 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHera: Learning Long-Horizon Coordination for Device-Cloud Collaborative LLM Agents
May 23, 2026Large language model (LLM) agents excel at solving complex long-horizon tasks through autonomous interaction with environments. However, their real-world deployment faces a fundamental device--cloud dilemma: on-device models are efficient but often brittle, while cloud models are stronger but costly in computation. State-of-the-art LLM device--cloud routers usually make coarse task-level decisions, which cannot adapt to the changing difficulty of multi-step agent interactions. To address this issue, we present Hera, a step-level device--cloud LLM agent coordinator for long-horizon tasks achieving a strong performance--cost Pareto frontier. Hera adopts a novel two-stage training paradigm: (1) imitation learning for cold-start, followed by (2) reinforcement learning that jointly optimizes task success and cloud usage efficiency. The first stage casts step-level routing as a supervised classification problem: the device agent is replayed on cloud trajectories, with each state labeled by the agreement between device and cloud actions. In the second stage, we perform cost-aware reinforcement learning by grouping identical states across trajectories and updating Hera with labels favoring higher expected return and fewer future cloud calls. We evaluate Hera on ALFWorld, WebShop, and AppWorld, where it consistently outperforms prior methods, achieving 92.5% of the cloud-only success rate with cloud use in only 46.3% of steps.
FHAvatar: Fast and High-Fidelity Reconstruction of Face-and-Hair Composable 3D Head Avatar from Few Casual Captures
Mar 24, 2026We present FHAvatar, a novel framework for reconstructing 3D Gaussian avatars with composable face and hair components from an arbitrary number of views. Unlike previous approaches that couple facial and hair representations within a unified modeling process, we explicitly decouple two components in texture space by representing the face with planar Gaussians and the hair with strand-based Gaussians. To overcome the limitations of existing methods that rely on dense multi-view captures or costly per-identity optimization, we propose an aggregated transformer backbone to learn geometry-aware cross-view priors and head-hair structural coherence from multi-view datasets, enabling effective and efficient feature extraction and fusion from few casual captures. Extensive quantitative and qualitative experiments demonstrate that FHAvatar achieves state-of-the-art reconstruction quality from only a few observations of new identities within minutes, while supporting real-time animation, convenient hairstyle transfer, and stylized editing, broadening the accessibility and applicability of digital avatar creation.
Scaling Dense Event-Stream Pretraining from Visual Foundation Models
Mar 04, 2026Learning versatile, fine-grained representations from irregular event streams is pivotal yet nontrivial, primarily due to the heavy annotation that hinders scalability in dataset size, semantic richness, and application scope. To mitigate this dilemma, we launch a novel self-supervised pretraining method that distills visual foundation models (VFMs) to push the boundaries of event representation at scale. Specifically, we curate an extensive synchronized image-event collection to amplify cross-modal alignment. Nevertheless, due to inherent mismatches in sparsity and granularity between image-event domains, existing distillation paradigms are prone to semantic collapse in event representations, particularly at high resolutions. To bridge this gap, we propose to extend the alignment objective to semantic structures provided off-the-shelf by VFMs, indicating a broader receptive field and stronger supervision. The key ingredient of our method is a structure-aware distillation loss that grounds higher-quality image-event correspondences for alignment, optimizing dense event representations. Extensive experiments demonstrate that our approach takes a great leap in downstream benchmarks, significantly surpassing traditional methods and existing pretraining techniques. This breakthrough manifests in enhanced generalization, superior data efficiency and elevated transferability.
Optimizing Multi-Modal Trackers via Sensitivity-aware Regularized Tuning
Aug 24, 2025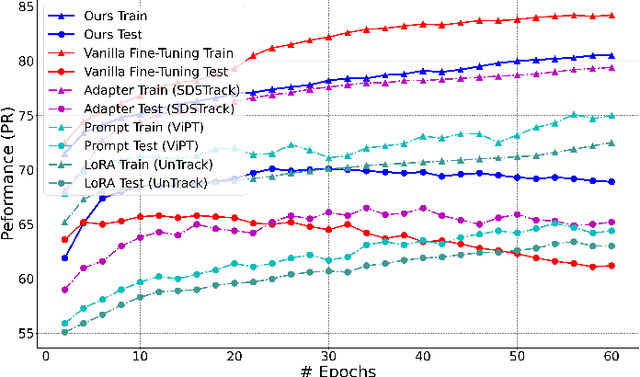

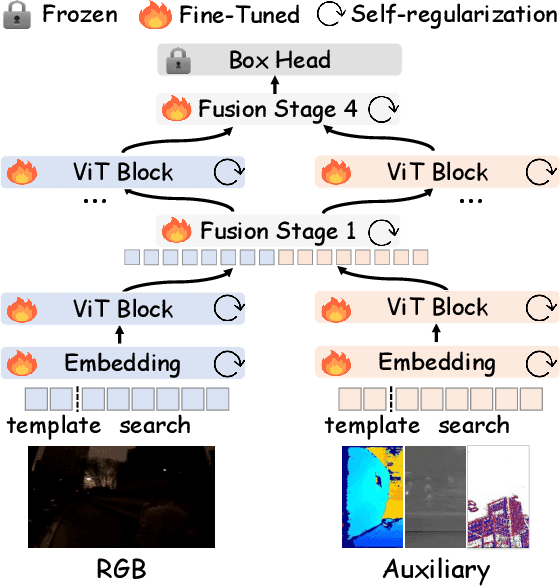
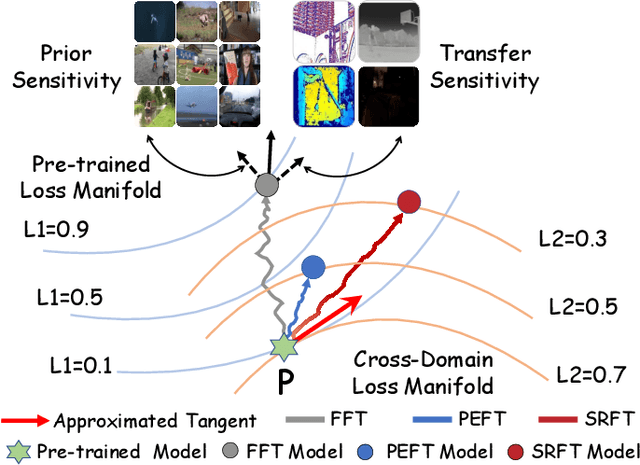
This paper tackles the critical challenge of optimizing multi-modal trackers by effectively adapting the pre-trained models for RGB data. Existing fine-tuning paradigms oscillate between excessive freedom and over-restriction, both leading to a suboptimal plasticity-stability trade-off. To mitigate this dilemma, we propose a novel sensitivity-aware regularized tuning framework, which delicately refines the learning process by incorporating intrinsic parameter sensitivities. Through a comprehensive investigation from pre-trained to multi-modal contexts, we identify that parameters sensitive to pivotal foundational patterns and cross-domain shifts are primary drivers of this issue. Specifically, we first analyze the tangent space of pre-trained weights to measure and orient prior sensitivities, dedicated to preserving generalization. Then, we further explore transfer sensitivities during the tuning phase, emphasizing adaptability and stability. By incorporating these sensitivities as regularization terms, our method significantly enhances the transferability across modalities. Extensive experiments showcase the superior performance of the proposed method, surpassing current state-of-the-art techniques across various multi-modal tracking. The source code and models will be publicly available at https://github.com/zhiwen-xdu/SRTrack.
HCRMP: A LLM-Hinted Contextual Reinforcement Learning Framework for Autonomous Driving
May 21, 2025



Integrating Large Language Models (LLMs) with Reinforcement Learning (RL) can enhance autonomous driving (AD) performance in complex scenarios. However, current LLM-Dominated RL methods over-rely on LLM outputs, which are prone to hallucinations.Evaluations show that state-of-the-art LLM indicates a non-hallucination rate of only approximately 57.95% when assessed on essential driving-related tasks. Thus, in these methods, hallucinations from the LLM can directly jeopardize the performance of driving policies. This paper argues that maintaining relative independence between the LLM and the RL is vital for solving the hallucinations problem. Consequently, this paper is devoted to propose a novel LLM-Hinted RL paradigm. The LLM is used to generate semantic hints for state augmentation and policy optimization to assist RL agent in motion planning, while the RL agent counteracts potential erroneous semantic indications through policy learning to achieve excellent driving performance. Based on this paradigm, we propose the HCRMP (LLM-Hinted Contextual Reinforcement Learning Motion Planner) architecture, which is designed that includes Augmented Semantic Representation Module to extend state space. Contextual Stability Anchor Module enhances the reliability of multi-critic weight hints by utilizing information from the knowledge base. Semantic Cache Module is employed to seamlessly integrate LLM low-frequency guidance with RL high-frequency control. Extensive experiments in CARLA validate HCRMP's strong overall driving performance. HCRMP achieves a task success rate of up to 80.3% under diverse driving conditions with different traffic densities. Under safety-critical driving conditions, HCRMP significantly reduces the collision rate by 11.4%, which effectively improves the driving performance in complex scenarios.
A Survey of Reinforcement Learning-Based Motion Planning for Autonomous Driving: Lessons Learned from a Driving Task Perspective
Mar 31, 2025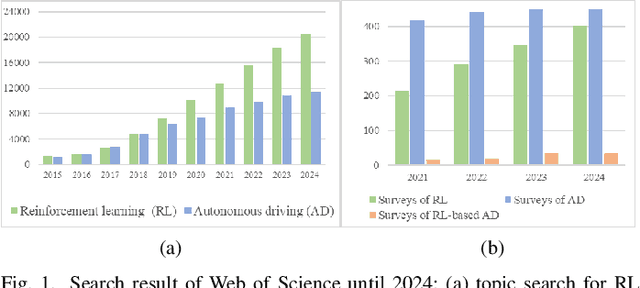
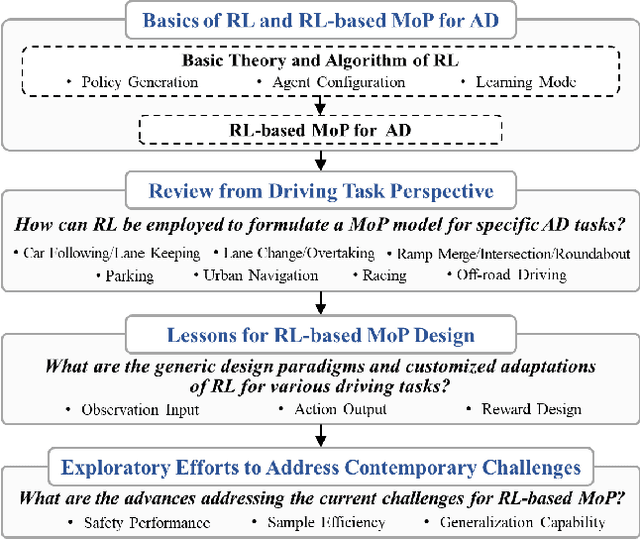
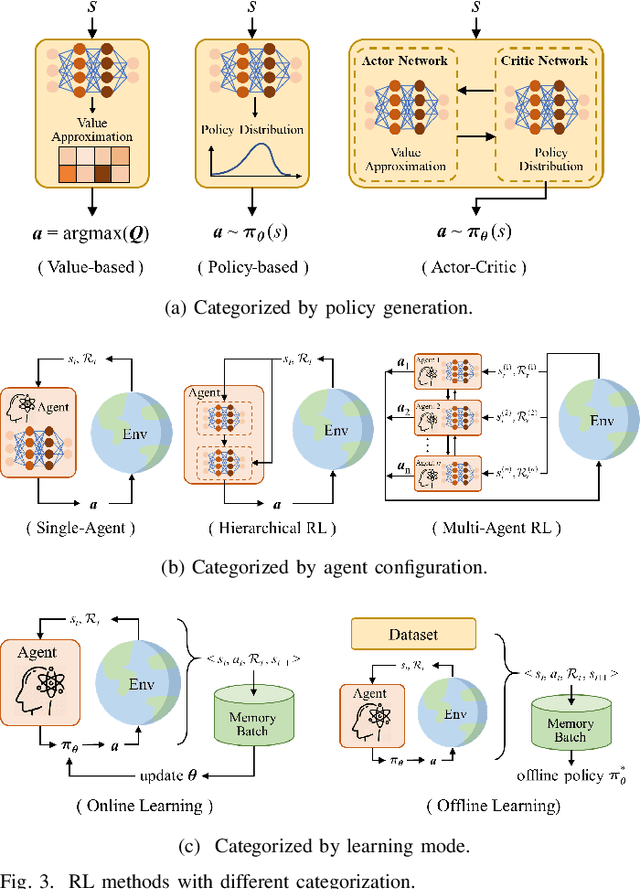
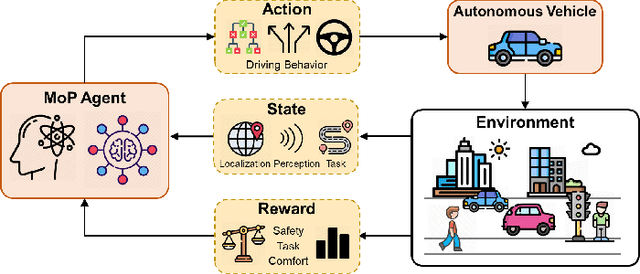
Reinforcement learning (RL), with its ability to explore and optimize policies in complex, dynamic decision-making tasks, has emerged as a promising approach to addressing motion planning (MoP) challenges in autonomous driving (AD). Despite rapid advancements in RL and AD, a systematic description and interpretation of the RL design process tailored to diverse driving tasks remains underdeveloped. This survey provides a comprehensive review of RL-based MoP for AD, focusing on lessons from task-specific perspectives. We first outline the fundamentals of RL methodologies, and then survey their applications in MoP, analyzing scenario-specific features and task requirements to shed light on their influence on RL design choices. Building on this analysis, we summarize key design experiences, extract insights from various driving task applications, and provide guidance for future implementations. Additionally, we examine the frontier challenges in RL-based MoP, review recent efforts to addresse these challenges, and propose strategies for overcoming unresolved issues.
Multi-dimensional Visual Prompt Enhanced Image Restoration via Mamba-Transformer Aggregation
Dec 20, 2024



Recent efforts on image restoration have focused on developing "all-in-one" models that can handle different degradation types and levels within single model. However, most of mainstream Transformer-based ones confronted with dilemma between model capabilities and computation burdens, since self-attention mechanism quadratically increase in computational complexity with respect to image size, and has inadequacies in capturing long-range dependencies. Most of Mamba-related ones solely scanned feature map in spatial dimension for global modeling, failing to fully utilize information in channel dimension. To address aforementioned problems, this paper has proposed to fully utilize complementary advantages from Mamba and Transformer without sacrificing computation efficiency. Specifically, the selective scanning mechanism of Mamba is employed to focus on spatial modeling, enabling capture long-range spatial dependencies under linear complexity. The self-attention mechanism of Transformer is applied to focus on channel modeling, avoiding high computation burdens that are in quadratic growth with image's spatial dimensions. Moreover, to enrich informative prompts for effective image restoration, multi-dimensional prompt learning modules are proposed to learn prompt-flows from multi-scale encoder/decoder layers, benefiting for revealing underlying characteristic of various degradations from both spatial and channel perspectives, therefore, enhancing the capabilities of "all-in-one" model to solve various restoration tasks. Extensive experiment results on several image restoration benchmark tasks such as image denoising, dehazing, and deraining, have demonstrated that the proposed method can achieve new state-of-the-art performance, compared with many popular mainstream methods. Related source codes and pre-trained parameters will be public on github https://github.com/12138-chr/MTAIR.
Canonical Correlation Guided Deep Neural Network
Sep 28, 2024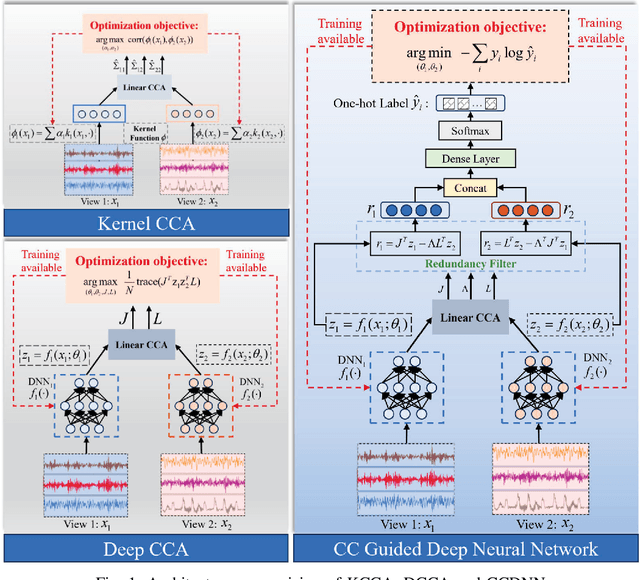
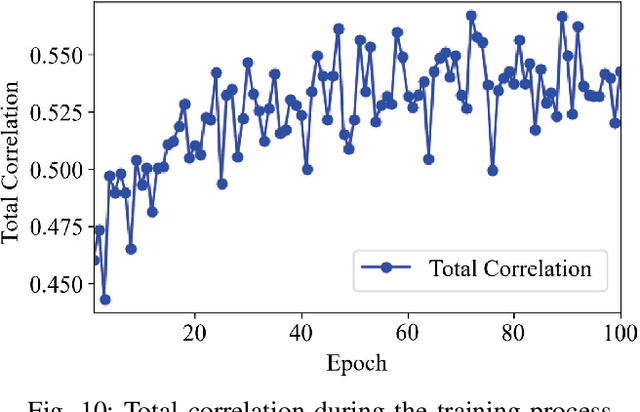
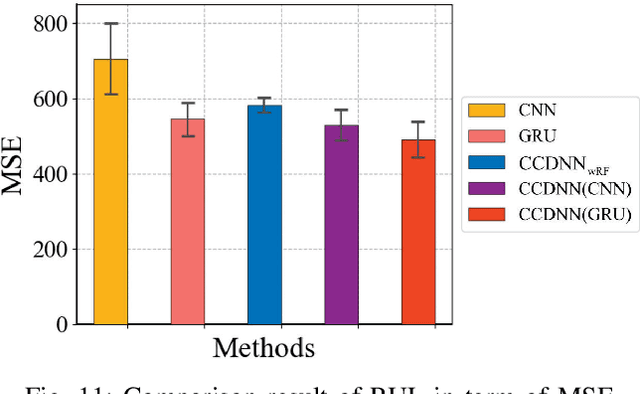
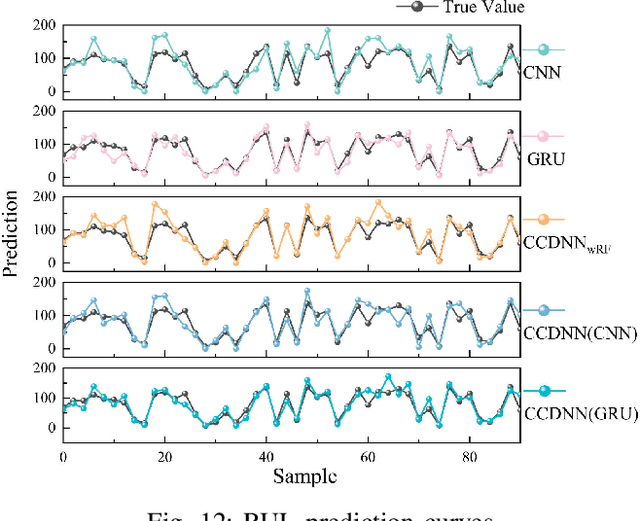
Learning representations of two views of data such that the resulting representations are highly linearly correlated is appealing in machine learning. In this paper, we present a canonical correlation guided learning framework, which allows to be realized by deep neural networks (CCDNN), to learn such a correlated representation. It is also a novel merging of multivariate analysis (MVA) and machine learning, which can be viewed as transforming MVA into end-to-end architectures with the aid of neural networks. Unlike the linear canonical correlation analysis (CCA), kernel CCA and deep CCA, in the proposed method, the optimization formulation is not restricted to maximize correlation, instead we make canonical correlation as a constraint, which preserves the correlated representation learning ability and focuses more on the engineering tasks endowed by optimization formulation, such as reconstruction, classification and prediction. Furthermore, to reduce the redundancy induced by correlation, a redundancy filter is designed. We illustrate the performance of CCDNN on various tasks. In experiments on MNIST dataset, the results show that CCDNN has better reconstruction performance in terms of mean squared error and mean absolute error than DCCA and DCCAE. Also, we present the application of the proposed network to industrial fault diagnosis and remaining useful life cases for the classification and prediction tasks accordingly. The proposed method demonstrates superior performance in both tasks when compared to existing methods. Extension of CCDNN to much more deeper with the aid of residual connection is also presented in appendix.
GaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting
Apr 28, 2024



Recent works on audio-driven talking head synthesis using Neural Radiance Fields (NeRF) have achieved impressive results. However, due to inadequate pose and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. Dynamic Gaussian Renderer introduces Speaker-specific BlendShapes to enhance facial detail representation via a latent pose, delivering stable and realistic rendered videos. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.
Segment Any Events via Weighted Adaptation of Pivotal Tokens
Dec 24, 2023In this paper, we delve into the nuanced challenge of tailoring the Segment Anything Models (SAMs) for integration with event data, with the overarching objective of attaining robust and universal object segmentation within the event-centric domain. One pivotal issue at the heart of this endeavor is the precise alignment and calibration of embeddings derived from event-centric data such that they harmoniously coincide with those originating from RGB imagery. Capitalizing on the vast repositories of datasets with paired events and RGB images, our proposition is to harness and extrapolate the profound knowledge encapsulated within the pre-trained SAM framework. As a cornerstone to achieving this, we introduce a multi-scale feature distillation methodology. This methodology rigorously optimizes the alignment of token embeddings originating from event data with their RGB image counterparts, thereby preserving and enhancing the robustness of the overall architecture. Considering the distinct significance that token embeddings from intermediate layers hold for higher-level embeddings, our strategy is centered on accurately calibrating the pivotal token embeddings. This targeted calibration is aimed at effectively managing the discrepancies in high-level embeddings originating from both the event and image domains. Extensive experiments on different datasets demonstrate the effectiveness of the proposed distillation method. Code in http://github.com/happychenpipi/EventSAM.