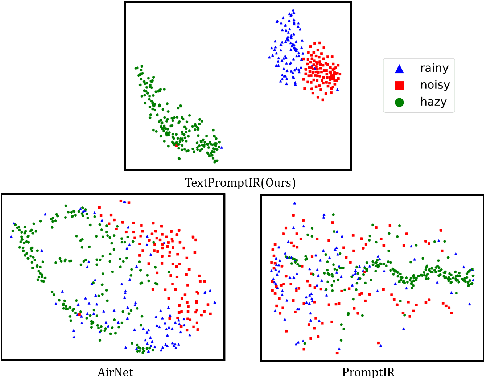

Image restoration has always been a cutting-edge topic in the academic and industrial fields of computer vision. Since degradation signals are often random and diverse, "all-in-one" models that can do blind image restoration have been concerned in recent years. Early works require training specialized headers and tails to handle each degradation of concern, which are manually cumbersome. Recent works focus on learning visual prompts from data distribution to identify degradation type. However, the prompts employed in most of models are non-text, lacking sufficient emphasis on the importance of human-in-the-loop. In this paper, an effective textual prompt guided image restoration model has been proposed. In this model, task-specific BERT is fine-tuned to accurately understand user's instructions and generating textual prompt guidance. Depth-wise multi-head transposed attentions and gated convolution modules are designed to bridge the gap between textual prompts and visual features. The proposed model has innovatively introduced semantic prompts into low-level visual domain. It highlights the potential to provide a natural, precise, and controllable way to perform image restoration tasks. Extensive experiments have been done on public denoising, dehazing and deraining datasets. The experiment results demonstrate that, compared with popular state-of-the-art methods, the proposed model can obtain much more superior performance, achieving accurate recognition and removal of degradation without increasing model's complexity. Related source codes and data will be publicly available on github site https://github.com/MoTong-AI-studio/TextPromptIR.
TOPS: Transition-based VOlatility-controlled Policy Search and its Global Convergence
Jan 24, 2022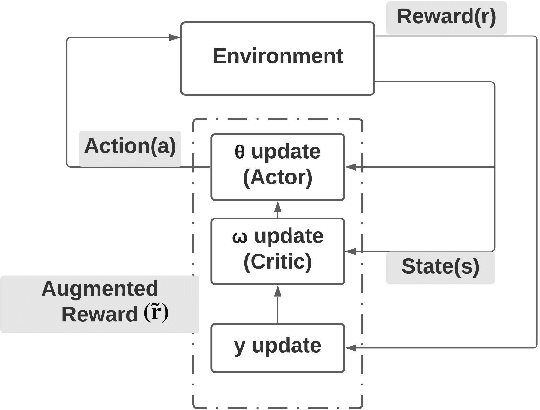
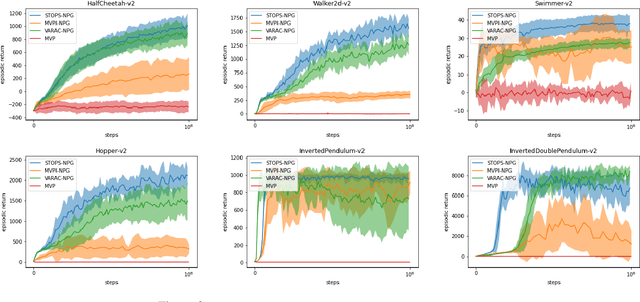
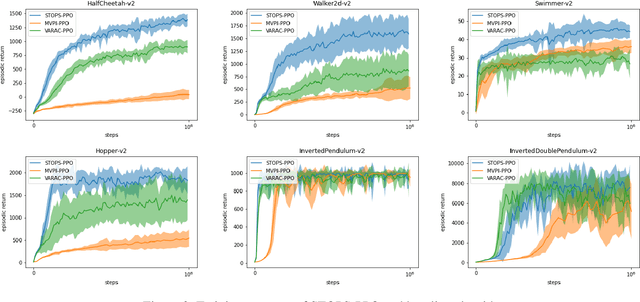
Risk-averse problems receive far less attention than risk-neutral control problems in reinforcement learning, and existing risk-averse approaches are challenging to deploy to real-world applications. One primary reason is that such risk-averse algorithms often learn from consecutive trajectories with a certain length, which significantly increases the potential danger of causing dangerous failures in practice. This paper proposes Transition-based VOlatility-controlled Policy Search (TOPS), a novel algorithm that solves risk-averse problems by learning from (possibly non-consecutive) transitions instead of only consecutive trajectories. By using an actor-critic scheme with an overparameterized two-layer neural network, our algorithm finds a globally optimal policy at a sublinear rate with proximal policy optimization and natural policy gradient, with effectiveness comparable to the state-of-the-art convergence rate of risk-neutral policy-search methods. The algorithm is evaluated on challenging Mujoco robot simulation tasks under the mean-variance evaluation metric. Both theoretical analysis and experimental results demonstrate a state-of-the-art level of risk-averse policy search methods.
Efficient and Accurate Multi-scale Topological Network for Single Image Dehazing
Feb 24, 2021
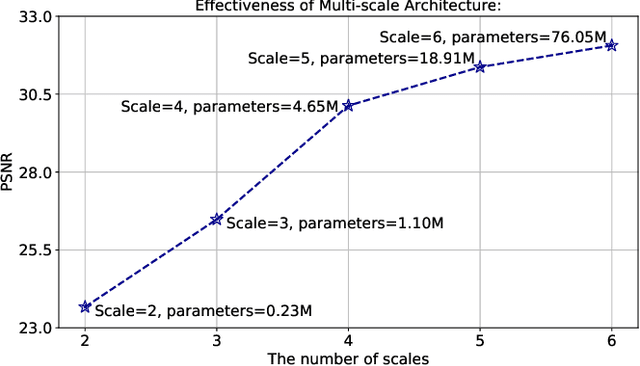
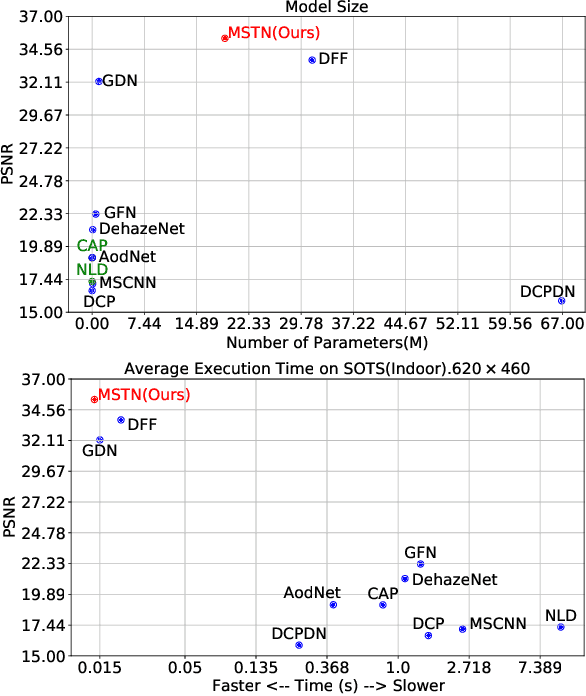
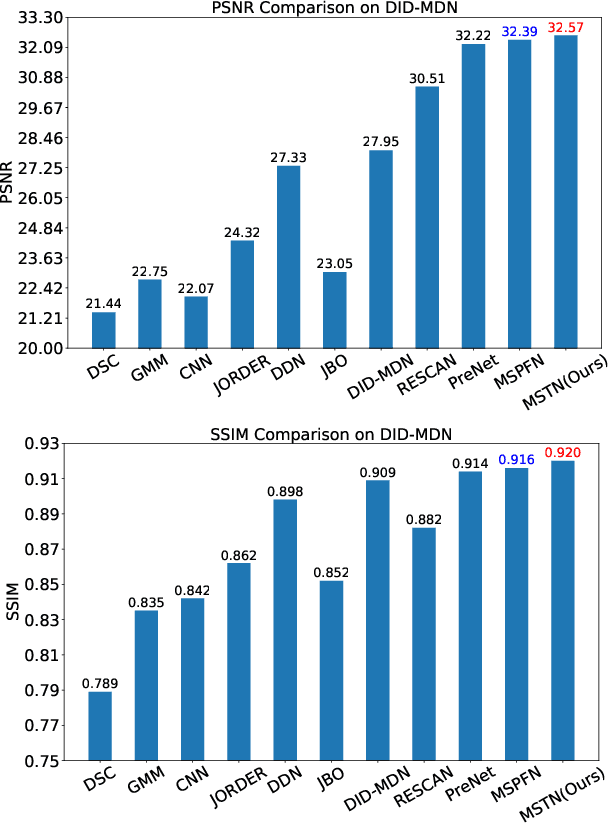
Single image dehazing is a challenging ill-posed problem that has drawn significant attention in the last few years. Recently, convolutional neural networks have achieved great success in image dehazing. However, it is still difficult for these increasingly complex models to recover accurate details from the hazy image. In this paper, we pay attention to the feature extraction and utilization of the input image itself. To achieve this, we propose a Multi-scale Topological Network (MSTN) to fully explore the features at different scales. Meanwhile, we design a Multi-scale Feature Fusion Module (MFFM) and an Adaptive Feature Selection Module (AFSM) to achieve the selection and fusion of features at different scales, so as to achieve progressive image dehazing. This topological network provides a large number of search paths that enable the network to extract abundant image features as well as strong fault tolerance and robustness. In addition, ASFM and MFFM can adaptively select important features and ignore interference information when fusing different scale representations. Extensive experiments are conducted to demonstrate the superiority of our method compared with state-of-the-art methods.
Scale-Aware Network with Regional and Semantic Attentions for Crowd Counting under Cluttered Background
Jan 07, 2021
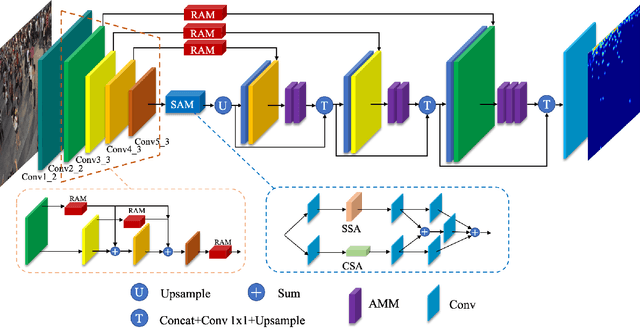


Crowd counting is an important task that shown great application value in public safety-related fields, which has attracted increasing attention in recent years. In the current research, the accuracy of counting numbers and crowd density estimation are the main concerns. Although the emergence of deep learning has greatly promoted the development of this field, crowd counting under cluttered background is still a serious challenge. In order to solve this problem, we propose a ScaleAware Crowd Counting Network (SACCN) with regional and semantic attentions. The proposed SACCN distinguishes crowd and background by applying regional and semantic self-attention mechanisms on the shallow layers and deep layers, respectively. Moreover, the asymmetric multi-scale module (AMM) is proposed to deal with the problem of scale diversity, and regional attention based dense connections and skip connections are designed to alleviate the variations on crowd scales. Extensive experimental results on multiple public benchmarks demonstrate that our proposed SACCN achieves satisfied superior performances and outperform most state-of-the-art methods. All codes and pretrained models will be released soon.
An Effective Single-Image Super-Resolution Model Using Squeeze-and-Excitation Networks
Oct 03, 2018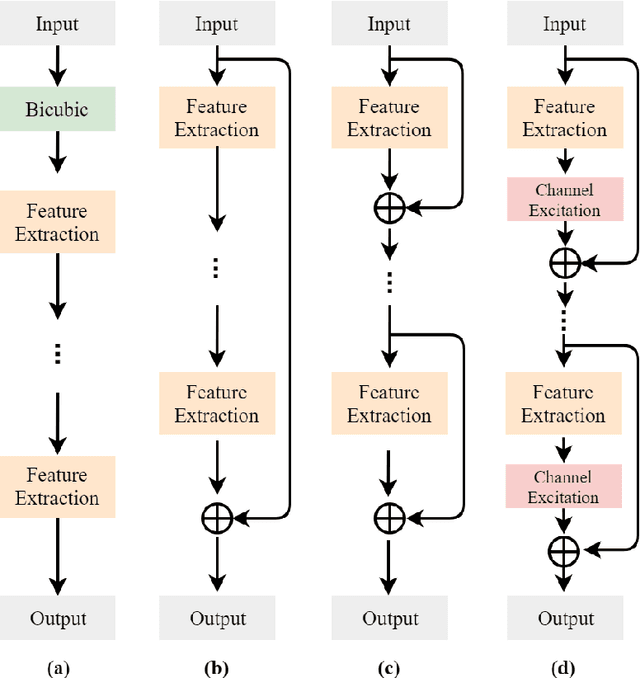
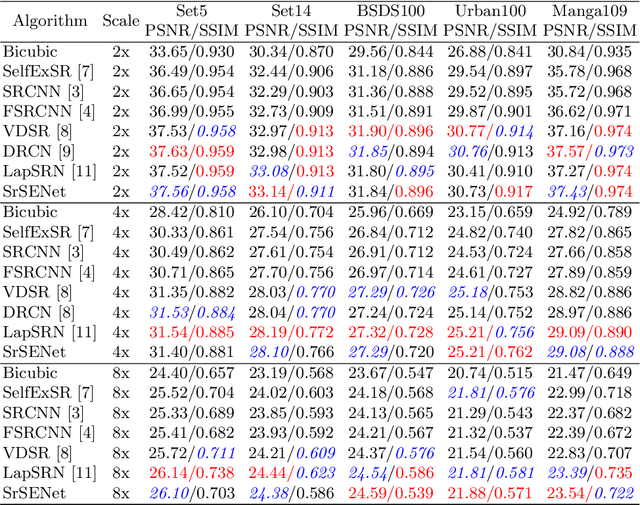
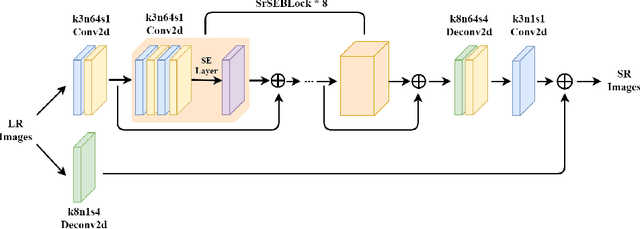

Recent works on single-image super-resolution are concentrated on improving performance through enhancing spatial encoding between convolutional layers. In this paper, we focus on modeling the correlations between channels of convolutional features. We present an effective deep residual network based on squeeze-and-excitation blocks (SEBlock) to reconstruct high-resolution (HR) image from low-resolution (LR) image. SEBlock is used to adaptively recalibrate channel-wise feature mappings. Further, short connections between each SEBlock are used to remedy information loss. Extensive experiments show that our model can achieve the state-of-the-art performance and get finer texture details.