 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianTalker: Speaker-specific Talking Head Synthesis via 3D Gaussian Splatting
Apr 28, 2024



Recent works on audio-driven talking head synthesis using Neural Radiance Fields (NeRF) have achieved impressive results. However, due to inadequate pose and expression control caused by NeRF implicit representation, these methods still have some limitations, such as unsynchronized or unnatural lip movements, and visual jitter and artifacts. In this paper, we propose GaussianTalker, a novel method for audio-driven talking head synthesis based on 3D Gaussian Splatting. With the explicit representation property of 3D Gaussians, intuitive control of the facial motion is achieved by binding Gaussians to 3D facial models. GaussianTalker consists of two modules, Speaker-specific Motion Translator and Dynamic Gaussian Renderer. Speaker-specific Motion Translator achieves accurate lip movements specific to the target speaker through universalized audio feature extraction and customized lip motion generation. Dynamic Gaussian Renderer introduces Speaker-specific BlendShapes to enhance facial detail representation via a latent pose, delivering stable and realistic rendered videos. Extensive experimental results suggest that GaussianTalker outperforms existing state-of-the-art methods in talking head synthesis, delivering precise lip synchronization and exceptional visual quality. Our method achieves rendering speeds of 130 FPS on NVIDIA RTX4090 GPU, significantly exceeding the threshold for real-time rendering performance, and can potentially be deployed on other hardware platforms.
GM-NeRF: Learning Generalizable Model-based Neural Radiance Fields from Multi-view Images
Mar 24, 2023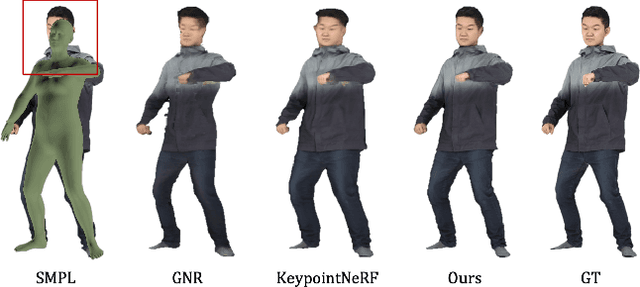

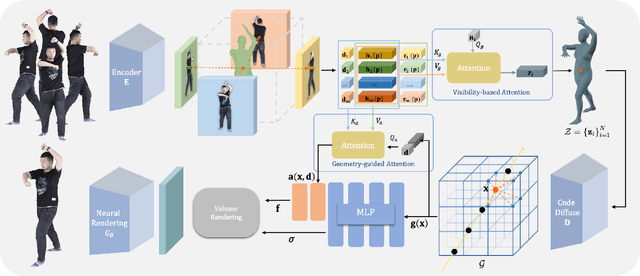

In this work, we focus on synthesizing high-fidelity novel view images for arbitrary human performers, given a set of sparse multi-view images. It is a challenging task due to the large variation among articulated body poses and heavy self-occlusions. To alleviate this, we introduce an effective generalizable framework Generalizable Model-based Neural Radiance Fields (GM-NeRF) to synthesize free-viewpoint images. Specifically, we propose a geometry-guided attention mechanism to register the appearance code from multi-view 2D images to a geometry proxy which can alleviate the misalignment between inaccurate geometry prior and pixel space. On top of that, we further conduct neural rendering and partial gradient backpropagation for efficient perceptual supervision and improvement of the perceptual quality of synthesis. To evaluate our method, we conduct experiments on synthesized datasets THuman2.0 and Multi-garment, and real-world datasets Genebody and ZJUMocap. The results demonstrate that our approach outperforms state-of-the-art methods in terms of novel view synthesis and geometric reconstruction.
Pixel2ISDF: Implicit Signed Distance Fields based Human Body Model from Multi-view and Multi-pose Images
Dec 06, 2022In this report, we focus on reconstructing clothed humans in the canonical space given multiple views and poses of a human as the input. To achieve this, we utilize the geometric prior of the SMPLX model in the canonical space to learn the implicit representation for geometry reconstruction. Based on the observation that the topology between the posed mesh and the mesh in the canonical space are consistent, we propose to learn latent codes on the posed mesh by leveraging multiple input images and then assign the latent codes to the mesh in the canonical space. Specifically, we first leverage normal and geometry networks to extract the feature vector for each vertex on the SMPLX mesh. Normal maps are adopted for better generalization to unseen images compared to 2D images. Then, features for each vertex on the posed mesh from multiple images are integrated by MLPs. The integrated features acting as the latent code are anchored to the SMPLX mesh in the canonical space. Finally, latent code for each 3D point is extracted and utilized to calculate the SDF. Our work for reconstructing the human shape on canonical pose achieves 3rd performance on WCPA MVP-Human Body Challenge.
Animatable Neural Radiance Fields from Monocular RGB Video
Jun 25, 2021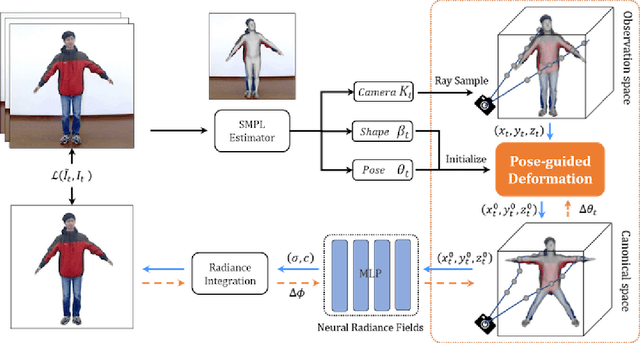
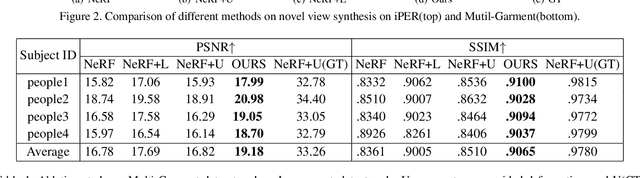


We present animatable neural radiance fields for detailed human avatar creation from monocular videos. Our approach extends neural radiance fields (NeRF) to the dynamic scenes with human movements via introducing explicit pose-guided deformation while learning the scene representation network. In particular, we estimate the human pose for each frame and learn a constant canonical space for the detailed human template, which enables natural shape deformation from the observation space to the canonical space under the explicit control of the pose parameters. To compensate for inaccurate pose estimation, we introduce the pose refinement strategy that updates the initial pose during the learning process, which not only helps to learn more accurate human reconstruction but also accelerates the convergence. In experiments we show that the proposed approach achieves 1) implicit human geometry and appearance reconstruction with high-quality details, 2) photo-realistic rendering of the human from arbitrary views, and 3) animation of the human with arbitrary poses.