 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
WIPES: Wavelet-based Visual Primitives
Aug 18, 2025Pursuing a continuous visual representation that offers flexible frequency modulation and fast rendering speed has recently garnered increasing attention in the fields of 3D vision and graphics. However, existing representations often rely on frequency guidance or complex neural network decoding, leading to spectrum loss or slow rendering. To address these limitations, we propose WIPES, a universal Wavelet-based vIsual PrimitivES for representing multi-dimensional visual signals. Building on the spatial-frequency localization advantages of wavelets, WIPES effectively captures both the low-frequency "forest" and the high-frequency "trees." Additionally, we develop a wavelet-based differentiable rasterizer to achieve fast visual rendering. Experimental results on various visual tasks, including 2D image representation, 5D static and 6D dynamic novel view synthesis, demonstrate that WIPES, as a visual primitive, offers higher rendering quality and faster inference than INR-based methods, and outperforms Gaussian-based representations in rendering quality.
AnchorCrafter: Animate CyberAnchors Saling Your Products via Human-Object Interacting Video Generation
Nov 26, 2024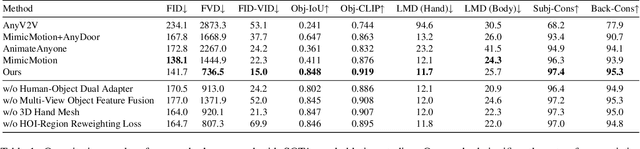

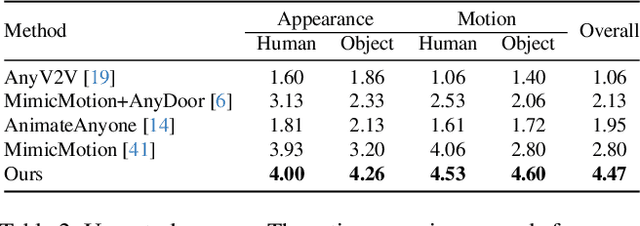
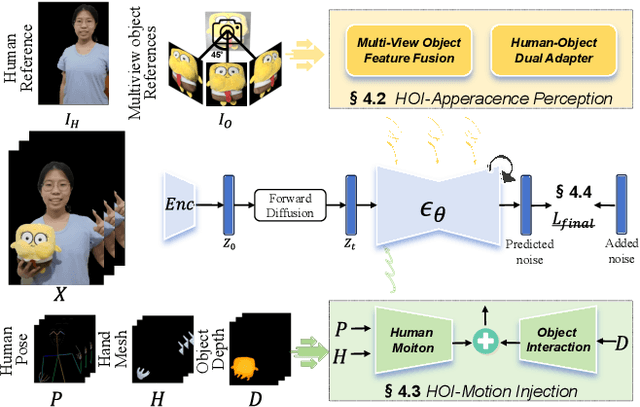
The automatic generation of anchor-style product promotion videos presents promising opportunities in online commerce, advertising, and consumer engagement. However, this remains a challenging task despite significant advancements in pose-guided human video generation. In addressing this challenge, we identify the integration of human-object interactions (HOI) into pose-guided human video generation as a core issue. To this end, we introduce AnchorCrafter, a novel diffusion-based system designed to generate 2D videos featuring a target human and a customized object, achieving high visual fidelity and controllable interactions. Specifically, we propose two key innovations: the HOI-appearance perception, which enhances object appearance recognition from arbitrary multi-view perspectives and disentangles object and human appearance, and the HOI-motion injection, which enables complex human-object interactions by overcoming challenges in object trajectory conditioning and inter-occlusion management. Additionally, we introduce the HOI-region reweighting loss, a training objective that enhances the learning of object details. Extensive experiments demonstrate that our proposed system outperforms existing methods in preserving object appearance and shape awareness, while simultaneously maintaining consistency in human appearance and motion. Project page: https://cangcz.github.io/Anchor-Crafter/
DAGSM: Disentangled Avatar Generation with GS-enhanced Mesh
Nov 20, 2024



Text-driven avatar generation has gained significant attention owing to its convenience. However, existing methods typically model the human body with all garments as a single 3D model, limiting its usability, such as clothing replacement, and reducing user control over the generation process. To overcome the limitations above, we propose DAGSM, a novel pipeline that generates disentangled human bodies and garments from the given text prompts. Specifically, we model each part (e.g., body, upper/lower clothes) of the clothed human as one GS-enhanced mesh (GSM), which is a traditional mesh attached with 2D Gaussians to better handle complicated textures (e.g., woolen, translucent clothes) and produce realistic cloth animations. During the generation, we first create the unclothed body, followed by a sequence of individual cloth generation based on the body, where we introduce a semantic-based algorithm to achieve better human-cloth and garment-garment separation. To improve texture quality, we propose a view-consistent texture refinement module, including a cross-view attention mechanism for texture style consistency and an incident-angle-weighted denoising (IAW-DE) strategy to update the appearance. Extensive experiments have demonstrated that DAGSM generates high-quality disentangled avatars, supports clothing replacement and realistic animation, and outperforms the baselines in visual quality.
MeGA: Hybrid Mesh-Gaussian Head Avatar for High-Fidelity Rendering and Head Editing
Apr 29, 2024Creating high-fidelity head avatars from multi-view videos is a core issue for many AR/VR applications. However, existing methods usually struggle to obtain high-quality renderings for all different head components simultaneously since they use one single representation to model components with drastically different characteristics (e.g., skin vs. hair). In this paper, we propose a Hybrid Mesh-Gaussian Head Avatar (MeGA) that models different head components with more suitable representations. Specifically, we select an enhanced FLAME mesh as our facial representation and predict a UV displacement map to provide per-vertex offsets for improved personalized geometric details. To achieve photorealistic renderings, we obtain facial colors using deferred neural rendering and disentangle neural textures into three meaningful parts. For hair modeling, we first build a static canonical hair using 3D Gaussian Splatting. A rigid transformation and an MLP-based deformation field are further applied to handle complex dynamic expressions. Combined with our occlusion-aware blending, MeGA generates higher-fidelity renderings for the whole head and naturally supports more downstream tasks. Experiments on the NeRSemble dataset demonstrate the effectiveness of our designs, outperforming previous state-of-the-art methods and supporting various editing functionalities, including hairstyle alteration and texture editing.
Neural Point-based Volumetric Avatar: Surface-guided Neural Points for Efficient and Photorealistic Volumetric Head Avatar
Jul 11, 2023



Rendering photorealistic and dynamically moving human heads is crucial for ensuring a pleasant and immersive experience in AR/VR and video conferencing applications. However, existing methods often struggle to model challenging facial regions (e.g., mouth interior, eyes, hair/beard), resulting in unrealistic and blurry results. In this paper, we propose {\fullname} ({\name}), a method that adopts the neural point representation as well as the neural volume rendering process and discards the predefined connectivity and hard correspondence imposed by mesh-based approaches. Specifically, the neural points are strategically constrained around the surface of the target expression via a high-resolution UV displacement map, achieving increased modeling capacity and more accurate control. We introduce three technical innovations to improve the rendering and training efficiency: a patch-wise depth-guided (shading point) sampling strategy, a lightweight radiance decoding process, and a Grid-Error-Patch (GEP) ray sampling strategy during training. By design, our {\name} is better equipped to handle topologically changing regions and thin structures while also ensuring accurate expression control when animating avatars. Experiments conducted on three subjects from the Multiface dataset demonstrate the effectiveness of our designs, outperforming previous state-of-the-art methods, especially in handling challenging facial regions.
Skinned Motion Retargeting with Residual Perception of Motion Semantics & Geometry
Mar 15, 2023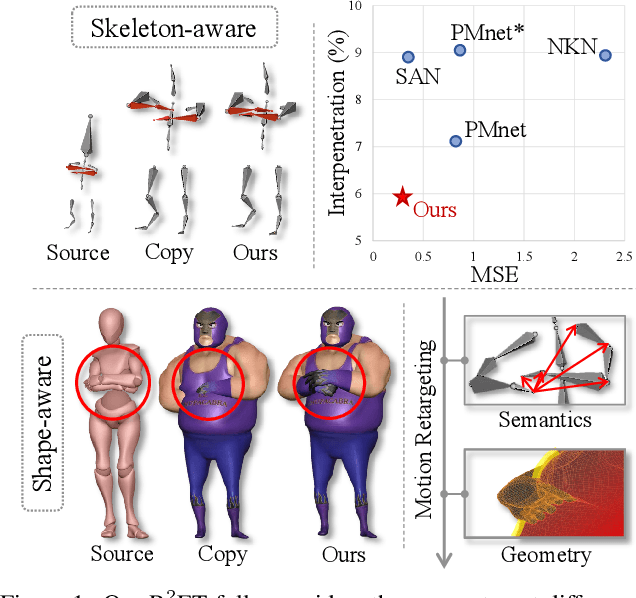
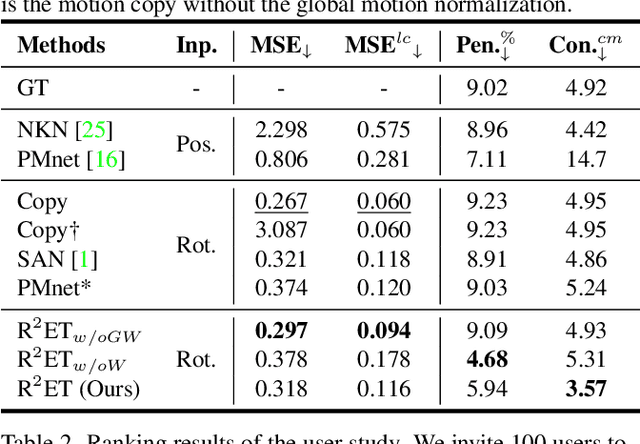
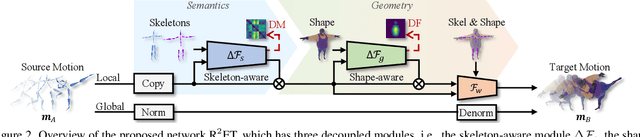
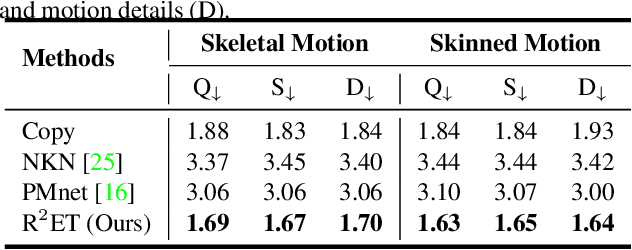
A good motion retargeting cannot be reached without reasonable consideration of source-target differences on both the skeleton and shape geometry levels. In this work, we propose a novel Residual RETargeting network (R2ET) structure, which relies on two neural modification modules, to adjust the source motions to fit the target skeletons and shapes progressively. In particular, a skeleton-aware module is introduced to preserve the source motion semantics. A shape-aware module is designed to perceive the geometries of target characters to reduce interpenetration and contact-missing. Driven by our explored distance-based losses that explicitly model the motion semantics and geometry, these two modules can learn residual motion modifications on the source motion to generate plausible retargeted motion in a single inference without post-processing. To balance these two modifications, we further present a balancing gate to conduct linear interpolation between them. Extensive experiments on the public dataset Mixamo demonstrate that our R2ET achieves the state-of-the-art performance, and provides a good balance between the preservation of motion semantics as well as the attenuation of interpenetration and contact-missing. Code is available at https://github.com/Kebii/R2ET.
Get3DHuman: Lifting StyleGAN-Human into a 3D Generative Model using Pixel-aligned Reconstruction Priors
Feb 11, 2023Fast generation of high-quality 3D digital humans is important to a vast number of applications ranging from entertainment to professional concerns. Recent advances in differentiable rendering have enabled the training of 3D generative models without requiring 3D ground truths. However, the quality of the generated 3D humans still has much room to improve in terms of both fidelity and diversity. In this paper, we present Get3DHuman, a novel 3D human framework that can significantly boost the realism and diversity of the generated outcomes by only using a limited budget of 3D ground-truth data. Our key observation is that the 3D generator can profit from human-related priors learned through 2D human generators and 3D reconstructors. Specifically, we bridge the latent space of Get3DHuman with that of StyleGAN-Human via a specially-designed prior network, where the input latent code is mapped to the shape and texture feature volumes spanned by the pixel-aligned 3D reconstructor. The outcomes of the prior network are then leveraged as the supervisory signals for the main generator network. To ensure effective training, we further propose three tailored losses applied to the generated feature volumes and the intermediate feature maps. Extensive experiments demonstrate that Get3DHuman greatly outperforms the other state-of-the-art approaches and can support a wide range of applications including shape interpolation, shape re-texturing, and single-view reconstruction through latent inversion.
Audio2Gestures: Generating Diverse Gestures from Audio
Jan 17, 2023

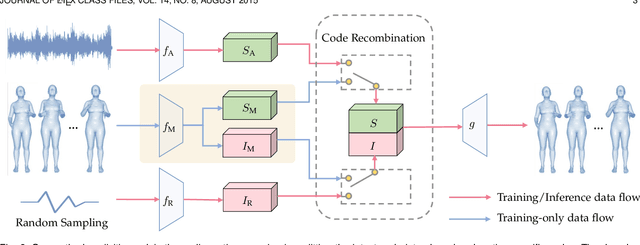

People may perform diverse gestures affected by various mental and physical factors when speaking the same sentences. This inherent one-to-many relationship makes co-speech gesture generation from audio particularly challenging. Conventional CNNs/RNNs assume one-to-one mapping, and thus tend to predict the average of all possible target motions, easily resulting in plain/boring motions during inference. So we propose to explicitly model the one-to-many audio-to-motion mapping by splitting the cross-modal latent code into shared code and motion-specific code. The shared code is expected to be responsible for the motion component that is more correlated to the audio while the motion-specific code is expected to capture diverse motion information that is more independent of the audio. However, splitting the latent code into two parts poses extra training difficulties. Several crucial training losses/strategies, including relaxed motion loss, bicycle constraint, and diversity loss, are designed to better train the VAE. Experiments on both 3D and 2D motion datasets verify that our method generates more realistic and diverse motions than previous state-of-the-art methods, quantitatively and qualitatively. Besides, our formulation is compatible with discrete cosine transformation (DCT) modeling and other popular backbones (\textit{i.e.} RNN, Transformer). As for motion losses and quantitative motion evaluation, we find structured losses/metrics (\textit{e.g.} STFT) that consider temporal and/or spatial context complement the most commonly used point-wise losses (\textit{e.g.} PCK), resulting in better motion dynamics and more nuanced motion details. Finally, we demonstrate that our method can be readily used to generate motion sequences with user-specified motion clips on the timeline.
Learning Audio-Driven Viseme Dynamics for 3D Face Animation
Jan 15, 2023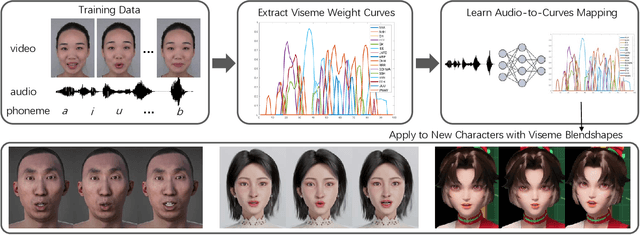
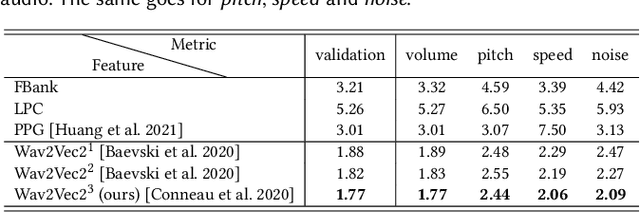
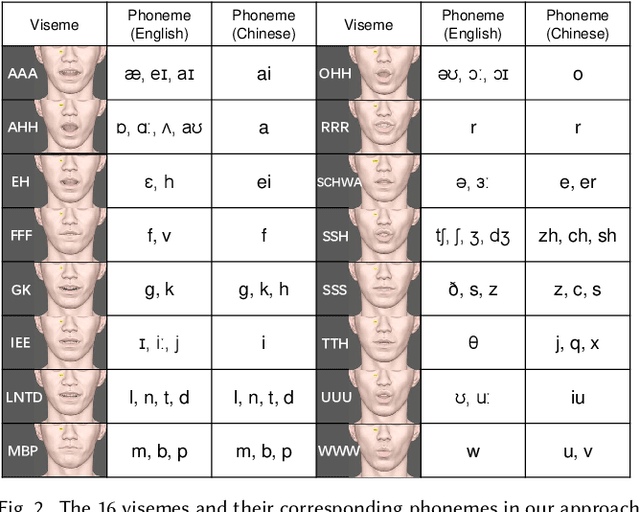
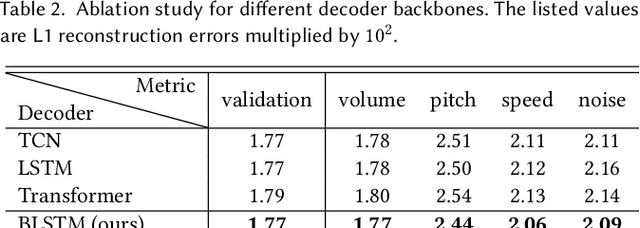
We present a novel audio-driven facial animation approach that can generate realistic lip-synchronized 3D facial animations from the input audio. Our approach learns viseme dynamics from speech videos, produces animator-friendly viseme curves, and supports multilingual speech inputs. The core of our approach is a novel parametric viseme fitting algorithm that utilizes phoneme priors to extract viseme parameters from speech videos. With the guidance of phonemes, the extracted viseme curves can better correlate with phonemes, thus more controllable and friendly to animators. To support multilingual speech inputs and generalizability to unseen voices, we take advantage of deep audio feature models pretrained on multiple languages to learn the mapping from audio to viseme curves. Our audio-to-curves mapping achieves state-of-the-art performance even when the input audio suffers from distortions of volume, pitch, speed, or noise. Lastly, a viseme scanning approach for acquiring high-fidelity viseme assets is presented for efficient speech animation production. We show that the predicted viseme curves can be applied to different viseme-rigged characters to yield various personalized animations with realistic and natural facial motions. Our approach is artist-friendly and can be easily integrated into typical animation production workflows including blendshape or bone based animation.