 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-dimensional Visual Prompt Enhanced Image Restoration via Mamba-Transformer Aggregation
Dec 20, 2024



Recent efforts on image restoration have focused on developing "all-in-one" models that can handle different degradation types and levels within single model. However, most of mainstream Transformer-based ones confronted with dilemma between model capabilities and computation burdens, since self-attention mechanism quadratically increase in computational complexity with respect to image size, and has inadequacies in capturing long-range dependencies. Most of Mamba-related ones solely scanned feature map in spatial dimension for global modeling, failing to fully utilize information in channel dimension. To address aforementioned problems, this paper has proposed to fully utilize complementary advantages from Mamba and Transformer without sacrificing computation efficiency. Specifically, the selective scanning mechanism of Mamba is employed to focus on spatial modeling, enabling capture long-range spatial dependencies under linear complexity. The self-attention mechanism of Transformer is applied to focus on channel modeling, avoiding high computation burdens that are in quadratic growth with image's spatial dimensions. Moreover, to enrich informative prompts for effective image restoration, multi-dimensional prompt learning modules are proposed to learn prompt-flows from multi-scale encoder/decoder layers, benefiting for revealing underlying characteristic of various degradations from both spatial and channel perspectives, therefore, enhancing the capabilities of "all-in-one" model to solve various restoration tasks. Extensive experiment results on several image restoration benchmark tasks such as image denoising, dehazing, and deraining, have demonstrated that the proposed method can achieve new state-of-the-art performance, compared with many popular mainstream methods. Related source codes and pre-trained parameters will be public on github https://github.com/12138-chr/MTAIR.
An Effective Single-Image Super-Resolution Model Using Squeeze-and-Excitation Networks
Oct 03, 2018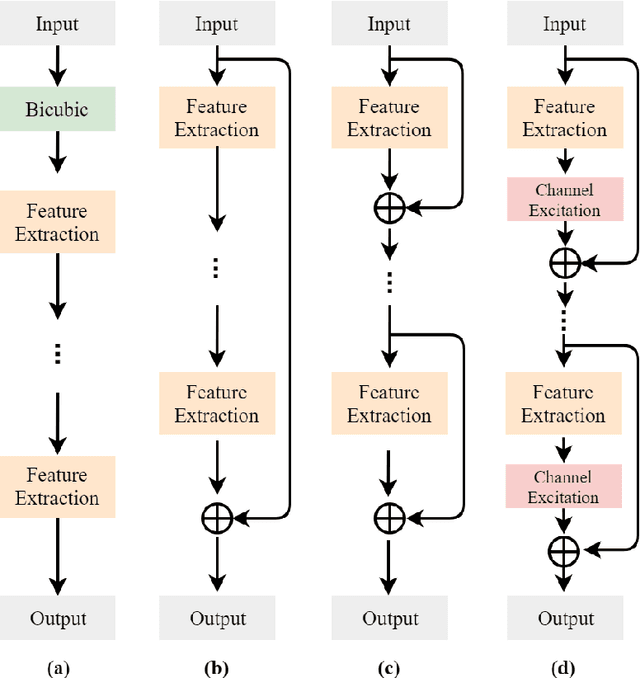
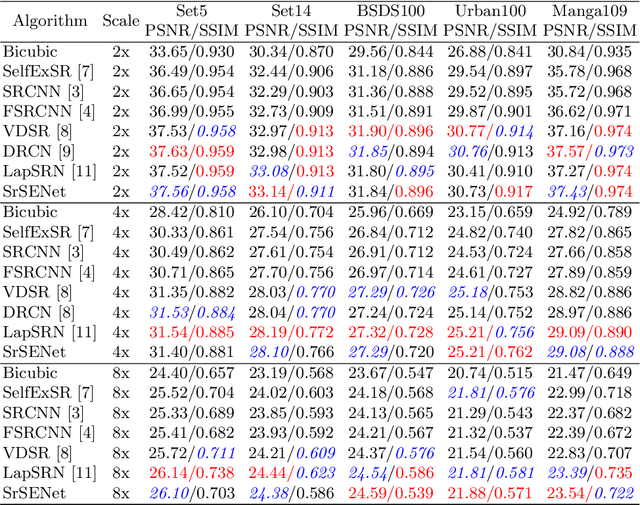
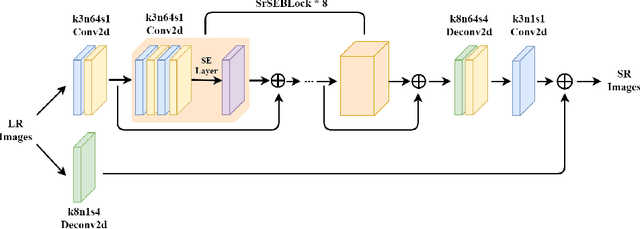

Recent works on single-image super-resolution are concentrated on improving performance through enhancing spatial encoding between convolutional layers. In this paper, we focus on modeling the correlations between channels of convolutional features. We present an effective deep residual network based on squeeze-and-excitation blocks (SEBlock) to reconstruct high-resolution (HR) image from low-resolution (LR) image. SEBlock is used to adaptively recalibrate channel-wise feature mappings. Further, short connections between each SEBlock are used to remedy information loss. Extensive experiments show that our model can achieve the state-of-the-art performance and get finer texture details.